【2026年版】LLMとRAGの違いを徹底比較!企業が選ぶべきAIの判断基準と導入手順
LLMとRAGの違いを「比較表・選び方フロー・2026年の新潮流(Hybrid Search・S3 Vectors・マネージドRAG)・運用注意点・FAQ」で1本に整理。社内データ活用とハルシネーション対策の判断軸が明確になり、自社にとってLLM単体で十分か、RAG構築が必要かを最短で見極められます。
LLMとRAGの違いを一言でまとめると、**LLM(大規模言語モデル)は事前学習した公開データだけで回答する「単独のAI」**であるのに対し、RAG(検索拡張生成)はLLMに「自社の最新データを検索する仕組み」を追加した構成です。LLM単体は学習済みの一般知識を高速に返すのに向き、RAGは社内規程や最新の製品マニュアルなど、学習に含まれない情報を根拠として参照させたい業務に向いています。
本記事では、検索ボリュームの大きい「LLM RAG 違い」というクエリに対し、比較表・選び方のフローチャート・2026年の新潮流(Hybrid SearchやAmazon S3 Vectorsなど)・運用上の注意点を1本で網羅し、企業のAI導入担当者が次の一歩を判断できるように整理します。
機密情報の扱いの全体像は生成AIのリスクと情報漏洩を防ぐ対策、LLMそのものの仕組みはLLMの仕組みを5分で完全理解も併せて参考にしてください。
LLMとRAGの違いとは?社内データ活用の基本
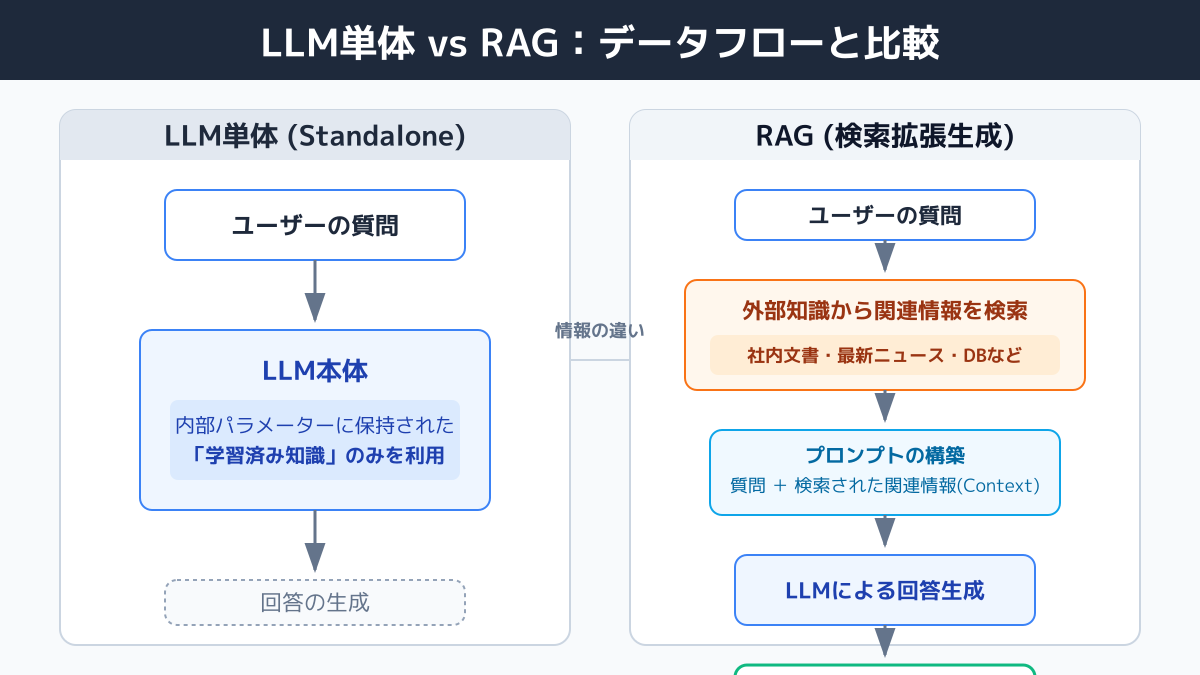
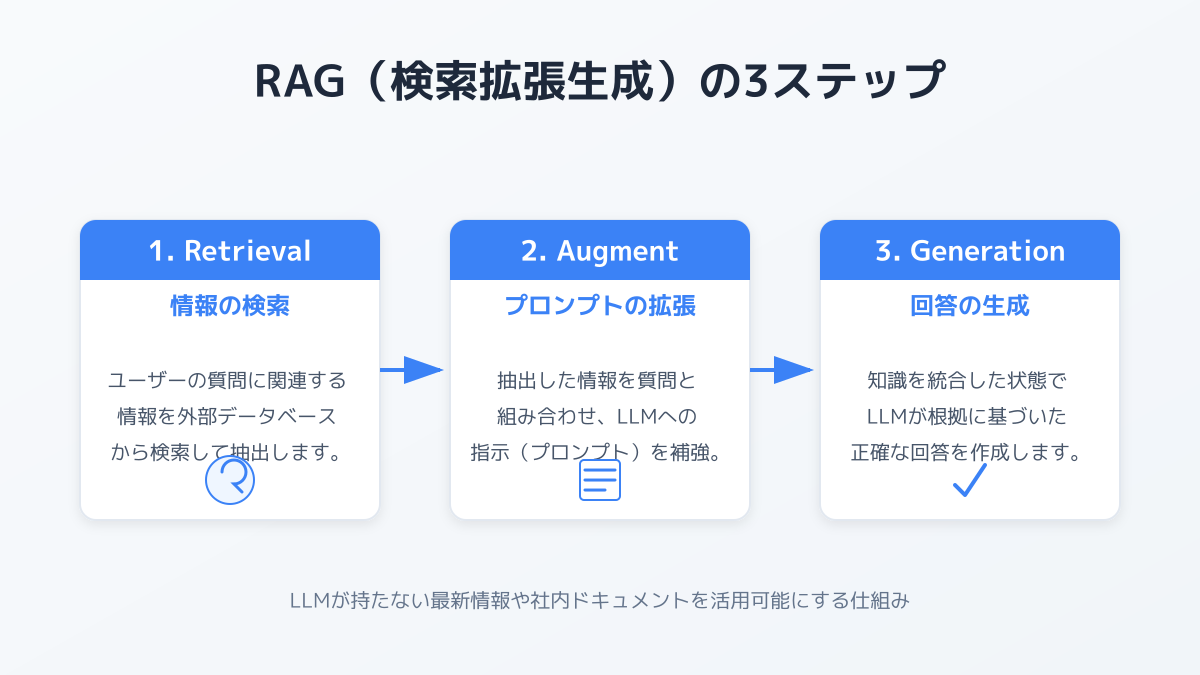
LLM(大規模言語モデル)は、事前学習した膨大なテキストを基に「次に来る単語の確率」を予測して回答を生成します。一方、RAG(Retrieval-Augmented Generation:検索拡張生成)は、ユーザーの質問に対してまず外部データベースから関連文書を検索し、その内容をプロンプトに加えてからLLMに回答させる構成です。
たとえば「2026年度の経費精算ルールを教えて」と質問した場合、LLM単体では一般的な経理知識しか返せませんが、RAGなら自社の最新規程を検索・引用したうえで回答できます。LLM単体とRAGの違いを正しく理解することが、ハルシネーション(もっともらしい嘘)を抑えながら社内データを活用する第一歩です。
