【2026年版】マルチモーダルAIとは?画像・音声・テキスト統合の仕組みとDX活用事例5選
テキストだけでなく画像・音声・動画を1つのモデルで処理する「マルチモーダルAI」が2026年にかけて急速に普及しています。GPT-5・Claude Opus 4.7・Gemini 3.1 Proなど最新モデルの仕組みと、神戸物産・大林組・Med-PaLM Mなど5業界の実在事例を、Mordor Intelligenceの市場予測とあわせて解説します。
マルチモーダルAIとは、テキスト・画像・音声・動画など複数のデータ形式を1つのモデルで統合処理するAI技術です。 2026年は、OpenAIの「GPT-5」、Anthropicの「Claude Opus 4.7」、Googleの「Gemini 3.1 Pro」がいずれもネイティブにマルチモーダル対応を完成させ、企業のDX現場でも実装フェーズに入りました。本記事では、仕組みの基本から最新モデルの仕様、製造業・医療・建設・教育・小売の5業界における実在企業の活用事例、Mordor Intelligenceによる市場予測、導入時の判断ポイントまで、DX推進担当者が押さえるべき要点を解説します。
マルチモーダルAIとは?基本概念と仕組み
マルチモーダルAIとは、テキスト・画像・音声・動画・センサー情報など、複数の異なるモダリティ(データの種類)を統合して処理するAIのことです。従来のAIは、テキストならテキストのみ、画像なら画像のみを扱う「シングルモーダル」が主流でした。マルチモーダルAIは、これらを掛け合わせることで、より深い文脈理解と人間に近い判断を実現します。
技術の根幹はTransformerアーキテクチャと、モダリティ間の関係を学習するクロスアテンション機構です。各モダリティを共通の埋め込み空間に投影し、Cross-Attention や Projection で融合することで、文脈と意味が一貫した出力を生成できます。
たとえば、動画データから「映像に映る人物の表情」と「発話のトーン」を同時に解析し、感情の機微を読み取るような処理がマルチモーダルAIの典型的なユースケースです。
LLMとAIエージェントの進化
マルチモーダル化は、近年のLLMとAIエージェントの実用性を一段引き上げました。2026年現在の主要モデルはいずれもネイティブにマルチモーダル対応しています。
- OpenAI GPT-5(2026年8月リリース)/ GPT-5.5(2026年4月23日リリース): テキスト・画像・音声・動画を単一アーキテクチャで処理する omnimodal モデル。GPT-5.5は最大1Mトークンのコンテキストに対応します(OpenAI GPT-5.5 Model Card)。
- Anthropic Claude Opus 4.7(2026年4月16日 GA): 最大3.75メガピクセルの高解像度ビジョンと長文ドキュメント理解に強み。コーディング系ベンチマークも前世代比+13%向上(Anthropic 公式発表)。
- Google Gemini 3.1 Pro(2026年2月19日リリース): テキスト・画像・音声・動画・PDFをネイティブ入力でき、入力1Mトークン・出力64Kトークンに対応。最大1時間の長尺動画分析が可能(Google DeepMind モデルカード)。
