「機械学習エンジニアはやめとけ」は本当か?2026年版の年収・求人・生成AI時代の将来性
「機械学習エンジニアはやめとけ」「オワコン」と言われる理由を、2026年5月時点のdoda・レバテック年収相場と生成AI時代の求人需要から検証。年収600〜1,000万円超の実態、LLM/RAG時代に求められるスキル、後悔しない求人選びの判断軸まで具体的に解説します。

「機械学習エンジニアはやめとけ」「もうオワコンでは?」という声を耳にして、キャリアの選択に不安を感じていませんか? 実は、その背景には「理想と現実の業務ギャップ」と「求められるスキルの広範さ」、そして生成AI(LLM)の台頭による役割変化があります。しかし、機械学習エンジニアは2026年現在も企業のDX・生成AI活用において不可欠な存在であり、適切なスキルセットがあれば年収600万円〜1,000万円超の高い市場価値を発揮できます。
本記事では、2026年5月時点の最新ファクト(doda・レバテック等の年収データ、求人動向)に基づき、業務実態・年収相場・生成AI時代の役割変化・後悔しない求人選びまでを具体的に解説します。読み終えるころには、「やめとけ」「オワコン」という声に振り回されず、自分にとって後悔しないキャリアの軸を持てるようになります。
なお、機械学習そのものの基礎から学びたい場合は 【初心者向け】機械学習とは?AI・ディープラーニングの違いとビジネス導入6つの成功戦略、実装で使うアルゴリズムの種類とPython手順は 【2026年版】機械学習モデルとは?種類一覧とPython実装で失敗しない5つの手順 も合わせて参照してください。
「やめとけ」「オワコン」と言われる理由と業務のギャップ
「機械学習エンジニアはやめとけ」「もはやオワコン」という声がSNSや業界内で挙がる最大の理由は、理想と現実の業務内容に大きなギャップが存在するためです。多くの人が「最先端のAIモデルを開発する華やかな仕事」をイメージしますが、実際の業務は想像以上に多岐にわたります。
モデル構築だけではない業務の実態
機械学習エンジニアの基本事項として押さえておくべきは、アルゴリズムの選定やモデルの学習作業は全体の業務の2割程度に過ぎないという事実です。残りの8割は、データの収集、欠損値の補完やノイズ除去といったクレンジング(前処理)、そして本番環境へのデプロイやインフラ構築といった泥臭いエンジニアリング作業が占めています。
純粋なデータサイエンスの知識だけでなく、ソフトウェアエンジニアリングの実装力が強く求められます。研究開発の延長で入社したものの、実際にはデータ基盤の整備ばかりを任されるといったミスマッチが、ネガティブな意見を生む大きな原因となっています。

システム全体を見据えた運用設計の重要性
自身が機械学習エンジニアとして現場で活躍できるかどうかの判断ポイントは、「システム全体を俯瞰してビジネス価値を創出できるか」にあります。現場でAIモデルを運用する際、単に予測精度が高いだけのモデルは役に立ちません。
実際の運用では、推論サーバーの負荷分散、応答速度(レイテンシ)の要件クリア、入力データの傾向変化(データドリフト)への対応など、継続的な運用保守である MLOps の体制構築が不可欠です。現場の業務フローにAIをどう組み込み、どう運用していくかというシステム設計の視点を持つことが、プロジェクトを成功に導く鍵となります。
セキュリティとガバナンスの視点
さらに2026年現在、LLM(大規模言語モデル)や生成AIを社内業務に組み込むプロジェクトが急増しており、機械学習エンジニアにはセキュリティやガバナンスの知識も必須要件となりました。プロンプトインジェクションへの対策や、機密データの学習データへの混入防止など、安全なAI運用体制の構築は避けて通れません。
企業がAIを導入する際の具体的なリスク管理や安全な開発手順については、【2026年版】AIアシスタントとは?法人利用の危険性と安全なAIエージェント開発の3ステップ で詳しく解説しています。このような最新のAIエージェント開発の知見を持ち、リスクを適切にコントロールできるエンジニアは、市場価値が非常に高まります。