RAGの仕組みは、大きく「検索(Retrieval)」「拡張(Augment)」「生成(Generation)」の3段階に分かれます。社内ドキュメントをあらかじめ細かく分割(チャンク化)してEmbedding(埋め込みベクトル)に変換し、Vector Storeに保存しておきます。質問が来ると、その質問もEmbeddingに変換して類似度の高いチャンクを取り出し、文脈として追加した上でLLMに渡す、という流れです。
モデル自体に社内データを覚え込ませる「ファインチューニング」と比較すると、RAGは元の文書を直接参照するため情報源が明確で、データの追加・更新が容易、コストも抑えられます。一方ファインチューニングはモデルの「話し方・書式」を整える用途に向き、両者は競合ではなく補完関係にあります。
LLM単体とRAGの比較表
LLM単体とRAGの違いを、企業の導入判断で重要となる7項目で比較しました。
| 比較項目 | LLM単体 | RAG(検索拡張生成) |
|---|---|---|
| 情報源 | 事前学習された公開データのみ | 外部の社内データベース・最新Web情報 |
| 情報の鮮度 | 学習時点までの古い情報 | 検索時点の最新情報 |
| ハルシネーション耐性 | 弱い(事実確認の根拠がない) | 強い(検索した文書を根拠にできる) |
| 機密データの活用 | 不可(学習データ外) | 可能(権限制御つきで参照) |
| 回答の出典 | 提示しづらい | チャンク単位で出典提示が可能 |
| データ更新コスト | 再学習が必要で高コスト | 文書の差し替えで即反映 |
| 主な用途 | 要約、翻訳、アイデア出し、定型文作成 | 社内規程の照会、製品マニュアルFAQ、過去事例検索 |
RAGとファインチューニングの違いと使い分け
社内データ活用の選択肢として、RAGとよく比較されるのが「ファインチューニング」です。両者の役割を混同すると、ROIが見合わない投資になりがちなので整理しておきます。
ファインチューニングは、特定のドメインの言い回しや文体・出力フォーマットをLLMに習慣化させる手法で、医療カルテの記述形式など「書き方」を揃えたいケースで効果を発揮します。一方、「最新の事実を正しく答えさせる」目的にはRAGの方が圧倒的に低コストかつ柔軟です。
両者は二者択一ではなく、たとえば「自社専門用語の言い回しはファインチューニングで整え、参照する社内事実はRAGで都度検索する」という併用が現実解になることも多くあります。
LLMの比較とRAG導入の判断基準

