【2026年版】生成AIで社内・自社データを活用する7ステップ|LINEヤフー年70万時間削減に学ぶRAG導入
生成AIで社内データ・自社データを活用する具体的な手順を2026年最新版で解説します。LINEヤフー「SeekAI」で年70〜80万時間削減した実例、Microsoft 365 CopilotやAzure OpenAIなどの現実解、RAG導入7ステップ、ハルシネーション対策と権限管理の実装ポイントまでをロードマップ化しました。

生成AIで社内データ・自社データを活用するには、目的を絞った業務選定 → データ整備 → RAG(検索拡張生成)構築 → スモールスタート → 出力検証 → 運用ルール → 改善サイクルの7ステップで進めるのが最短ルートです。LINEヤフーは独自のRAGツール「SeekAI」を全従業員に展開し、年間70〜80万時間の業務削減を目標に掲げています。
本記事を読むと、次の3点がわかります。
- 生成AIに社内データ・自社データを学習させる現実的な選択肢(Microsoft 365 Copilot / Azure OpenAI Service / RAG構築)の使い分け
- 失敗を避けるための導入7ステップと、各ステップで押さえるべき判断基準
- ハルシネーション・情報漏洩・権限管理を実装する運用ルールの作り方
「社内データ」と「自社データ」は文脈で使い分けられますが、ともに自社が保有する非公開情報を生成AIに参照させる点で目的は同じです。本記事ではどちらの検索からたどり着いた読者にも対応できるよう、両方の表現を併記しながら解説します。
生成AIで社内・自社データを活用する3つの選択肢
社内データ・自社データを生成AIに参照させるには、大きく3つの選択肢があります。まず自社の状況に合うものを把握すると、後続のステップでの意思決定が速くなります。
| 選択肢 | 概要 | 向いている企業 |
|---|---|---|
| Microsoft 365 Copilot | Microsoft Graph経由でTeams・SharePoint・OneDrive・Outlookの自社データに直接アクセスし、回答生成に利用する。入力データはモデルの再学習に使われない。 | すでにMicrosoft 365を全社利用しており、メール・議事録・社内文書を一気通貫で扱いたい企業 |
| Azure OpenAI Service / Vertex AI などのクラウドAI基盤 | 各クラウドのベクター検索やインデックス機能と組み合わせ、社内文書を取り込んだRAGを構築する。AzureはAI Search、Google CloudはVertex AI Searchを提供。 | セキュリティ要件が厳しく、自社のクラウド契約・閉域網内で完結させたい企業 |
| 法人向けChatGPTやNotion AI、Difyなどのツール+RAG | ノーコード・ローコードで社内ナレッジを取り込み、短期間でPoCを回せる。 | DX担当者主導でまず小さく試したい中小・中堅企業 |
