【2026年版】ファインチューニングとは?RAGとの違い・企業向け導入5ステップ
ファインチューニングは「モデルの振る舞い」を自社仕様に固定する強力なAIカスタマイズ手法です。本記事ではRAGとの違い、OpenAI・Anthropic・Googleの2026年最新対応状況、5ステップの導入手順、現場で起こりがちな過学習・情報漏洩への対策までを企業実装視点で整理しました。
LLM(大規模言語モデル)を自社業務に最適化したいものの、どのカスタマイズ手法が最適か迷う企業は少なくありません。特にプロンプトの工夫だけでは解決できない課題において、モデルの振る舞いを根本から変えるアプローチが求められています。
本記事では、ファインチューニングの基本概念から、RAG(検索拡張生成)との具体的な違い、OpenAI・Anthropic・Googleの 2026年最新対応状況、企業での導入を成功させるための判断基準、そして実践的な5ステップまでを徹底解説します。この記事を読むことで、自社の課題に最適なAIモデルを構築し、業務効率化を実現する具体的な道筋が見えてくるでしょう。
ファインチューニングとは
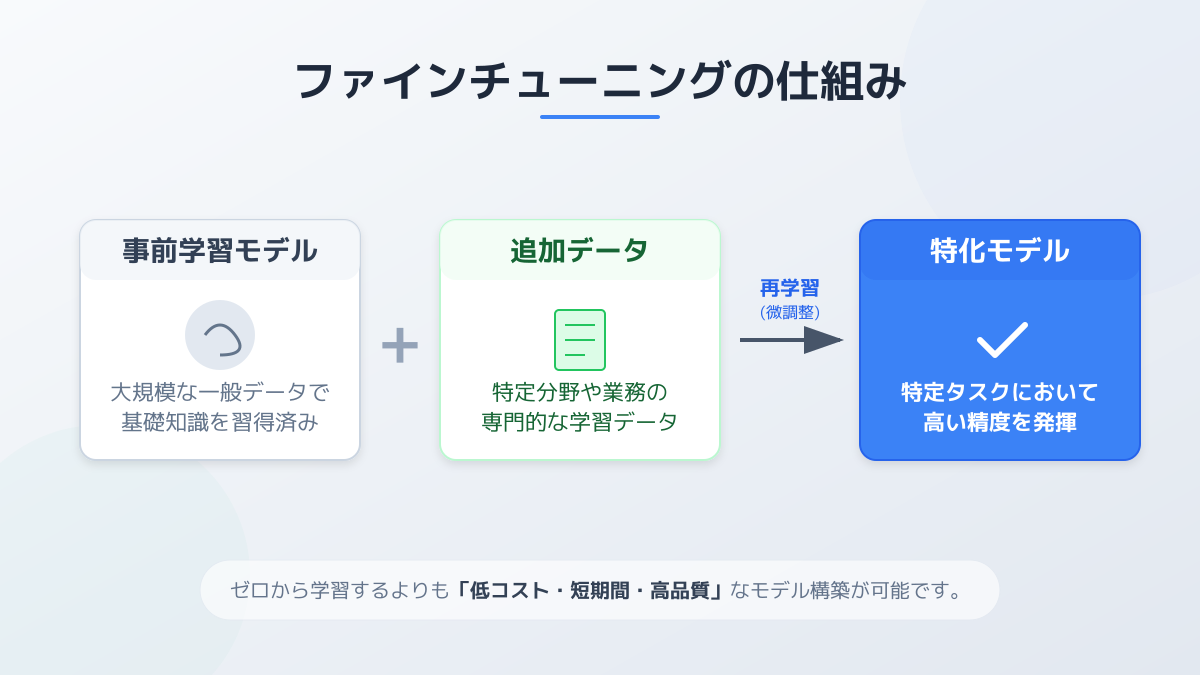
ファインチューニングとは、すでに膨大な知識を持つ既存のLLMに対して、自社固有のデータセットを追加で学習させ、特定のタスクに特化した専用モデルを構築する技術です。
OpenAIの「OpenAI API」やMicrosoftの「Azure OpenAI Service」、AWSの「Amazon Bedrock」などの主要プラットフォームの公式ドキュメントが示す通り、プロンプトエンジニアリングでは対応しきれない「出力形式の厳密な統一」や「特定のトーン&マナーの再現」において、ファインチューニングは極めて高い効果を発揮します。
モデルの内部パラメータ(重み)を直接更新するため、プロンプトに大量の指示を書き込む必要がなくなり、トークン消費量の削減や応答速度の向上にも寄与します。
RAG(検索拡張生成)との違いと使い分け
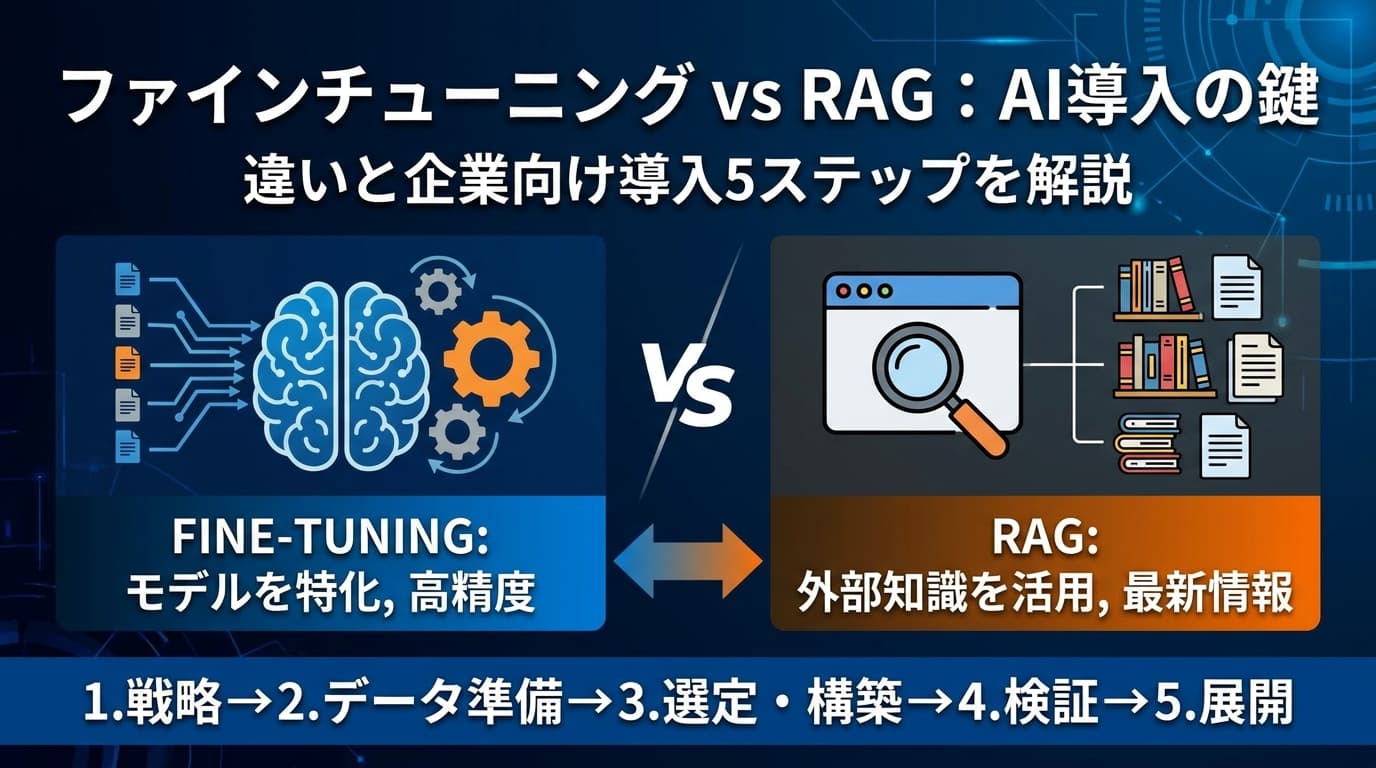
LLMを自社専用にカスタマイズする際、最も比較される手法がRAG(検索拡張生成)です。この2つのアプローチは、AIに対する知識の与え方が根本的に異なります。
RAGは外部データベースから都度情報を検索して回答を生成する仕組みです。社内規定や製品マニュアルなど、常に最新情報や正確な事実確認が求められる業務に強いという特徴があります。
一方で、ファインチューニングはモデル自体の構造を調整するアプローチです。自社特有の口調、特定のドキュメント形式、専門的な推論パターンを固定化させることに優れています。最新の事実を教え込むことよりも、AIの「振る舞い」や「思考の型」を最適化する目的で利用されます。
| 比較項目 | ファインチューニング | RAG(検索拡張生成) |
|---|---|---|