導入を検討する際の判断ポイントは、「自社固有の事実確認が必要か、それとも一般的な言語処理で十分か」という1点に集約されます。メールの文面作成、一般的な要約・翻訳、アイデア出しといった用途であればLLM単体でも十分です。しかし、社内規程の照会、過去議事録に基づく提案書作成、製品マニュアルに基づくカスタマーサポートなど、事実の正確性と出典提示が求められる業務を行う場合は、情報源を特定できるRAGの構築が不可欠となります。
複数のAIモデルを検討する LLMの比較 の段階でも、RAGアーキテクチャとの連携のしやすさは重要な評価基準となります。Claude Opus 4.7・GPT-4o・Gemini 1.5 Proのように、一度に処理できる情報量(コンテキストウィンドウ)が大きいLLMを選ぶことで、RAGが検索してきた大量の社内ドキュメントを正確に読み込ませることができます。Anthropic法人プランの選び方はClaude最新モデル選び方ガイドで詳しく解説しています。
構築基盤としては、AWS Bedrock Knowledge Bases・Azure AI Search・Google Cloud Vertex AI SearchといったクラウドプロバイダーのマネージドRAGや、Difyなどのオープンソース系プラットフォームを採用することで、自社環境に合わせた柔軟なシステム設計が可能になります。
LLM自体の基本的な仕組みや生成AIとの違いについては、LLMとは?仕組みと企業向け導入ガイド も参考にしてください。
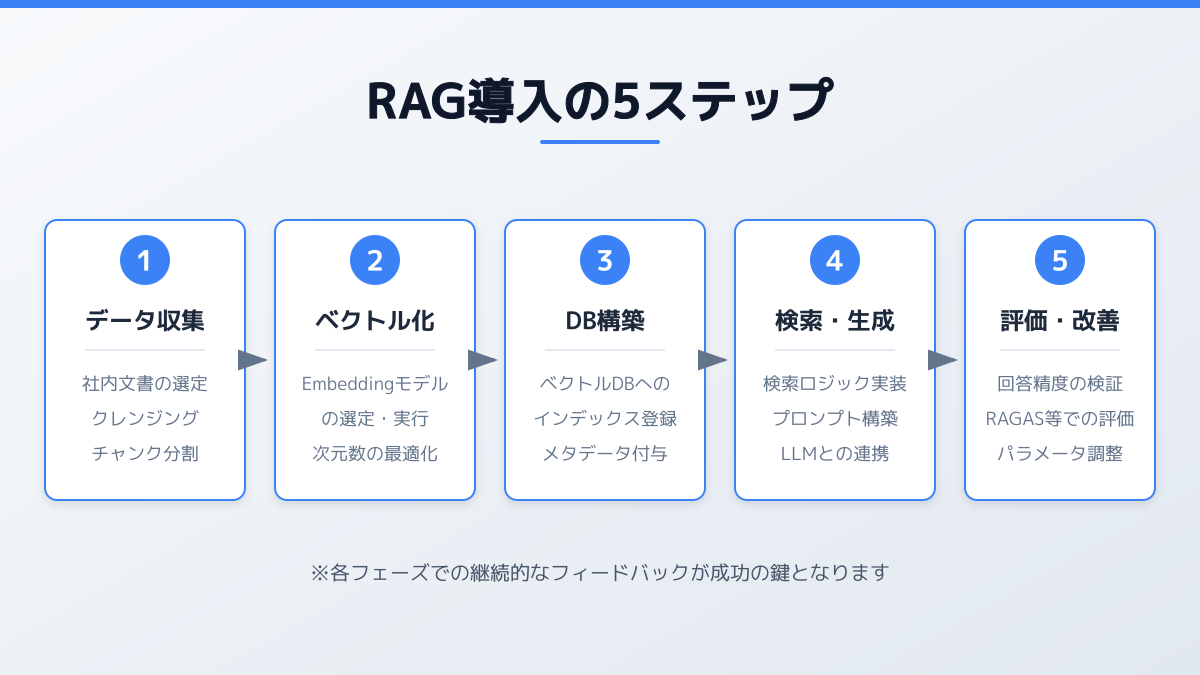
RAG構築アーキテクチャの主要要素(2026年版)
2026年時点で、企業向けRAGを構築する際に押さえるべき主要要素は次の5つです。
- Embeddingモデル:日本語精度の高い
text-embedding-3-large(OpenAI)やCohere Embed v3、日本語特化のRuriなどから業務データに合うものを選定 - Vector Store:Pinecone・Weaviate・Qdrantなどの専用DB、もしくはOpenSearch・PostgreSQL(pgvector)など既存DBを拡張する選択肢がある
- 検索方式(Hybrid Search):ベクトル類似度(意味検索)とBM25(キーワード一致)を組み合わせる構成が2026年の主流
- 再ランキング(Reranker):取得したチャンクの順序をCohere Rerank等で並び替え、関連度の高い情報だけをLLMに渡す
