【2026年版】機械学習とは?AI・ディープラーニングの違いと種類・ビジネス活用6つの成功戦略
機械学習とは「データから規則性を自動で学習する技術」であり、AIの一手法、ディープラーニングはその発展形です。2026年最新動向を踏まえ、3つの種類と6つの導入成功戦略を非エンジニア向けに整理します。

「機械学習」をビジネスで導入しようとすると、まず**「AIやディープラーニングとどう違うのか」「自社にはどの種類が合うのか」**で迷いがちです。技術選定を誤ると、PoCで頓挫したり、現場に定着せず投資が回収できないケースが後を絶ちません。
本記事では、機械学習とは何かを2026年最新動向(LLM・基盤モデル)まで含めて即答で整理し、AI・ディープラーニングとの決定的な違い、教師あり学習などの3つの種類、そしてビジネス導入を成功させる6つの戦略までを、非エンジニアにもわかるように解説します。
機械学習とは?要点を30秒で即答

検索意図に直接答えるため、まず結論を先に提示します。
- 機械学習とは:コンピューターが大量のデータを読み込み、その背景にあるパターンや規則性を自動で見つけ出し、未知のデータに対して予測・分類・最適化を行う技術。AIを実現するための代表的な手法の1つです。
- AIとの違い:AIは「人間の知能を模倣する技術全般」を指す広い概念。機械学習はそのAIを実現するための一手法であり、AI ⊃ 機械学習という包含関係になります。
- ディープラーニングとの違い:ディープラーニングは機械学習のさらに一部で、多層のニューラルネットワークを使う発展形。AI ⊃ 機械学習 ⊃ ディープラーニング、という三層構造で覚えると整理しやすいです。
- 種類:機械学習は大きく教師あり学習・教師なし学習・強化学習の3つに分かれます。
- 2026年の位置づけ:ChatGPTやClaudeなどの**LLM(大規模言語モデル)も、Transformerというディープラーニング構造の上に成り立つ「機械学習の応用」**です。生成AIブームは機械学習の延長線上にあります。
ここから先で、AI・ディープラーニングとの違いを表で整理し、種類と導入戦略を1つずつ深掘りしていきます。アルゴリズム選定やPython実装の具体的な手順を先に知りたい方は、【2026年版】機械学習モデルとは?種類一覧とPython実装で失敗しない5つの手順 も並行して参照してください。
機械学習・AI・ディープラーニングの決定的な違い
AI(人工知能)、機械学習、ディープラーニングは現場で混同されがちですが、包含関係と役割が明確に異なります。技術選定で失敗しないために、まずこの違いを整理しましょう。
包含関係と役割の比較表
| 技術領域 | 概要 | データの扱い・特徴 | 代表的なビジネス活用例 |
|---|---|---|---|
| AI(人工知能) | 人間の知能や認知機能をコンピューター上で模倣する技術の総称 | ルールベースから自律学習まで幅広い | チャットボット、エキスパートシステム、ゲームAI |
| 機械学習 | AIを実現する代表的な手法。データから規則性を学習する | 人間が「特徴量」を設計するのが基本 | 売上予測、顧客セグメンテーション、需要予測、不正検知 |
| ディープラーニング | 機械学習の発展形。多層ニューラルネットワークを使う | AI自身が特徴量を自動抽出する | 高度な画像認識、音声認識、自然言語処理(LLM) |