現場で求められるスキルと実務の実態
「やめとけ」というネガティブな声が上がる背景には、実務における役割や現場運用の難しさへの無理解があります。ここでは、企業が専門人材をどう活用すべきかを踏まえ、求められるスキルを解説します。
実務における役割と基本事項の整理
機械学習エンジニアは、単に最新のAIアルゴリズムを研究する職種ではありません。ビジネス課題を数学的な問題に落とし込み、データを用いて解決に導く役割を担います。
実際の業務においては、華やかなモデル構築作業は全体の2割程度に過ぎず、残りの8割はデータの収集・クレンジング(前処理)や、システムインフラの構築といった地道なエンジニアリング作業が占めています。この実態を事前に理解しておかなければ、想定外の業務内容に疲弊してしまう原因となります。
実運用で直面するデータドリフトとMLOpsの壁
AIモデルを現場で運用する際の最大の注意点は、開発環境と本番環境の乖離です。手元のテストデータで高い精度を達成したモデルであっても、実際のビジネス環境に投入すると、入力データの傾向が変化する「データドリフト」によって予測精度が徐々に低下します。
そのため、モデルを一度作って終わりではなく、継続的に精度を監視し、必要に応じて再学習を自動化する仕組みである MLOps の構築が不可欠です。運用フェーズを見据えたシステム設計ができなければ、実務で価値を生み出し続けることは困難です。実装で使うアルゴリズムの選定基準やPythonでの評価手順は 【2026年版】機械学習モデルとは?種類一覧とPython実装で失敗しない5つの手順 が参考になります。
求められるスキルマップと人材要件

現場で活躍するデータ専門の技術者には、多岐にわたるスキルが求められます。ベースとなるのは、PythonやSQLを用いたプログラミング能力と、微積分や線形代数、統計学といった数学的素養です。
これらに加えて、AIフレームワーク(PyTorchやTensorFlowなど)を扱う技術、クラウド環境(AWSやGoogle Cloudなど)でのインフラ構築スキルが必要です。さらに重要なのが、ビジネスサイドの抽象的な要求を具体的なシステム要件に翻訳するコミュニケーション能力です。技術力とビジネス理解の双方が揃って初めて、現場で機能するプロダクトを生み出すことができます。
独自モデルの開発が本当に必要かを見極める
企業側が高度なAI人材を採用・配置する際の判断ポイントは、「自社独自のデータを用いた専用モデルの開発が本当に必要か」という点に集約されます。
現在、一般的な自然言語処理や画像認識のタスクであれば、クラウドベンダーが提供する学習済みAPIや、既存のSaaSツールで十分に対応可能なケースが増えています。膨大なコストと時間をかけて独自の予測モデルをゼロから構築すべきか、あるいは既存のサービスを組み合わせて迅速に課題を解決すべきか、費用対効果を厳密に比較検討する必要があります。
生成AIの台頭による役割の変化と将来性(オワコン論への回答)
「やめとけ」「オワコン」という声が挙がる背景には、技術の進化スピードが速すぎることが挙げられます。特に昨今の生成AI・LLMの台頭は、機械学習エンジニアの役割を根本から変えつつあります。ここでは、生成AI時代における役割の変化と「オワコン論」が正しいのかどうかを整理します。
生成AI時代における役割の変化
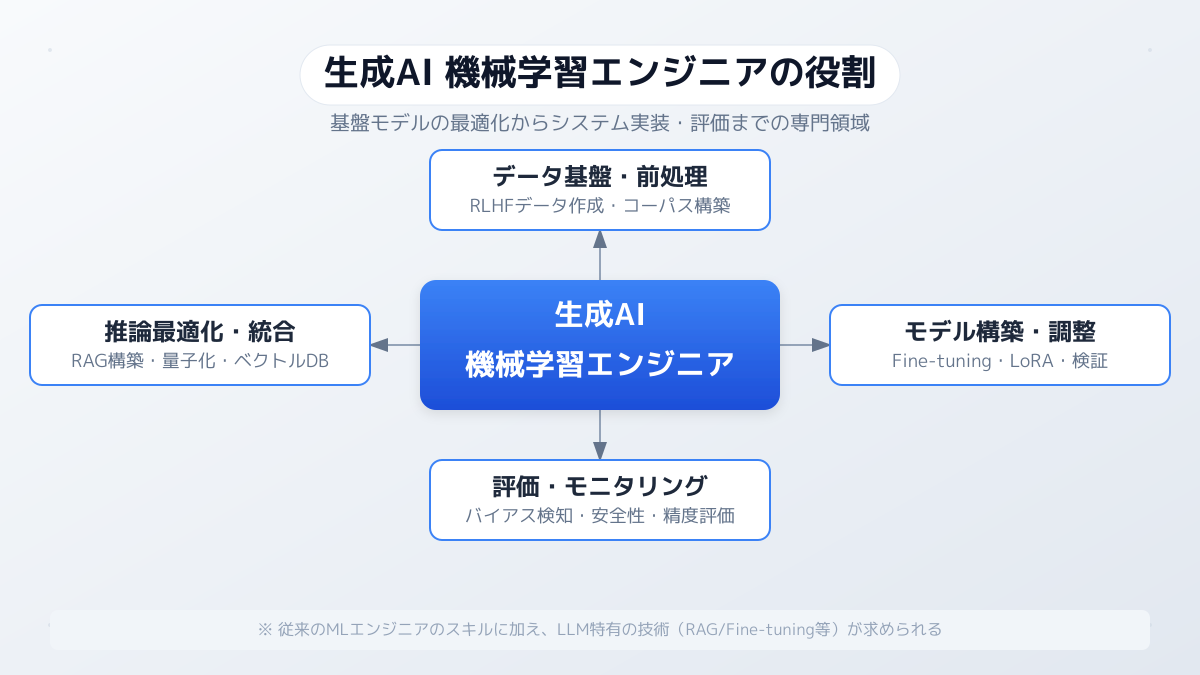
これまでのAIプロジェクトでは、ゼロから独自のモデルを設計し、膨大なデータを集めて学習させることが主流でした。しかし、大規模言語モデル(LLM)をはじめとする生成AIが普及した現在、その開発アプローチは大きく変化しています。
2026年現在、機械学習エンジニアに求められるのは、既存の強力なAIモデルを自社の業務にどう組み込むかという 統合のスキル です。たとえば、社内ドキュメントを読み込ませて精度の高い回答を生成するRAG(検索拡張生成)の構築や、特定の業務に特化させるためのファインチューニング、LLMエージェント/MCP(Model Context Protocol)ツール開発などが主な業務となりつつあります。