これにより、会議室のホワイトボード写真と録音音声をAIに渡すだけで、議事録とタスクリストが自動生成されるといったエージェント的ワークフローが現実になっています。
マルチモーダルAIの市場規模と将来予測
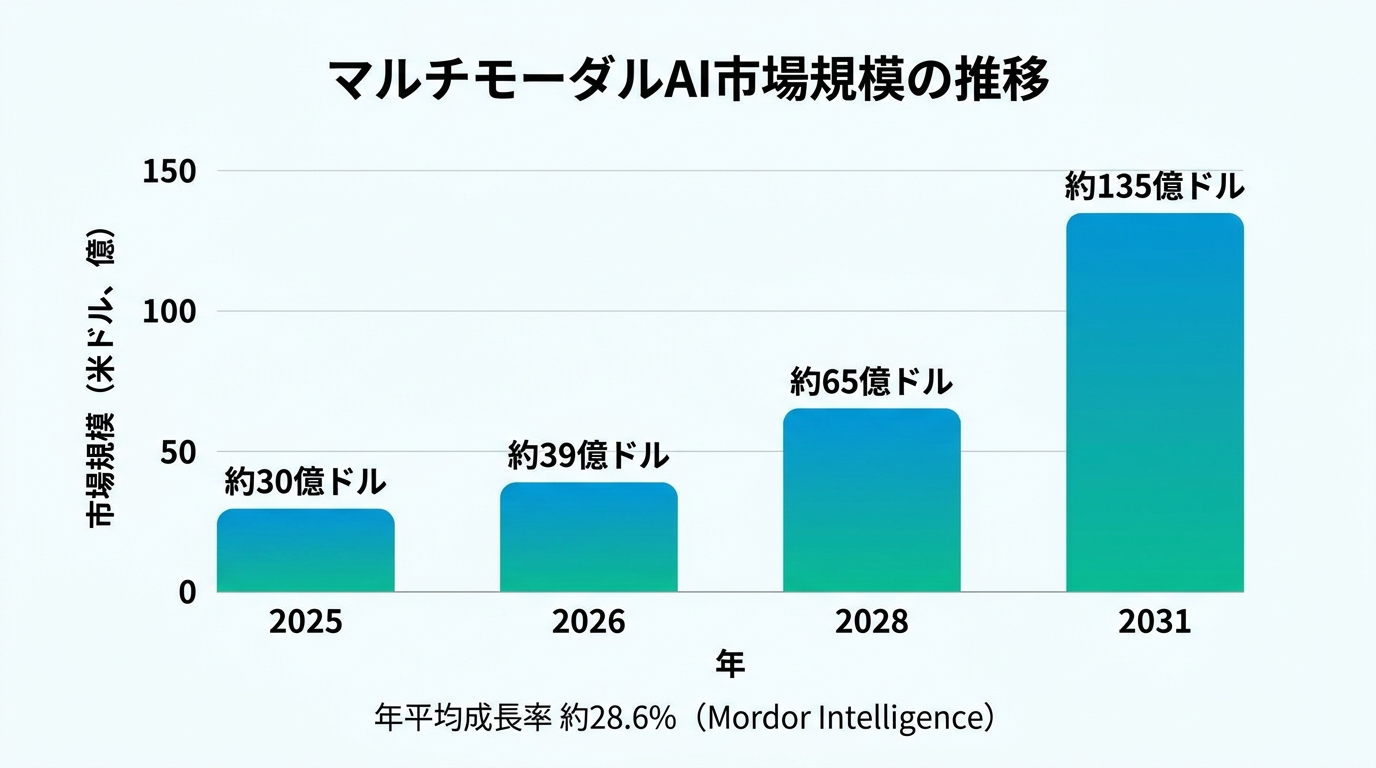
マルチモーダルAI市場は急速な拡大期にあります。Mordor Intelligenceの調査では、世界のマルチモーダルAI市場規模は 2025年に29.9億米ドル、2026年には38.5億米ドルに達し、2031年には135.1億米ドル規模まで拡大 すると予測されています(年平均成長率28.59%、2026〜2031年)。Grand View Researchも2030年に108.9億米ドル(CAGR 36.8%)の予測を出しており、調査機関により幅はあるものの、いずれも30%前後の高成長を見込んでいる点で一致しています。
地域別では、北米が2025年に40.7%のシェアを占める一方、アジア太平洋地域は2031年までCAGR 40.9%で最も高い成長率を示すとされています。垂直業界別では、ヘルスケア・ライフサイエンスが25.8%のシェアでトップ、小売・EC領域はCAGR 33.2%で最も急成長する見込みです。
DX推進では、テキストだけでなく現場の画像・音声・IoTセンサーデータを統合分析するニーズが急増しており、マルチモーダルAIの活用余地が業種を問わず広がっている状況です。
業界別のマルチモーダルAI活用事例5選
ここからは、すでに実用段階に入っている5つの業界別事例を紹介します。いずれも実在企業・公開済みプロダクトに基づく事例です。
1. 製造業:AWS BedrockのマルチモーダルAIによる異常検知
製造現場では、画像・音声・センサーデータを統合した異常検知が進んでいます。AWSの公式ブログで公開されている事例では、Amazon Bedrock経由で利用可能なマルチモーダルAIを用いた鉄道車両の異常画像検知システムが、全異常種別の平均正解率95.6%、適合率99.5%、再現率95.5%、F値97.4% を達成しています(AWS公式ブログ)。
加えて、AWSは「Amazon Lookout for Vision」(画像異常検知)と「Amazon Monitron」(振動・温度センサー分析)を組み合わせた予知保全ソリューションを提供しており、画像・音・振動を1つのパイプラインで統合分析する設計が標準化されつつあります。微小な異音や部品摩耗、外観不良などをリアルタイムに検知でき、目視検査では捉えにくいレベルの早期異常発見が可能になります。
2. 医療:Google「Med-PaLM M」による電子カルテと診断画像の統合
Googleが研究発表したマルチモーダル医療AI「Med-PaLM M」は、患者の電子カルテ(テキスト)とX線・MRI・CTなどの医用画像、ゲノムデータを統合して診断支援を行います。医師が頭の中で結びつけている「過去の病歴」と「目の前の画像所見」を、AIが横断的に解析できる点が特徴です。
