企業がLLMを選ぶときの基準|GPT-5/Claude/Gemini/MoEモデルをコスト・精度・セキュリティで比較する導入判断ガイド【2026年版】
企業がLLMを選ぶ基準は、コスト(MoE採用の有無)・精度(推論モデルが必要な業務か)・セキュリティ(法人向けプランと入力データの扱い)の3軸です。GPT-5・Claude・Geminiの比較から導入までの実務ステップを解説します。

企業がLLM(大規模言語モデル)を選ぶ基準は、①コスト構造、②精度・推論力、③セキュリティ・データ取り扱いの3軸で比較することです。 GPT-5・Claude Opus 4.7・Gemini 2.5 は同じ「LLM」でも、MoE 採用状況や法人向けプランの学習利用ポリシーが異なり、選定を誤ると想定外のランニングコストやガバナンス上のリスクを抱えることになります。
本記事では、非エンジニアの導入担当者向けに、2026年時点の主要 LLM を実務の判断軸で比較し、自社に合うモデル・プランを選ぶ手順を整理します。
- 企業がLLMを選ぶときに見るべき3つの判断軸
- GPT-5・Claude・Gemini・MoEモデルのコスト構造比較
- 精度で選ぶ場合の基準(推論モデル・MoEの使い分け)
- セキュリティ・データ取り扱いで確認すべきポイント
- 導入までの実務ステップとガバナンス設計
企業がLLMを選ぶときの3つの判断基準
企業が LLM を選ぶときは、コスト・精度・セキュリティの3軸を業務内容に応じて優先順位づけすることが基本です。 どれか1つだけを見て選ぶと、後から「思ったよりコストがかかる」「精度が業務水準に届かない」「機密情報の取り扱いが社内規定に合わない」といったミスマッチが起きます。
| 判断軸 | 確認するポイント |
|---|---|
| コスト | 従量課金の単価、MoE採用による効率化の有無、想定利用量でのランニングコスト |
| 精度・推論力 | 汎用業務で十分か、契約書チェックや数値計算など高難度タスクに推論モデルが必要か |
| セキュリティ | 入力データが学習に使われないか、法人向けプランか、ローカル環境が必要な業界か |
汎用的な文書業務(要約・FAQ 応答・議事録作成)が中心であれば、コスト効率を重視して MoE 採用モデルを選ぶのが定石です。一方、契約書の論理チェックや複雑な数値計算を伴う業務では、精度を最優先して推論モデルを選ぶ判断が必要になります。
コストで選ぶ|MoEモデルが従量課金を半分以下に変えた
2026年時点の主要 LLM のコスト構造を左右しているのが MoE(Mixture of Experts)です。 MoE は巨大モデルを複数の「エキスパート(専門家)」に分割し、入力ごとに必要なエキスパートだけを稼働させる仕組みで、同じ性能でもトークンあたりの計算コストを大幅に下げます。
たとえば Mixtral 8x7B は総パラメータ 470 億のうち、1 トークンあたり 130 億しか使わず、性能は 47B 級・速度は 13B 級という両立を実現しました。2026 年時点では GPT-5、Gemini 2.5、Llama 4 といった最先端モデルが軒並み MoE を採用しており、国内でも 2026 年 4 月に国立情報学研究所が公開した LLM-jp-4 が MoE 構造(128 エキスパート中 8 つを活性化、総 320 億・実効 38 億パラメータ)を採用しています。
| 比較項目 | MoE採用モデル(GPT-5、Gemini 2.5 等) | 非MoE・推論特化モデル(Claude Opus 4.7、o3 等) |
|---|---|---|
| コスト傾向 | トークンあたりの単価が低い | 思考過程を長く展開する分、単価は高め |