| LLM・基盤モデル(2026年トレンド) | ディープラーニング(Transformer)を超大規模化したもの | 膨大なテキスト・マルチモーダルデータを事前学習し、汎用的に応用 | ChatGPT・Claude・Geminiなどの生成AI、AIエージェント |
このように、AIという大きな枠組みの中に機械学習があり、その中にディープラーニング、さらにその応用としてLLMや基盤モデルが位置づけられるという入れ子構造で理解するのが、2026年時点で最も整合的な捉え方です。
2026年の「機械学習」が指す範囲
2017年にGoogleが発表したTransformer構造を起点に、現在主流のLLM(GPT-5、Claude Opus 4.7、Gemini 3.1 Proなど)はすべて機械学習=ディープラーニングの延長線上にあります。「ChatGPTを使う=機械学習を使っている」と言えるレベルまで、機械学習はビジネスに浸透しました。一方で、需要予測や離反検知のような業務系AIでは**従来型の機械学習(回帰・決定木・XGBoostなど)**のほうがデータ量・コスト・解釈性で有利なケースも多く、すべてをLLMに置き換える必要はありません。
どう使い分けるか
- 数百〜数万件の表形式データから予測したい:従来型の機械学習(回帰・決定木・勾配ブースティング)
- 大量の画像・音声・自然言語を扱いたい:ディープラーニング
- 社内ナレッジを使った文章生成・要約・対話を実装したい:LLM・基盤モデル+RAG
解決したい課題の複雑さ・データ量・必要な汎化性能に応じて、適切なレイヤーを選ぶことが第一歩です。
機械学習の代表的な3つの種類と選び方
機械学習をビジネスへ導入する際、自社の課題に対してどのアプローチが最適かを見極めることが成功の鍵です。機械学習はデータの性質と目的に応じて、主に以下の3つに分けられます。
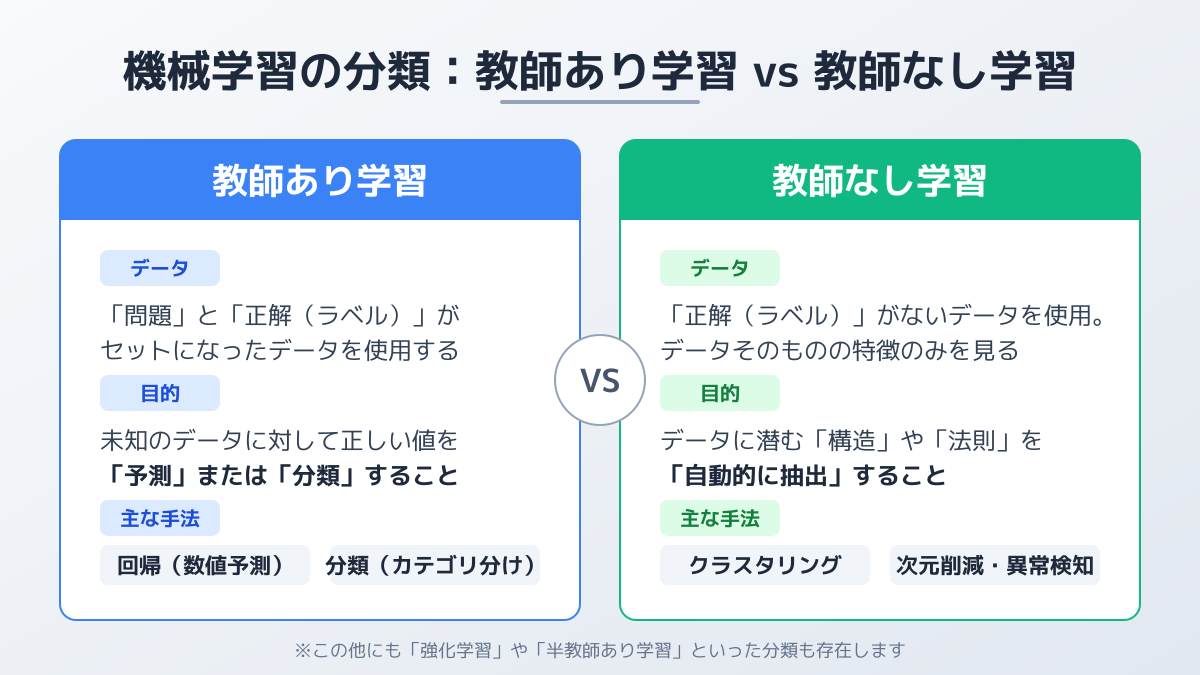
1. 教師あり学習(Supervised Learning)
入力データと「正解(ラベル)」のペアを学習させ、未知のデータに対して予測・分類を行う手法です。
- 得意なこと:分類(カテゴリ判定)と回帰(連続値の予測)
- 代表アルゴリズム:ロジスティック回帰、決定木、ランダムフォレスト、勾配ブースティング(XGBoost、LightGBM)、ニューラルネットワーク
- 活用例:過去の売上から将来の需要を予測(回帰)、画像が不良品か判定(分類)、顧客の解約予測、与信スコアリング、スパム判定
「予測したい正解データが過去にどれだけ蓄積されているか」が成否を分けます。
2. 教師なし学習(Unsupervised Learning)
正解ラベルのないデータから、データそのものの構造や規則性を見つけ出す手法です。
- 得意なこと:クラスタリング(似たデータをグループ化)、次元削減、異常検知
- 代表アルゴリズム:k-means、階層クラスタリング、PCA、Autoencoder
- 活用例:顧客の購買履歴から類似購買パターンのセグメントを抽出、正常データから逸脱した異常値の検知、不正取引・不正アクセスの検出
「正解が存在しないが、膨大なデータから隠れたセグメントや異常を発見したい」場合に有効です。