- オーケストレーション:LangChain・LlamaIndex、もしくはマネージドサービス(Bedrock Knowledge Bases等)で全体をつなぐ
2026年のRAG新潮流|Hybrid Search・S3 Vectors・マネージド統合
2025年から2026年にかけて、RAGまわりは「自前で組む」から「クラウドが提供するマネージド機能を使う」フェーズへと急速に移行しています。LLMとRAGの違いを理解したら、最新動向を知ったうえで構築方針を決めるとROIが大きく変わります。
特に押さえておきたい3つの動きを整理します。
- Hybrid Searchが標準化:AWS・Azure・Google Cloudの主要RAGサービスで、ベクトル検索とキーワード検索(BM25)を1クエリで統合する「Hybrid Search」が標準機能化。意味の近さと表記揺れの両方に対応できる
- Amazon S3 Vectorsの登場:AWSはRAG向けの低コストベクトルストレージとしてAmazon S3 Vectorsを発表。従来型のVector DBと比較して大幅にコストを抑えやすく、Bedrock Knowledge Basesと連携可能
- Microsoft 365とAzure AI Searchの深い統合:Azure AI SearchはSharePoint Online・OneDrive・Azure Blob Storage等のドキュメントを自動取り込みし、ベクトル類似度・セマンティック再ランキング・BM25を1クエリに束ねるエンタープライズ仕様
企業視点で重要なのは、これらのマネージドサービスを使うことで、構築・運用にかかるエンジニアリング工数を従来比で大幅に削減できる点です。一方、特定クラウドへの依存度(ベンダーロックイン)が高まる側面もあるため、本番運用前に「データ抽象層を挟んで他基盤に移行できる構造にしておく」ことを推奨します。
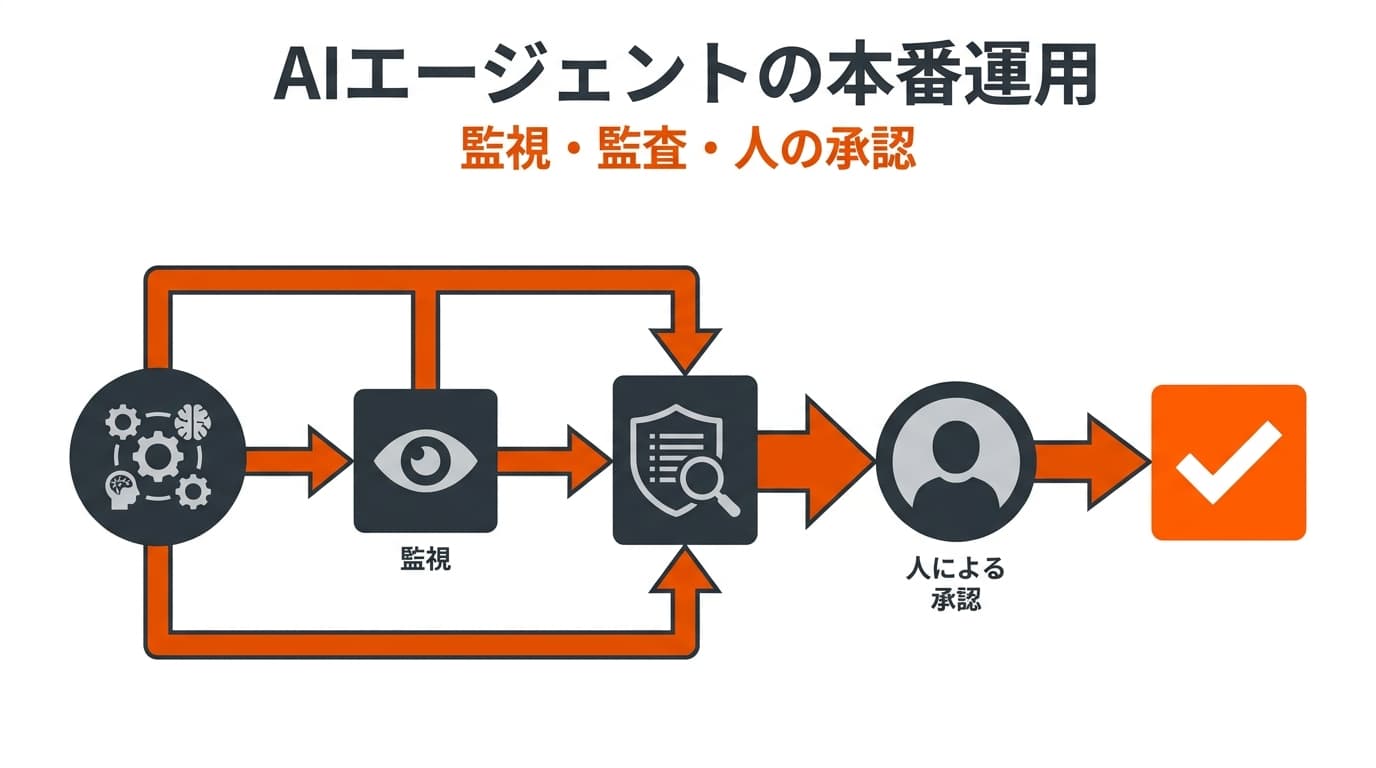
LLM・RAG運用時のデータ品質管理とセキュリティ
LLMとRAG を現場で運用する際の最大の注意点は、参照元となる社内データの品質管理です。RAGは検索したデータに基づいて回答を生成するため、古いマニュアルや誤った情報がデータベースに混ざっていると、そのまま誤答につながります。
運用を成功させるためには、以下の対策を徹底する必要があります。
- データのクレンジング:検索対象とするドキュメントは常に最新の状態に保ち、古い情報や重複する内容を定期的に削除する