つまり、アルゴリズムの研究者としての側面よりも、ビジネス課題を解決するためのAIアーキテクトとしての側面が強くなっています。「アルゴリズムをゼロから書く仕事」が減ったことを指して「オワコン」と表現する声もありますが、後述するように求人数・年収レンジともに依然として右肩上がりであり、職種としてオワコン化しているわけではありません。
API連携とRAG(検索拡張生成)の使い分け
ビジネスの現場にAIを組み込む際、機械学習エンジニアがどのようなアプローチを取るべきかの判断ポイントを具体化することが重要です。主な判断基準は、コストとスピード、そしてセキュリティの3点です。
まず、社内の一般的な業務効率化であれば、既存の生成AIサービスのAPIをそのまま利用するのが最も早く、コストも抑えられます。次に、社内規定やマニュアルなどの独自データを参照させたい場合は、 RAG(検索拡張生成) の導入が適切な選択肢となります。RAGであれば、モデル自体を再学習させることなく、外部知識を組み合わせて精度の高い回答を引き出すことが可能です。
現場のリーダーやDX担当者は、すべての課題を高度なAI開発で解決しようとするのではなく、既存のツールで解決できる領域と自社専用のモデルが必要な領域を明確に切り分ける必要があります。
これからのエンジニアに求められるキャリアパス
AI技術のコモディティ化が進む中、アルゴリズムをゼロから構築するような純粋な研究開発業務は、一部の巨大テック企業を除いて減少していく傾向にあります。
しかし、それはAI専門人材の需要がなくなることを意味するものではありません。むしろ、複数のAIモデルを組み合わせて最適なシステムを設計する能力や、クラウドインフラに関する知識が強く求められています。特定のプログラミング言語に固執するのではなく、最新のAI技術を俯瞰し、ビジネス価値に変換する柔軟性が不可欠です。
機械学習エンジニアの年収相場と求人市場(2026年版)
「やめとけ」「オワコン」という声がある一方で、データに基づく客観的な待遇や需要を把握することは、キャリアの方向性を決める上で不可欠です。2026年5月時点のdoda・レバテック等の調査データを基に、最新の年収相場と求人市況を整理します。
年収相場と求人市場の現状
機械学習エンジニアの年収は、高度な数学的知識とプログラミングスキルの両方が求められるため、IT業界の中でも高い水準に設定されています。各種転職サービスの公開求人を踏まえた職種別の年収比較は以下の通りです。
| 職種 | 平均年収の目安(2026年5月時点) | 求められる主なスキル |
|---|---|---|
| 機械学習エンジニア(正社員) | 600万円〜1,000万円超 | 機械学習アルゴリズム、Python、統計学、MLOps、LLM/RAG |
| 機械学習エンジニア(フリーランス) | 平均月単価 約81万円(年換算約972万円)※レバテックフリーランス調べ | 上記+業務委託での要件定義・PoC推進力 |
| データサイエンティスト | 600万円〜900万円 | データ分析、統計学、ビジネス課題解決力 |
| バックエンドエンジニア | 500万円〜800万円 | サーバーサイド言語、データベース設計、API開発 |
| フロントエンドエンジニア | 450万円〜750万円 | HTML/CSS、JavaScript、UI/UX設計 |
dodaの公開求人では、機械学習エンジニアの予定年収レンジは350万円〜1,000万円程度に分布しており、ハイクラス求人(例:LINEヤフー株式会社)では700万円〜1,260万円のレンジも存在します。LLM・RAG・MCPツール開発など生成AI実装経験を持つエンジニアは、特に高いレンジで採用される傾向です。
2026年現在も、あらゆる産業でDX推進と生成AIのビジネス活用が急務となっており、機械学習エンジニアの求人数は依然として増加傾向にあります。「オワコン」どころか、LLMエージェント開発・ファインチューニング・MCPツール開発などの実務経験を持つエンジニアは引く手あまたの状況です。