これらはどれを選んでも、共通して必要になるのが社内データの整備とRAG(検索拡張生成)の考え方です。RAGはハルシネーションを抑え、根拠となる社内文書を提示できる仕組みで、社内データ活用の中核となります。LLMとRAGの違いを整理したい方はLLMとRAGの違いと企業の判断基準も合わせてご覧ください。
RAG(検索拡張生成)とは|社内データ活用の中核
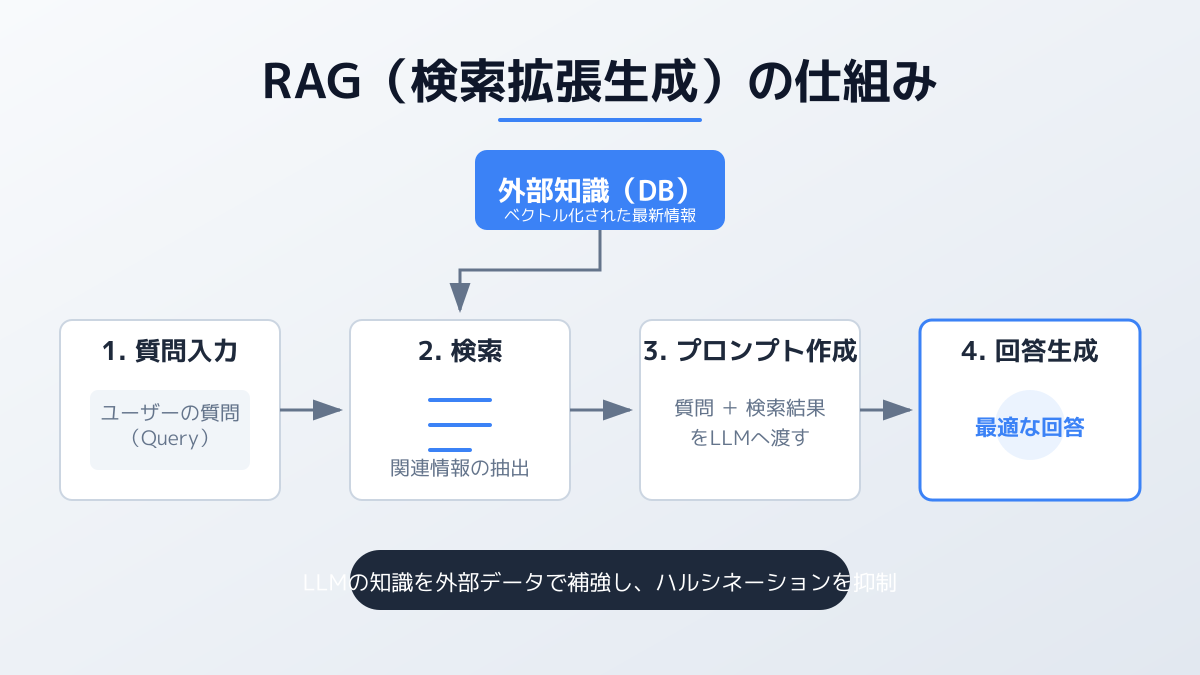
RAGとは、ユーザーの質問に対して社内データベースから関連情報を検索し、その結果をプロンプトに含めてLLMに回答させる技術です。Retrieval-Augmented Generation(検索拡張生成)の略で、自社の固有情報を一般的なLLMに「外付け知識」として持たせるアプローチに位置づけられます。
RAGが選ばれる3つの理由
ファインチューニング(自社データでモデルを再学習する手法)と比較すると、RAGには次の利点があります。
- 開発コストが低い: モデルの再学習が不要で、社内文書をベクトル化してデータベースに登録するだけで運用を始められる
- 最新情報に追従しやすい: 社内マニュアルが更新されても、データベースを差し替えるだけで反映できる
- 回答の根拠を提示できる: 「この回答はどの文書のどのページを参照したか」を表示でき、ハルシネーションが起きても利用者が一次情報で検証できる
LINEヤフーのSeekAI事例|年70〜80万時間削減の目標
LINEヤフーは2024年7月、社員約3.4万人を対象にRAG技術を活用した業務効率化ツール**「SeekAI」を全社展開しました。社内ワークスペースや業務文書を参照元とし、部門・プロジェクトごとにデータを登録できる仕組みで、広告事業のカスタマーサポート業務ではテスト導入時点で約98%の正答率**を達成。全社で年間70〜80万時間の業務削減を目指しています。
このように、RAGは「単に質問へ答える生成AI」を「社内データに根ざした業務支援AI」へ進化させる役割を担います。
失敗しない導入7ステップ|社内データ・自社データ活用の最短ルート
ここから、現場で迷わず実践できるロードマップとして7ステップを順に解説します。
ステップ1:目的の明確化と対象業務の選定

最初のステップは、「どの業務を、どのくらい改善するか」を1〜2行で言語化することです。「全社のドキュメント検索を効率化する」のような抽象的な目的は失敗の元になります。
具体例として推奨されるのは次のような対象業務です。
- 総務・人事のFAQ自動化: 「経費精算の手順は?」「有給申請の期限は?」など、定型的な問い合わせを社内マニュアルに基づいて回答
- 営業部門の提案書ドラフト作成: 過去の提案書・受注事例から類似案件を引き、構成案を生成
- カスタマーサポートの一次回答: 製品マニュアルとFAQから、オペレーターの回答候補を提示
選定基準は「データの機密性が比較的低く、業務の反復性が高い」ことです。給与情報や契約交渉履歴など、機密性が極端に高いデータからは始めません。
社内に対するROI(投資対効果)の説明軸を整理したい場合は、生成AI導入支援はいる/いらない?コンサルvs内製化の判断基準と費用相場が判断材料になります。