- アクセス権限の制御:機密情報が意図せず回答に含まれないよう、従業員ごとの閲覧権限をRAGシステムに反映させる(Azure AI SearchやBox AIは元のACLを継承する仕組みを持つ)
- チャンク分割の最適化:長い文章を適切なサイズ(一般的には300〜800トークン程度)に分割し、検索エンジンが文脈を正確に捉えられるように調整する
- 継続的な評価指標の運用:「答えが見つかった割合(Retrieval Recall)」「回答の正確性(Faithfulness)」をRagasなどで定期測定し、Embeddingモデルの差し替えやチャンクサイズの再調整を行う
また、RAGの精度を高めるには、AIに対して適切な指示を出すスキルも求められます。具体的な指示の出し方については、ハルシネーションの原因と誤出力を防ぐプロンプト事例 を参考にしてください。運用全体を通じたセキュリティリスクの評価手法は企業向けAIリスクマネジメント実践ガイドで詳しく解説しています。
企業におけるLLM・RAGの活用領域と効果の出し方
LLMとRAGの連携導入により、多くの企業が業務効率化に取り組んでいます。事例の数字を盲信するのではなく、自社のどの業務に効きそうかを見極めて導入する姿勢が重要です。
代表的な活用領域は次の通りです。
- 社内ヘルプデスク:人事規程・経費精算ルール・ITサポート手順を一元化し、新人や中途入社者の問い合わせを24時間自動応答
- カスタマーサポート(一次対応):過去の対応履歴と最新の製品仕様書を参照させ、新人オペレーターが熟練者並みの初期回答を出せるよう支援
- 営業の提案書ドラフト:自社の過去提案・製品仕様・成功事例を検索し、顧客特性に合った提案ドラフトを高速生成
- 法務・コンプライアンスチェック:規程・契約書・関連法令を参照させ、契約書ドラフトのリスクを事前に洗い出す
これらの領域では「月◯時間→月◯時間」のような定量効果を社内で測定する仕組みを最初に決めておくと、ROI評価と継続投資判断がスムーズになります。導入プロセス全体や費用対効果の判断は生成AI導入支援はいる/いらない?コンサルvs内製化の判断基準 を、社内データを安全に使う具体的な事例はBox AI 活用事例6選も併せて参考にしてください。
よくある質問
LLMとRAGの違いを一言でいうと?
LLMは事前学習した公開データだけで回答する「単独のAI」、RAGはそこに「自社の最新データを検索する仕組み」を加えた構成です。LLM単体は一般知識の処理に強く、RAGは自社固有の事実を根拠付きで答えさせたい業務に向いています。