| 向いている業務 | 要約・FAQ応答・企画書ドラフトなど汎用業務 | 契約書チェック・数値計算・SQL生成など高難度タスク |
| 選定の考え方 | 利用量が多い業務ほどコスト差が効いてくる | ミスの許容度が低い業務ほど精度を優先 |
MoE の普及により、企業が API 経由で利用できる LLM のコスト構造は、同じ性能でも 2024 年比で半分以下の従量課金になっています。まず自社の利用量を月間トークン数ベースで試算し、汎用業務がボリュームゾーンならコスト効率の高い MoE モデルを軸に選ぶのが実務的な進め方です。
精度で選ぶ|推論モデルが必要になる業務の見極め方
コストだけでなく、**「ミスが許されない高難度タスクがどれだけあるか」**も選定の重要な軸です。
回答を返す前に内部で「思考過程(Chain-of-Thought)」を長く展開してから最終回答を出力する 推論モデル(Reasoning Model) は、数学・コード・論理推論で従来モデルを大きく上回る性能を出します。OpenAI の o3、Anthropic の Claude Opus 4.7、Google の Gemini 2.5 Pro などが該当し、数学オリンピック級の問題(USAMO)で従来 LLM が正答率 10% 程度だったところを 90% 以上に改善した事例も報告されています。
ビジネス現場では、複雑な見積計算・契約書の論理矛盾チェック・SQL/コードの自動生成といった「ミスが許されない高難度タスク」で推論モデルの利用が伸びています。反対に、議事録要約や FAQ 応答のような定型業務にまで推論モデルを使うと、処理時間とコストが不必要に増えるため、業務ごとにモデルを使い分ける設計が現実的です。
使い分けの判断フロー
- 業務の性質を洗い出す:定型的な文書業務か、論理的な正確性が求められる業務かを仕分ける
- 定型業務は MoE 採用モデルを軸に検討:コスト効率を優先し、要約・FAQ・ドラフト作成に充てる
- 高難度タスクは推論モデルを検討:契約書チェック・数値計算・コード生成など、誤りが業務損失に直結する領域に限定して使う
- RAG との併用を検討:LLM 単体では「最新情報・社内固有情報を知らない」弱点があるため、社内ナレッジ検索が必要な業務は RAG(検索拡張生成)と組み合わせる。LLM 単体と RAG の使い分け方は、LLMとRAGの違いを徹底比較で詳しく解説しています
セキュリティで選ぶ|入力データの扱いと法人向けプランの確認
コスト・精度と並んで欠かせないのが、入力したプロンプトや業務データが学習に使われない契約形態かどうかの確認です。
最優先で押さえるべきは、ChatGPT Enterprise、Claude for Work、Google Workspace の Gemini など、法人向けプランを選ぶことです。これらは原則として入力データを学習目的で利用しません。個人向け無料プランのまま業務利用すると、機密情報が学習データに使われる経路が生まれるリスクがあります。サムスン電子は 2023 年に導入わずか 20 日で 3 件の機密流出を起こした事例が知られています(情報漏洩リスク)。
機密性が特に高い業界(金融・医療・防衛)では、自社環境内でモデルを動かす ローカル LLM という選択肢もあります。データを社外に出せない業務はローカル LLM、それ以外は API 経由のクラウド LLM が現実的な判断基準です。クラウド LLM は最新モデルへ常時アクセスでき、ローカル LLM は機密性とランニングコストで優位という違いがあります。導入手順はLLMローカル環境の構築手順を、Claude の法人プラン選定はClaudeの法人契約で失敗しないプラン比較を参照してください。