| 主な目的 | 出力のスタイルや推論パターンの固定 | 最新情報や社内データの参照 |
| 仕組み | モデル自体の重み(パラメータ)を更新 | 外部データベースから情報を検索・抽出してプロンプトに結合 |
| 得意なタスク | ブランドトーンの再現、厳密なフォーマット出力 | マニュアル検索、社内規定の確認、最新情報の回答 |
| 情報の更新 | 困難(再学習が必要) | 容易(データベースの更新のみで即時反映) |
| 運用コスト | 高い(データ準備、学習実行のコンピュート費用) | 比較的低い(ベクトルデータベースの運用費用が中心) |
| 代表的な用途 | 特化型カスタマーサポート、議事録の定型出力 | 社内ナレッジ検索、技術問い合わせ自動化 |
目的(知識の拡張か、振る舞いの最適化か)に応じて、どちらの手法を採用するか、あるいは両者を組み合わせて運用するかを検討することがAI導入成功の鍵となります。
LLM単体・RAG・ファインチューニングの全体像をさらに俯瞰したい場合は、【2026年版】LLMとRAGの違いを徹底比較!企業が選ぶべきAIの判断基準と導入手順 も併せて確認してください。
主要モデルのファインチューニング対応状況(2026年最新)
導入検討時にまず把握すべきなのは、ベースとなる主要LLMのファインチューニング対応状況です。プラットフォームによって提供モデル・学習方式・利用可能リージョンが異なるため、自社のセキュリティ要件と運用環境に合った選択が必要です。
| プロバイダー | 主な対応モデル | 提供プラットフォーム |
|---|---|---|
| OpenAI | GPT-4.1、GPT-4.1 mini、GPT-4o、o4-mini など | OpenAI API、Azure OpenAI Service |
| Anthropic(Claude) | Claude 3 Haiku(Amazon Bedrock 上で GA) | Amazon Bedrock |
| Google(Gemini) | Gemini 2.5 Pro / Flash / Flash-Lite(教師ありチューニング) | Vertex AI |
OpenAIではGPT-4.1ファミリー(GPT-4.1 / GPT-4.1 mini)やGPT-4o、推論特化モデルのo4-miniなどが教師ありファインチューニングに対応しています。AnthropicのClaudeは、現状Amazon BedrockでのClaude 3 Haiku向け機能としてGAされており、Anthropic直販APIでの一般向けファインチューニング提供は限定的です。GoogleのGeminiは、Vertex AIの教師ありファインチューニング(Supervised Fine-Tuning)でGemini 2.5 Pro / Flash / Flash-Liteなどに対応しています。
なお、各モデルの料金やリージョン、学習可能データ形式は変更されることがあるため、実装前には必ずOpenAI・AWS・Google Cloudの公式ドキュメントで最新情報を確認してください。