ステップ2:社内データの整備とクリーニング

RAGの精度は、参照する元データの品質で9割決まると言ってよいほど、データ整備の比重は大きい工程です。どれほど高性能なモデルを使っても、PDFが文字化けしている・古い社内規定が混在している状態では期待値を下回ります。
整備の基本動作は次のとおりです。
- 形式の統一: PDF・Word・Excel・社内Wikiなどに散在するデータを、テキストやMarkdownなどLLMが処理しやすい形に変換する
- ノイズ除去: 廃止された製品マニュアル、退職者のメモ、社内雑談ログなど、現在の業務に関係しない情報を除外する
- メタデータ付与: 文書ごとに「最終更新日」「担当部署」「機密区分」をタグ付けし、検索時のフィルタリングに使えるようにする
NTTデータが提唱する「RAG構築の民主化」の考え方では、データ整備をDX・IT部門だけで抱えるのではなく、業務に詳しい各部署が自ら参照データを管理する体制が推奨されています。これにより、データ更新のサイクルを早く回せます。
初期検証では100〜500件程度のドキュメントで十分です。範囲を絞り、質を高めることを優先します。
ステップ3:RAG(検索拡張生成)の構築
ステップ2で整えたデータを、実際に生成AIから検索できる形にする工程です。アプローチは大きく2つに分かれます。
- ノーコード・ローコードツール: Azure OpenAIのAI Search、Google CloudのVertex AI Search、Difyなどの既製基盤を組み合わせる。中小企業や、まずPoCを始めたい企業に向く
- フルスクラッチ構築: 自社で埋め込みモデル・ベクトルデータベース・検索ロジックを設計する。閉域網の制約や独自のランキング要件があるエンタープライズ向け
実装時に押さえるべきポイントは次のとおりです。
- チャンク(分割)設計: 文書を意味のかたまりごとに分割しないと、検索結果が文の途中で切れて精度が落ちる
- 埋め込みモデルの選定: 日本語ドキュメントが多い場合は、日本語に最適化された埋め込みモデルを選ぶと検索精度が大きく変わる
- 回答の根拠表示: 回答画面に「参照した文書名・ページ番号」を必ず表示する設計にする
ハルシネーションを抑えるための具体的なプロンプト・モデル設計は、ハルシネーション対策7つの方法で実装パターンを確認できます。
ステップ4:スモールスタートによる段階的な展開

全社一斉に展開すると、現場フィードバックが集まる前に運用が崩れます。特定の部署や業務に絞り、3〜6か月で改善サイクルを回すスモールスタートが現実的です。
具体的には次の流れで進めます。
- PoC期間(1〜3か月): 1部署・1ユースケースに限定してデータ100〜500件で運用。回答精度・利用率・所要時間削減の3指標を測定
- 限定展開(2〜3か月): PoCで効果が確認できたら、隣接部署や類似業務に横展開。ガバナンスとログ取得の仕組みを整える
- 全社展開: 利用ガイドラインと教育プログラムを整備したうえで全社へ広げる
導入が定着しないリスクと、その回避策についてはAI導入失敗事例7大原因と回避策が参考になります。