電子カルテと診断画像のマルチモーダル統合により、見落としやすい微細病変の兆候を提示でき、診断の精度とスピードの両立に寄与します。医療画像生成AI市場でも、単一モダリティから画像・テキスト・音声を組み合わせた統合システムへの移行が進んでおり、医師の認知負荷軽減という観点で導入価値が高い領域です。
3. 建設業:大林組のBIM × AIによる現場管理自動化
建設現場では、3Dモデルとカメラ映像、作業報告テキストを統合する取り組みが進んでいます。大林組は2026年4月、磐越自動車道「宝珠山トンネル」工事において「セントル全自動セットシステム」と「覆工コンクリート自動打設締固めシステム」を組み合わせ、従来5〜6人を要した施工を3人で実施 することに成功しています(ITmedia 報道)。
BIMモデル(3Dデータ)に蓄積された設計情報と、現場のカメラ映像・作業ログ(テキスト)をAIが横断解析することで、進捗管理・品質検査・人員配置を自動化する仕組みも実用化されています。同社が運用する品質管理システム「GLYPHSHOT」もクラウド対応版として進化中で、現場監督の確認作業を大幅に省力化しています。建設業界全体のAI活用は、【2026年最新】不動産AI活用事例6選でも関連業界の動向として整理しています。
4. 教育:学習履歴とNotion AIで実現する音声 × テキスト統合
教育・研修領域では、学習履歴(テキスト)と授業動画・講義音声を組み合わせる活用が広がっています。代表例が、Notionデスクトップアプリの「AIミーティングノート」です。Zoom等の講義音声を直接録音し、AIが要約・タスク抽出までを一気通貫で実行します(実装手順はNotion AI議事録の作り方で解説)。
学校現場では、AI学習プラットフォーム(COMPASSの「Qubena」など)が生徒の解答ログ・学習履歴と端末操作データを統合し、つまずきの早期検知を行っています。文部科学省も生成AIガイドライン Ver.2.0で校務利用シナリオを明確化しており、現場導入の制度面も整備が進んでいます(詳細は文部科学省の生成AIガイドライン解説を参照)。
5. 小売:神戸物産 × ソフトバンク STAIONによるPOS × 映像分析
小売・飲食では、レジのPOSデータ(テキスト)と店内カメラ映像を統合し、来店客の行動を可視化する事例が増えています。ソフトバンクのAI映像解析プラットフォーム「STAION」は、リアルタイムで人数カウント・属性推定・動線分析を行うサービスで、神戸物産の次世代型店舗で採用されています(ソフトバンク公式 導入事例)。
同社の来店客数予測サービス「サキミル」は、POS・人流統計・気象・カレンダー情報を組み合わせ、来店予測精度約93% を達成し、欠品・廃棄ロスの削減に貢献しています。映像と数値データを掛け合わせることで、単純な売上分析では捉えられない実態に即した店舗改善が可能になります。
マルチモーダルAI導入時の判断ポイントと運用上の注意点
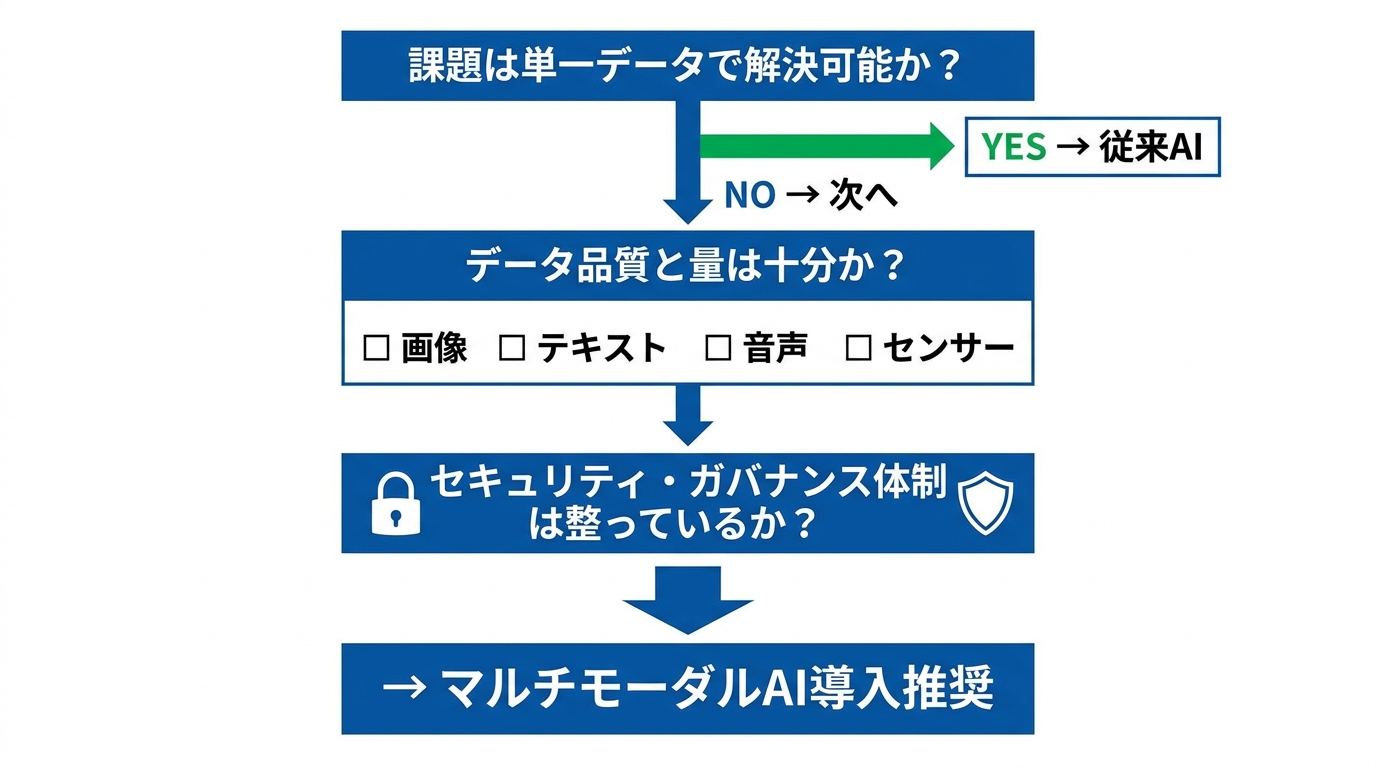
マルチモーダルAIを導入する前に、以下の3点を順に検証してください。