導入を判断する3つの基準
ビジネス現場でファインチューニングの導入を判断する際は、以下の3つの基準で検討することが重要です。
1. 出力スタイルや推論の型を厳密にコントロールしたいか
自社ブランドのトーン&マナーに完全に一致させたカスタマーサポートの自動応答や、複雑な業界用語を用いた特定フォーマットでの議事録作成など、プロンプトの工夫だけでは出力が安定しないタスクにおいて高い効果を発揮します。逆に、単に「社内の最新データを参照させたい」だけであれば、RAGを採用する方が適しています。
2. 知識の更新頻度
一度学習させたモデルの知識を後から部分的に修正することは困難です。法改正や新製品のリリースなど、頻繁に情報がアップデートされる業務には不向きです。変化の激しい知識ベースの補完には外部検索(RAG)を頼り、出力のトーン&マナーや論理展開の型の固定にのみファインチューニングを適用するのが、最も費用対効果の高い運用設計です。
3. コストとデータ準備の工数
導入にあたっては、データ準備にかかる人件費だけでなく、学習実行にともなうクラウドコンピューティング費用も発生します。具体的な予算感やコストの抑え方については、【2026年版】生成AI導入費用の相場と内訳|最大450万円の補助金と失敗しないステップもあわせて参考にしてください。
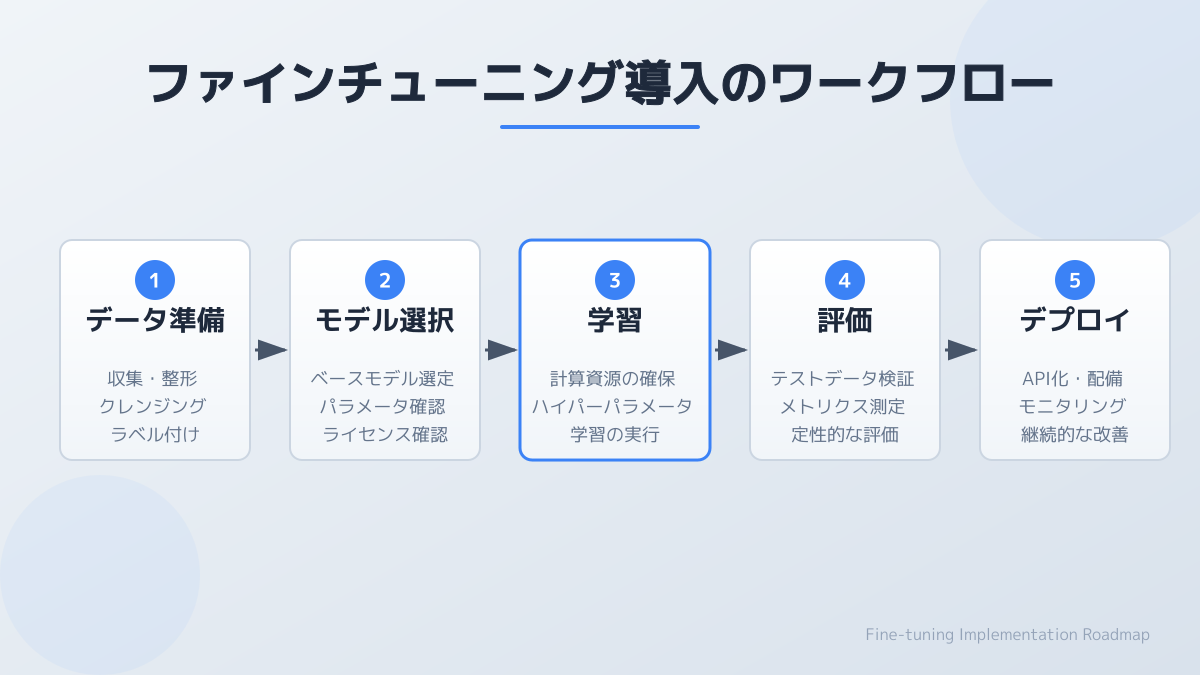
ファインチューニングの導入ステップ

実際にプロジェクトへ組み込む際は、体系的な導入ステップを踏む必要があります。一般的には以下の5つのワークフローで進行します。
1. データ準備(サンプルあり)
人間が理想とする入力と出力のペアデータ(高品質なプロンプトと回答のセット)を数百から数千件規模で用意します。OpenAIのチャットモデルをファインチューニングする場合、以下のようなJSONL(JSON Lines)形式でシステムプロンプト、ユーザーの入力、AIの理想的な回答をセットにして定義します。
【学習データのフォーマット例(JSONL形式)】
{"messages": [{"role": "system", "content": "あなたは親しみやすいカスタマーサポート担当です。"}, {"role": "user", "content": "商品の返品は可能ですか?"}, {"role": "assistant", "content": "はい、商品到着後7日以内であれば返品を承ります。お手数ですが、注文番号をお知らせいただけますでしょうか。"}]}
{"messages": [{"role": "system", "content": "あなたは親しみやすいカスタマーサポート担当です。"}, {"role": "user", "content": "送料はいくらかかりますか?"}, {"role": "assistant", "content": "全国一律で500円頂戴しております。ただし、5,000円以上のお買い上げで送料無料となります!"}]}