自社開発と受託開発の働き方比較
機械学習エンジニアの求人を探す際、最も重要な選択の1つが「自社開発か受託開発(AIベンダー・SIer)か」という点です。それぞれ働き方や身につくスキルが大きく異なります。
| 比較項目 | 自社開発(Web系・SaaS企業など) | 受託開発(AIベンダー・SIer) |
|---|---|---|
| 主なミッション | 自社プロダクトの価値向上、継続的な精度改善 | 顧客の課題解決、要件に合わせたモデル納品 |
| 身につくスキル | MLOps、運用設計、ドメインの深い知識 | 多様な業界の知識、要件定義、PoC推進力 |
| メリット | ユーザーの反響がダイレクトにわかる。長期的な運用に携われる | 幅広い業界のデータに触れられる。最新の手法を提案しやすい |
| デメリット(やめとけ要素) | データの質が悪いと精度向上の頭打ちに悩む | PoC(概念実証)で終わって実運用されないケースが多い |
「自社サービスのデータを継続的に分析・改善したい」のか、「多様な業界のAI課題を解決するスペシャリストになりたい」のか。自身のキャリアプランに合わせて、最適な求人環境を選択することが「やめとけ」と言われるような後悔を避けるポイントです。
後悔しない求人の選び方とキャリア戦略
「機械学習エンジニアはやめとけ」と言われないためには、入社前のミスマッチを防ぎ、自身の強みを活かせるキャリア戦略を立てることが重要です。ここでは、求人選びの際に確認すべき具体的なポイントを解説します。

企業のデータ基盤の整備状況を確認する
求人面接で必ず確認すべきなのは、「その企業に分析可能なデータがすでに蓄積されているか」「データエンジニアリング専任のチームがあるか」という点です。
「AIで何か新しいことを始めたい」という経営陣のトップダウンで採用されたものの、現場には紙のデータしかなく、最初の半年は社内システムのデータ統合とクレンジングばかりやらされるケースは珍しくありません。データ基盤が未整備の環境では、モデル開発に辿り着くまでに膨大な時間がかかり、モチベーションの低下に直結します。
「AIの魔法使い」扱いされていないかを見極める
企業側がAIに対して過度な期待を抱いている求人には注意が必要です。「とりあえずAIエンジニアを採用すれば、売上が上がる仕組みを作ってくれるだろう」という丸投げのスタンスの企業に入社すると、ビジネス課題の特定からデータ収集、システム実装、効果検証までを一人で背負わされる「一人MLOps」状態に陥ります。
- プロジェクトのKPI(目標)が明確に定義されているか
- 事業部門(営業やマーケティングなど)と連携して課題解決にあたるチーム体制があるか
これらが不明確な場合、技術検証(PoC)ばかりで実運用に至らない、いわゆる「PoC死」のプロジェクトを繰り返すことになります。企業のAI導入失敗については、AI PoC死を回避!失敗する7つの原因と成功に導くプロジェクト推進術 の記事でも詳しく解説しています。
フルスタックかスペシャリストかの方向性を決める
機械学習エンジニアのキャリアは、大きく2つの方向性に分かれます。
1つは、データの前処理からモデル構築、クラウドインフラ(AWSやGCP)へのデプロイまで、システム全体を一人で構築できるフルスタック(MLOps)型です。事業会社ではこちらの需要が非常に高く、ソフトウェアエンジニアリングのスキルを武器に高い市場価値を発揮できます。
もう1つは、最新の論文を読み込み、高度なアルゴリズムのカスタマイズや生成AIの独自ファインチューニングを行うリサーチ・スペシャリスト型です。こちらは巨大テック企業や専門のAIベンダーに枠が限られますが、尖った専門性を追求できます。自分がどちらの強みで勝負するのかを明確にしておくことで、キャリアの迷いを防ぐことができます。
機械学習エンジニアに関するよくある質問(FAQ)
最後に、機械学習エンジニアのキャリアについて、よくある疑問に答えます。
機械学習エンジニアは本当に「オワコン」ですか?