3. 強化学習(Reinforcement Learning)
「エージェント」が試行錯誤を通じて、設定された報酬を最大化するよう行動を学習する手法です。
- 得意なこと:連続的な意思決定の最適化
- 代表アルゴリズム:Q学習、Deep Q Network(DQN)、PPO
- 活用例:工場のロボットアーム制御、在庫管理の自動最適化、自動運転、広告配信の最適化、レコメンド
近年はLLMのファインチューニングでも強化学習(RLHF:人間のフィードバックによる強化学習)が中核技術として使われています。LLMチューニングの実装手順は、【2026年版】ファインチューニングとは?RAGとの違い・企業向け導入5ステップ で詳しく扱っています。
種類別の選び方フローチャート
「自社のどのタスクにどの種類を当てるか」は、次の3問で大半が決まります。
- 過去の正解データはあるか? → ある:教師あり学習/ない:教師なし学習
- 連続的な意思決定を最適化したいか? → はい:強化学習を検討
- 入力が表形式か、画像・テキストか? → 表形式:従来型機械学習で十分/非構造化:ディープラーニングやLLM
さらにアルゴリズム単位での選定基準やPython(scikit-learn)での実装サンプルは、【2026年版】機械学習モデルとは?種類一覧とPython実装で失敗しない5つの手順 を参照してください。本記事では、種類選定の次に来る「ビジネス導入で失敗しないための戦略」に焦点を当てます。
機械学習のビジネス活用を成功に導く6つの戦略
技術の違いや種類を理解しても、実際の導入では「データ不足」「現場が使わない」「精度が劣化する」といった壁に必ず直面します。ここでは、PoC止まりにせず現場で使われ続ける機械学習を実装するための6つの成功戦略を解説します。
1. 適用業務とAIの相性を見極める
すべての業務をAIに任せるのではなく、機械学習が得意な領域を見極めることが第一歩です。
- 向いている業務:大量のデータが存在し、一定のパターンが見出せる定型的・繰り返し型の業務(需要予測、不良品検知、与信判定、文書分類)
- 向いていない業務:前例のない新規事業の立案、人間の感情的な配慮が必要な業務、データが極端に少ない業務
「データの量×パターンの存在×ミスの許容度」の3軸で評価すると、適用候補が絞り込めます。
2. データの質と量を確保する
機械学習はデータが命です。予測したい事象に関連するデータが十分に蓄積されていなければ、どんなアルゴリズムを選んでも機能しません。
- 量:教師あり学習なら、1クラスあたり最低でも数百〜数千件が目安(タスクによります)
- 質:欠損・ノイズ・ラベル誤りが多いと、前処理に膨大な工数がかかります。導入前にサンプルデータで品質監査を行うことが重要です
- 継続供給:1回きりのデータではなく、運用開始後も常に新しいデータが流入する設計になっているかを確認します
3. 費用対効果と許容リスクを明確にする
データ収集・モデル構築・運用保守にかかるトータルコストと、それによって削減できる業務時間や増加する売上を比較し、費用対効果をシビアに算出します。
同時に、AIの予測は100%ではないことを前提に、誤検知(false positive / false negative)が起きた場合のリスクを業務上どこまで許容できるかを事前に定義します。医療・与信・採用など人生に影響する領域では、人間の最終承認を必ず挟む設計が前提です。