2. データクレンジング
ノイズの多いデータや事実誤認を含んだデータを学習させると、AIの出力精度が著しく低下します。誤字脱字の修正、フォーマットの統一、不適切な表現の削除など、厳密な品質管理(データクレンジング)を行います。この工程の質が、最終的なモデルの精度を大きく左右します。
3. モデル選択と学習
自社の要件に合ったベースモデルを選択し、準備したデータセットを用いて学習を実行します。企業向けの開発環境としては、エンタープライズレベルのセキュリティを備えた「Azure OpenAI Service」や、Googleの「Vertex AI」、AWS環境でセキュアに完結する「Amazon Bedrock」などのクラウドプラットフォームを活用して専用モデルを構築するのが一般的です。前述の対応状況を踏まえ、自社の既存クラウド契約・データ所在地要件に合致するプラットフォームを選定します。
4. 評価とテスト
学習が完了したモデルに対し、トレーニングに使用していない未知のデータを入力してテストを行います。期待するトーン&マナーや出力形式が維持されているか、事実とは異なる回答(ハルシネーション)が増加していないかを定量的に評価します。
5. デプロイと継続的改善
テストをクリアしたモデルを実業務に組み込みます。一度構築して終わりではなく、現場の利用状況やフィードバックを収集し、新たなデータを追加して定期的に再学習を行う「継続的改善」のサイクルを設計することが不可欠です。
企業におけるファインチューニング事例
具体的なファインチューニング事例として、ある大手製造業がベテラン技術者のトラブルシューティング手順を学習させたケースがあります。
この企業では、過去10年間に蓄積された熟練技術者の対応履歴や保守レポートから、約1,500件の高品質なQ&Aデータセットを抽出・クレンジングしました。これをベースモデルに学習させることで、単なるマニュアル検索ではなく、熟練者特有の「故障原因の切り分け方」という推論パターンをAIに獲得させました。
結果として、若手社員の一次対応にかかる時間が平均40%短縮され、エスカレーション件数も月間30%削減されるという定量的な成果を上げています。
他業界での具体的な運用イメージを掴むには、【2026年版】建設業AIの活用事例7選|建築設計の業務効率化を実現する具体例と導入ステップ も併せてご確認ください。
現場運用における注意点とセキュリティ
ファインチューニングを現場で運用する際は、いくつかの技術的・セキュリティ的な注意点が存在します。
過学習と破滅的忘却のリスク
特定のタスクに特化させすぎると、モデルが元々持っていた一般的な推論能力が低下する「破滅的忘却」や、未知のデータに柔軟に対応できなくなる「過学習(オーバーフィッティング)」といったリスクが生じます。定期的な評価フェーズを設け、ベースモデルの汎用性が損なわれていないかを確認する体制が不可欠です。