RAGとファインチューニングはどちらを選ぶべき?
「最新の事実を正しく答えさせたい」ならRAG、「特定の文体・出力フォーマットを習慣化させたい」ならファインチューニングです。両者は競合ではなく補完関係で、業務データの一部をRAG、文体調整をファインチューニングで担当させる併用も一般的です。
LLM・RAGシステムの構築にかかる費用はいくらですか?
システムの規模や連携するデータ量によって異なりますが、一般的なクラウドサービスを利用したスモールスタートであれば月額数万〜数十万円程度で構築可能です。大規模なオンプレミス環境を構築する場合は、初期費用が数百万円以上かかることもあります。機密データを守るためのオプションはLLMローカル環境の構築手順も参考にしてください。
初期費用なしでLLM・RAG環境を始める方法はありますか?
既存のSaaS型AIツール(Claude TeamプランやChatGPT Enterpriseプランなど)を活用すれば、初期開発費用をかけずに、社内ドキュメントをアップロードするだけで簡易的なRAG環境を構築できます。Anthropic法人プランの選び方はClaude最新モデル選び方ガイドで詳しく解説しています。
RAGでもハルシネーションは起こりますか?
検索結果の品質が低い、チャンク分割が不適切、Embeddingモデルがドメインに合っていない、などの場合はRAGでも誤答は起こります。RAGはハルシネーションを「抑える」仕組みであり「ゼロにする」仕組みではありません。継続的な評価と改善が前提となります。
まとめ
本記事では、LLMとRAGの違いを比較表・判断フロー・2026年の新潮流(Hybrid Search、Amazon S3 Vectors、マネージドRAG統合)・運用上の注意点までを1本で整理しました。LLM単体は一般知識の処理に強い「単独のAI」、RAGは自社固有の事実を根拠付きで答えさせる「拡張構成」というすみ分けを押さえれば、自社の業務にどちらが必要かを判断しやすくなります。
導入を成功させるためには、参照する社内データの品質管理、アクセス権限制御、Embeddingモデル・チャンクサイズの継続チューニングが鍵となります。これらのポイントを押さえれば、ハルシネーションを抑えながら業務効率化と意思決定の高速化を両立できる、実用的な社内AI環境を構築できるでしょう。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。