LLMの基本的な仕組み(選定判断の前提知識)
コスト・精度・セキュリティを比較する前提として、LLM がどう動いているかを簡単に押さえておくと、モデルごとの特性を理解しやすくなります。
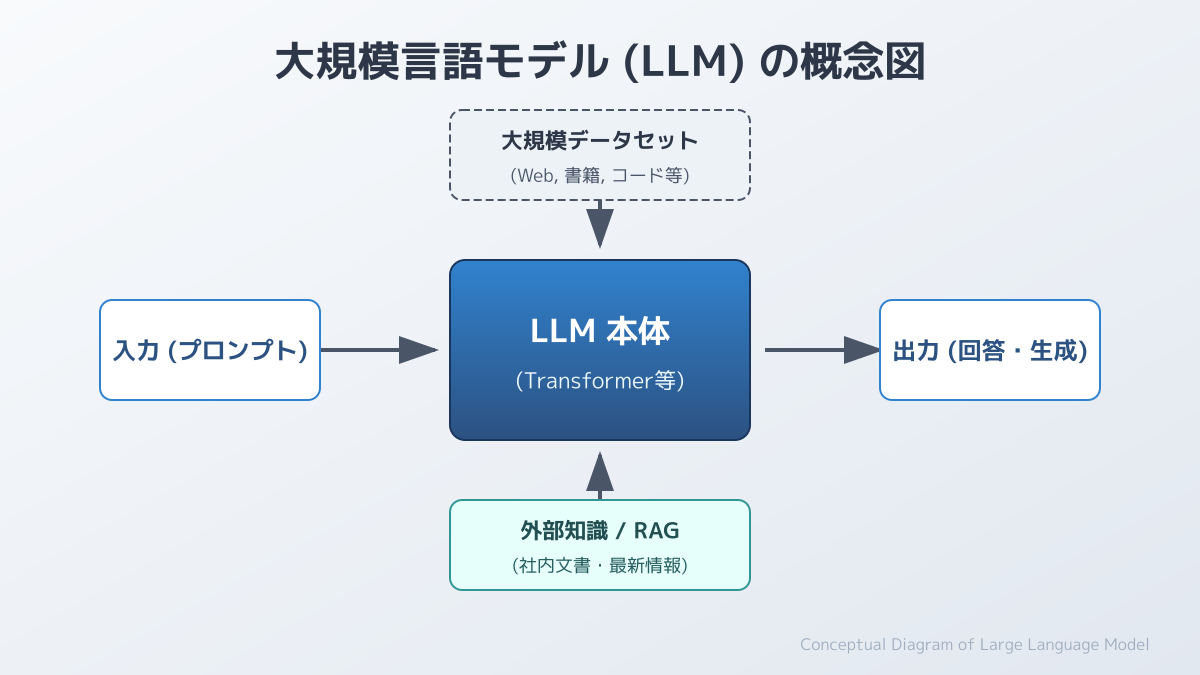
LLM(Large Language Model:大規模言語モデル)とは、膨大なテキストで学習し、文脈に沿った次の単語を高い精度で予測することで自然な文章を生成するニューラルネットワークです。 学習データは数百 GB から数 TB 規模、パラメータ数は数十億から数兆個に達し、この規模が「言語の規則性」を統計的に深く獲得させ、自然な文章生成を可能にしています。
高い文脈理解力は、2017 年に Google が発表した Transformer というニューラルネットワーク構造と、その中核「自己注意機構(Self-Attention)」によって支えられています。自己注意機構は、入力文中の各単語が「他のどの単語にどれだけ注目すべきか」を数値化するもので、従来の RNN や LSTM が単語を順番に 1 つずつ処理していたのに対し、Transformer は文全体を並列処理できます。この並列化により GPU を大量に使えば使うほど学習を高速化できる構造になり、現代の LLM の規模拡大が可能になりました。
なお、LLM と生成 AI は同じものではありません。**LLM が「言語処理の基盤技術」、生成 AI が「LLM や画像/音声モデルを応用したサービス全体」**を指し、LLM が「エンジン」、生成 AI が「車」という関係にあります。ChatGPT や Claude のような対話型サービスは、LLM を会話 UI で包んだ生成 AI の一形態です。LLM が指示を待たずに自律的にタスクを遂行する「AI エージェント」も 2026 年現在は実用段階に入っています。詳しくはAIエージェントとは?生成AIとの決定的な違いを参照してください。
導入までの実務ステップとガバナンス設計
LLM を選定したあと、企業で安全に活用するには、システム選定 × 運用ルール × リテラシー教育の 3 点を同時に整備する必要があります。
運用ルール|利用ガイドラインとリテラシー教育
従業員向けの利用ガイドライン策定が必須です。最低限、以下の項目をカバーします。
- 入力して良い情報のレベル(公開情報のみ/社内秘の取扱/個人情報の禁止)
- ハルシネーションへの対応(必ずファクトチェック、出典確認)
- プロンプトインジェクション(悪意ある入力で AI を誤動作させる攻撃)への基本理解
ガイドラインは作って終わりではなく、四半期ごとに事例を共有して継続的に更新する運用が定着の鍵です。組織全体での体制構築はAIガバナンスとは?企業向けガイドラインと手順を参考にしてください。
コスト感|PoC 段階から本格運用までの目安
コスト面では、PoC(概念実証)が月数十万円規模、全社展開フェーズで月数百万〜数千万円規模が目安です。詳細な内訳と段階別の費用感は生成AI導入費用の相場と内訳にまとめています。
企業における LLM の導入は、2026 年に入って明確な成果フェーズに移行しています。パナソニック コネクトは社内向け生成 AI「ConnectAI」で年間 44.8 万時間の業務削減を公表し、NEC は ChatGPT Enterprise 活用で提案書作成時間を平均 50% 削減しました。一方で、情報漏洩リスク・ハルシネーション・ガバナンス未整備という3つの課題は技術ではなく運用設計で解決する領域です。
よくある質問(FAQ)