セキュリティとガバナンスの徹底
学習データとして投入した情報がモデルの重みとして記憶されるため、個人情報や機密情報を含んだまま学習させてしまうと、悪意のあるプロンプトによって機密データがそのまま引き出される情報漏洩リスクが生じます。
現場で安全に運用するためには、以下の対策が求められます。
- 学習データの前処理と匿名化: 機密情報や個人情報は学習前に必ずマスキングする
- 厳格なアクセス制御: カスタマイズしたモデルを利用できる部署や権限を最小限に絞る
- 継続的な監視体制: 予期せぬ出力やプロンプトインジェクションを防ぐための入力・出力フィルタリングを実装する
ファインチューニングに関するよくある質問
Q1. ファインチューニングとRAGはどちらを優先すべきですか?
まずは「最新情報や社内データを参照させたいだけ」であればRAGを優先します。プロンプトの調整やRAGでも出力スタイルや専門タスクの精度が安定しない場合に、ファインチューニングを検討するのが費用対効果の高い順序です。両者は排他ではなく、トーン&マナーは固定し、参照情報はRAGで補うハイブリッド構成も有効です。
Q2. 学習データはどれくらい用意すれば十分ですか?
タスクの複雑さによりますが、一般的には数百件〜数千件の高品質なペアデータが目安です。量よりも品質が重要で、ノイズや事実誤認を含むデータは精度を大きく低下させます。少量でも一貫したフォーマット・トーンのデータを丁寧に揃えることが先決です。
Q3. 既存モデルの汎用的な能力は失われませんか?
過度に偏ったデータで学習させると「破滅的忘却」が起こり、汎用的な能力が低下する可能性があります。学習エポック数の調整、汎用ベンチマークでの定期評価、必要に応じてベースモデルの切り戻しなど、運用設計でリスクを抑えることが重要です。
Q4. 個人情報を含むデータをそのまま学習させても大丈夫ですか?
避けるべきです。学習データはモデルの重みに反映されるため、悪意ある入力で機密情報が引き出されるリスクがあります。学習前のマスキング・匿名化、厳格なアクセス制御、入出力フィルタリングを必ず組み合わせて運用してください。
まとめ
本記事では、LLMを自社向けに最適化するファインチューニングについて、RAGとの違い・主要モデルの2026年対応状況・導入5ステップ・運用上のリスクまでを多角的に解説しました。
ファインチューニングは、LLMの「振る舞い」や「推論パターン」を自社仕様に根本から変更する強力な手段です。一方、RAGは「最新情報の検索」に優れており、それぞれの得意分野を理解し、目的(知識の拡張か、振る舞いの最適化か)に応じて使い分けることが、AIプロジェクト成功の鍵となります。
高品質な学習データの準備、継続的な評価体制の構築、そして適切なリスク管理を行うことで、企業は安全かつ効果的にAIを活用し、持続的な業務効率化と生産性向上を実現できるでしょう。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。