ステップ5:出力検証と最終確認フローの構築
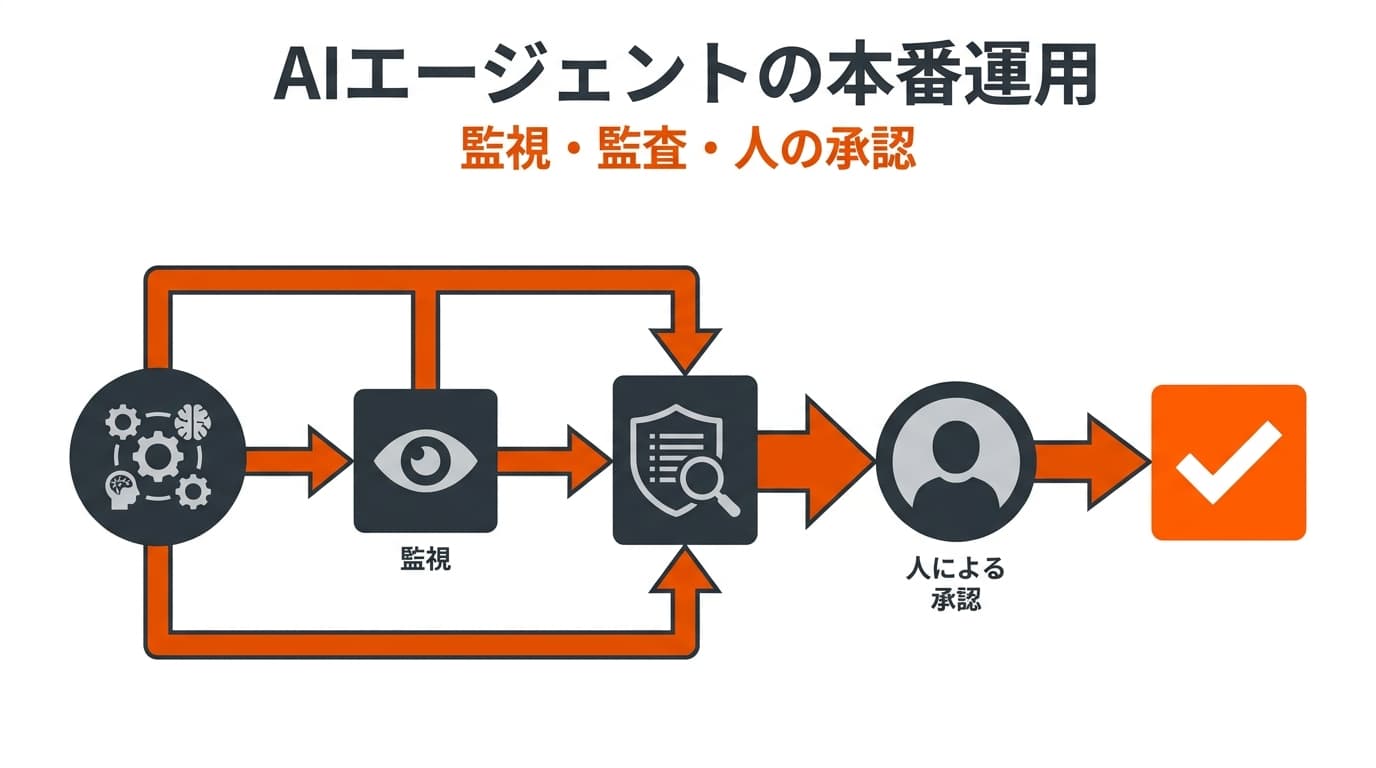
社内データを参照させても、ハルシネーション(事実と異なる回答)はゼロにはなりません。出力結果に対する人間の最終確認を業務フローに組み込むことが鉄則です。
- ヒューマンインザループ(Human-in-the-Loop)の設計: AIの回答を必ず人間が一次情報と照合してから外部に出すルールを徹底する
- 適用業務の優先順位: 議事録要約・社内検索など、担当者が即座に正誤を判断できる業務から始める
- 慎重に扱う業務: 顧客への見積もり提示、契約書類のドラフト、財務開示など、誤りが重大なトラブルにつながる業務は、AIの精度が安定するまで人間によるダブルチェック必須にする
特にハルシネーションは「AIに『嘘をつかないで』と命じても効果がない」ことが知られています。詳しいプロンプト設計はAIに「ハルシネーションしないでください」は逆効果!嘘を防ぐプロンプトと8つの対策で確認してください。
ステップ6:権限管理と現場へのルール徹底
社内データには機密区分・役職別アクセス権限が存在します。生成AIが「権限のない従業員に経営データや人事情報を出力してしまう」事故は、設計次第で防げます。
実装時のチェックポイントは次のとおりです。
- 役職・部署別のデータベース分離: 経営会議資料・人事評価・顧客個人情報は別テーブルに分け、利用者の権限に応じて参照範囲を制御する
- 入力ガイドラインの周知: プロンプトに入力してはいけない個人情報・機密情報を明文化し、年1回以上の研修で徹底
- シャドーAI対策: 個人アカウントの無料生成AIに業務データを貼り付ける利用を、社内ルールで明確に禁止する
- 回答ログの取得: 誰が何を聞き、どの文書を根拠に回答したかを保存し、監査・改善に活用
サムスン電子では2023年に、生成AI導入から20日間で機密情報の流出が3件発生したと報じられました。具体的な対策は生成AIの情報漏洩リスクとは?サムスン3件流出に学ぶ5つの対策で詳しく整理しています。
教育プログラム全体を体系化したい場合は、現場で定着する「生成AI活用研修」の作り方が役立ちます。
ステップ7:運用後の継続的な改善サイクル
導入で終わらず、継続的な改善サイクルを回すことが成果の鍵です。AIの回答精度は、参照データの鮮度と利用者のプロンプト品質に大きく依存します。
回すべきサイクルは次の3つです。
- フィードバックの収集: 回答画面に「役に立った/不正確だった」のボタンを設置し、利用者の評価を蓄積
- データクレンジング: 評価が低かった回答の原因を特定し、陳腐化したマニュアルを月次〜四半期で除外
- プロンプトテンプレートの改善: 効果的だった質問パターンを社内テンプレート化し、新規利用者へ共有
2026年最新の日本企業の生成AI利用率は55.2%に達した一方、業務への定着では世界5カ国中最低水準との調査もあります。導入と定着は別物であり、改善サイクルを止めないことが他社との差を生みます。
よくある質問
生成AIに社内データ・自社データを連携させるメリットは何ですか?