- 課題が単一データで解決可能か: テキスト処理だけ、画像認識だけで足りる課題なら、従来のシングルモーダルAIの方がコスト・運用面で有利です。複数データを掛け合わせる必然性を明確にしましょう。
- データ品質と量は十分か: 画像が不鮮明だったり、テキストに欠損があったりすると、AIが誤った相関を学習します。各モダリティの収集ルールを標準化し、人間の最終確認フローをプロセスに組み込むことが必須です。
- セキュリティ・ガバナンス体制が整っているか: 機密性の高い音声・社内資料・個人情報を扱うケースでは、強固なアクセス制御と情報漏洩対策が前提となります。
データ品質の担保が成功の鍵
多様なデータを同時に処理するため、一部のデータに欠損やノイズが含まれているとAIの出力精度が著しく低下します。データの収集ルールを標準化し、人間が最終確認を行うフローを業務プロセスに組み込むことが必須です。
セキュリティとガバナンスの確保
機密性の高い音声データや顧客の個人情報を扱う場面が多いため、強固なアクセス制御と情報漏洩対策が不可欠です。最新技術だからという理由ではなく、どの業務プロセスで複合データ処理が必要かを明確にし、セキュアな環境で運用設計することが求められます。
よくある質問
マルチモーダルAIとシングルモーダルAIの違いは何ですか?
シングルモーダルAIはテキスト・画像のいずれか単一のデータを処理しますが、マルチモーダルAIはテキスト・画像・音声・動画など複数を同時に統合処理し、より複雑な文脈理解が可能です。
2026年時点で代表的なマルチモーダルAIモデルは何ですか?
OpenAI「GPT-5 / GPT-5.5」、Anthropic「Claude Opus 4.7」、Google「Gemini 3.1 Pro」の3系統が主流です。いずれもテキスト・画像・音声・動画をネイティブに処理できます。
導入に必要なデータ量はどれくらいですか?
目的によりますが、各モダリティで一定量の高品質データが必要です。まずは小規模なPoC(概念実証)から始め、必要なデータ量を見極めることを推奨します。
中小企業でも導入できますか?
はい。GPT-5 APIやGemini APIのようにクラウド経由で従量課金で利用できるため、大規模インフラ投資なしで導入できる環境が整っています。Gemini 3.1 Proは入力100万トークンあたり2米ドル、出力100万トークンあたり12米ドルから利用可能です。
まとめ
マルチモーダルAIとは、テキスト・画像・音声・動画を統合処理する次世代AI技術であり、2026年はGPT-5・Claude Opus 4.7・Gemini 3.1 Proがいずれもネイティブにマルチモーダル対応を完成させたフェーズに入っています。市場規模はMordor Intelligenceの予測で2031年に135億米ドルに達する見込みで、製造業・医療・建設・教育・小売の各領域ですでに実在企業の事例が積み上がっています。導入を成功させるには、課題が単一データで解決できないかの確認、データ品質の担保、セキュリティ・ガバナンス設計の3点が鍵です。本記事の知見を、自社のDX推進に役立ててください。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。