4. 現場担当者との協働フローを構築する
AIがなぜその予測を出力したのかがブラックボックス化すると、現場はシステムを信頼せず使わなくなります。
- 説明可能性:判断理由を可視化する(SHAP・LIMEなどの説明手法、もしくは決定木のようにそもそも解釈しやすいモデルを選ぶ)
- ヒューマン・イン・ザ・ループ:AIの出力結果を人間が最終確認・フィードバックする業務フローを設計する
- フィードバック収集:現場の修正履歴を学習データに戻し、モデルを継続改善するループを作る
安全な運用環境の構築や、AIエージェントを使った業務自動化の具体的手順は、【2026年版】AIアシスタントとは?法人利用の危険性と安全なAIエージェント開発の3ステップ や Claude Sonnet 4.5で業務自動化!Claude in Chrome等AIエージェントツール実践手順 も参考になります。
5. データドリフトを監視し精度を維持する
市場環境やユーザー行動の変化によって、学習時のデータと実際の入力データにズレが生じることをデータドリフトと呼びます。運用開始直後から精度の劣化は始まるため、以下の体制を構築します。
- モデルの出力結果と実際の正解データを定期比較するモニタリングダッシュボード
- 主要KPI(精度・再現率・適合率・売上影響額)のしきい値アラート
- 入力データの分布変化を統計的に検知する仕組み(PSI・KSテストなど)
6. 継続的な再学習サイクルを回す
機械学習モデルは一度導入すれば完成ではありません。データドリフトによる精度低下を検知した際に、新しいデータを用いて再学習(リトレーニング)するMLOps基盤を組み込みます。
- 定期再学習:毎週・毎月など、定期的にモデルを再学習する
- イベント駆動再学習:精度がしきい値を下回ったら自動で再学習をトリガーする
- A/Bテスト:新モデルと旧モデルを並行稼働させ、本番影響を限定的に検証する
中長期で成果を出している企業は例外なく、この運用サイクルの自動化に投資しています。
まとめ:機械学習を正しく理解し、自社に最適な戦略を選ぶ
本記事では、機械学習とは何か、AIやディープラーニングとの違い、3つの種類、そしてビジネス導入を成功させる6つの戦略を解説しました。
- 機械学習は、データから規則性を自動学習し、未知データを予測・分類する技術。AIを実現する代表的な手法の1つです
- AI ⊃ 機械学習 ⊃ ディープラーニングの包含関係。2026年のLLMや基盤モデルもこの延長線上にあります
- 教師あり学習・教師なし学習・強化学習の3種類を、データの有無と目的で使い分けます
- 導入成功にはデータの質・費用対効果・現場との協働・ドリフト監視・再学習サイクルの6戦略が不可欠です
アルゴリズム単位での選定とPython実装の具体的手順は 【2026年版】機械学習モデルとは?種類一覧とPython実装で失敗しない5つの手順 を、自社に最適なAIエージェントサービスの比較は 【2026年版】AIエージェントサービス一覧・徹底比較 もあわせて確認してください。技術と戦略の両輪を回し、持続的な業務効率化と新たな価値創造を実現しましょう。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。