最大のメリットは情報探索時間の大幅な削減です。LINEヤフーは年間70〜80万時間の削減を目標にしており、提案書・マニュアル・過去のチャット履歴など散在する社内固有情報を、AIが即座に要約して提示できます。検索→要約→ドラフト作成までを1つの画面で完結できる点が特徴です。
「社内データ」と「自社データ」は何が違いますか?
ほぼ同義として使われます。「社内データ」は社員間で共有する文書・チャット・議事録など社内向けの情報を指すことが多く、「自社データ」は経営判断や顧客提案など会社全体が保有する固有情報を強調する文脈で使われやすい傾向です。RAG構築の対象としては両方とも同じ扱いになります。
自社データを使うと、情報漏洩のリスクはありませんか?
無料の生成AIサービスに直接機密情報を入力すると、利用規約上モデルの学習データに利用される可能性があります。一方で、Microsoft 365 CopilotやAzure OpenAI Service、ChatGPT Enterpriseなどの法人向けプランは、入力データを学習に使わないことが明記されています。RAG構築時はオプトアウト設定を確認したうえで、ステップ6の権限管理を実装すれば安全に活用できます。
導入にはどのくらいの期間がかかりますか?
特定部署でのPoC(概念実証)であれば1〜3か月で構築・検証が可能です。全社展開を含めると6〜12か月が目安です。期間を短縮する鍵は、ステップ1の目的設定と、ステップ2のデータ整備をどれだけ絞り込めるかにあります。
中小企業でも自社データの活用はできますか?
可能です。Azure OpenAI ServiceのAI Search、Google CloudのVertex AI Search、Dify、Notion AIなどのノーコード・ローコードツールを組み合わせれば、エンジニアが少ない中小企業でも数週間〜1か月でPoCに着手できます。まずは1部署・100文書からの開始を推奨します。
RAGとファインチューニングはどう違いますか?
ファインチューニングはモデル自体を自社データで再学習する手法で、開発コストが高く、データを更新するたびに再学習が必要です。RAGはモデルを学習し直さず、外部データベースから関連情報を引いてプロンプトに渡すため、コスト・更新頻度・根拠提示の3点で企業利用に向きます。詳細はLLMとRAGの違いで図解しています。
まとめ|社内データ活用は7ステップで現実解にできる
生成AIで社内データ・自社データを活用するには、Microsoft 365 CopilotやRAG構築などの現実的な選択肢を理解したうえで、目的を絞ったスモールスタートから始めるのが最短ルートです。
本記事の7ステップを再掲します。
- ステップ1: 目的の明確化と対象業務の選定
- ステップ2: 社内データの整備とクリーニング
- ステップ3: RAG(検索拡張生成)の構築
- ステップ4: スモールスタートによる段階的な展開
- ステップ5: 出力検証と最終確認フローの構築
- ステップ6: 権限管理と現場へのルール徹底
- ステップ7: 運用後の継続的な改善サイクル
LINEヤフーのSeekAIが年70〜80万時間削減を目指せたのは、PoC段階で98%の正答率を確認したうえで全社展開へ進んだからです。まず1部署・1ユースケース・100文書から始めれば、自社でも同じ道筋をたどれます。本記事を起点に、貴社の社内データ活用プロジェクトを動かしてみてください。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。