オワコンではありません。生成AI・LLMの普及によって「アルゴリズムをゼロから書く」研究色の強い仕事は減りつつありますが、その代わりにRAG構築・ファインチューニング・MCPツール開発・LLMエージェント設計など、ビジネスにLLMを組み込む実装フェーズの仕事が爆発的に増えています。dodaやレバテック等の公開求人を見ても、2026年現在も求人数・年収レンジともに増加傾向にあり、職種としての需要が縮小している兆候はありません。
未経験から機械学習エンジニアになるのは無理ですか?
完全なIT未経験からいきなり機械学習エンジニアになるのは非常にハードルが高いのが現実です。まずはバックエンドエンジニアとしてPythonやデータベースの設計など、ソフトウェア開発の実務経験を1〜2年積むことをおすすめします。その上で、実務の中でデータ分析やAI APIの組み込み経験をアピールし、キャリアチェンジを図るのが最も現実的なルートです。
数学が苦手でも機械学習エンジニアになれますか?
全く数学ができないと、アルゴリズムの仕組みが理解できず、エラーの原因特定や精度改善の壁にぶつかります。しかし、大学院レベルの高度な数学が必須というわけではありません。微積分、線形代数、統計学の基礎を理解し、既存のライブラリ(Scikit-learnやPyTorchなど)のリファレンスを読み解けるレベルの知識があれば、実務の多くはこなすことが可能です。
これから機械学習エンジニアを目指すのは遅いですか?
遅くはありません。むしろ、生成AIの普及によって「AIをビジネスにどう組み込むか」という実装フェーズに入ったことで、需要はさらに高まっています。ただし、アルゴリズムをゼロから作る研究者ではなく、既存のAI技術(LLMやAPI)を組み合わせてシステムを構築する「AIアーキテクト」としてのスキルが求められるようになっています。ソフトウェアエンジニアリングの基礎を固めておけば、十分に将来性のあるキャリアです。
まとめ
「機械学習エンジニアはやめとけ」「オワコン」という声は、業務の広範さや技術進化の速さから生じる課題を反映しています。しかし、その本質は2026年現在もDX・生成AI活用に不可欠な専門職であり、適切なスキルと戦略で年収600万円〜1,000万円超の高い市場価値を維持できます。
本記事では、機械学習エンジニアが直面する以下の主要なポイントを解説しました。
- モデル構築だけでなく、データ前処理やインフラ構築を含む広範な実務が存在する
- 生成AI・LLMの普及により、ゼロからのモデル構築より「既存AIの統合スキル(RAG・ファインチューニング・MCPツール開発)」が求められている
- doda・レバテック等の2026年データでは正社員600〜1,000万円超・フリーランス平均月単価約81万円と、依然として高い年収レンジが維持されている
- 自社開発か受託開発かなど、自身のキャリアに合った求人選びが後悔を防ぐ鍵となる
- 入社前の面接では、企業のデータ基盤の整備状況やチーム体制を必ず確認する
これらの要点を踏まえることで、機械学習エンジニアとしてのキャリアをより深く理解し、「やめとけ」「オワコン」という声に振り回されない判断軸を持てるようになるでしょう。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。