Q. 企業がLLMを選ぶとき、最初に確認すべきことは何ですか?
入力データが学習に使われない契約形態(法人向けプラン)かどうかを最初に確認します。そのうえで、業務の利用量からコスト構造(MoE採用の有無)、業務の難易度から精度要件(推論モデルが必要か)を検討する順番が実務的です。
Q. GPT-5、Claude、Geminiはどう使い分ければよいですか?
いずれも MoE を採用しており汎用業務のコスト効率は近い水準にあります。使い分けの決め手は、法人向けプランのセキュリティポリシー、既存の業務システムとの連携のしやすさ、そして契約書チェックや数値計算など高難度タスクへの対応(推論モデルの有無)です。1 モデルに絞らず、業務ごとに使い分ける企業も増えています。
Q. MoEと推論モデルはどう使い分けますか?
MoE は「同じ性能をより低コストで」が狙いです。汎用的な業務(要約・FAQ 応答)は MoE 採用モデルでコスト最適化できます。推論モデルは「複雑な論理タスク」が狙いです。契約書チェック・数学的計算・SQL 自動生成など、ミスが許されない場面で使います。
Q. ローカルLLMと API経由のクラウドLLM、どちらを選ぶべきですか?
データを社外に出せない業務(金融・医療・防衛)はローカル LLM、それ以外は API 経由のクラウド LLM が現実的です。クラウド LLM は最新モデルへ常時アクセスでき、ローカル LLM は機密性とランニングコストで優位です。判断基準はLLMローカル環境の構築手順で解説しています。
Q. LLMとは何ですか?
LLM とは「Large Language Model(大規模言語モデル)」の略で、膨大なテキストデータで学習し「次に来る単語の確率」を予測することで人間のような文章を生成する AI モデルです。GPT-5・Claude Opus 4.7・Gemini 2.5・Llama 4 などが代表例で、ChatGPT や Claude といった対話型サービスの中核技術として使われています。
Q. 企業がLLM導入で最初にやるべきことは何ですか?
3 つ同時に進めるのが定番です。1)入力データを学習に使わない法人プランの契約、2)利用ガイドラインの策定、3)スモールスタートの業務(議事録要約・FAQ 応答など)から効果を計測すること。最初から全社展開せず、1 部門の PoC で ROI を確認してから広げます。
まとめ|LLM選びはコスト・精度・セキュリティの3軸で決める
企業が LLM を選ぶ基準は、コスト(MoE採用による効率化)、精度(推論モデルが必要な業務かどうか)、セキュリティ(入力データの学習利用と法人向けプランの有無)の3軸です。 どれか1つに偏らず、自社の業務内容と利用量に照らして優先順位をつけることが、導入後のミスマッチを防ぎます。
汎用業務にはコスト効率の高い MoE 採用モデル、契約書チェックや数値計算など高難度タスクには推論モデルを使い分けるのが2026年時点の定石です。そのうえで、法人向けプランの選定・利用ガイドラインの策定・スモールスタートでの効果検証を同時に進めることが、導入を成功させる企業に共通する進め方です。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。