データ基盤とは?構築の7つのポイントとSnowflake・BigQuery比較【2026年版】
「データ基盤とは何か」を2026年版で完全解説。DWH/データレイク/Lakehouse/Data Meshの違いから、Snowflake・BigQuery・Databricks3大プラットフォーム比較、Apache Iceberg等の最新トレンド、メルカリ(BigQuery 1500データセット)・ZOZO(dbt Core連携)・セブン-イレブン(発注40%減)の実在事例、構築7ポイント、データ基盤エンジニアの役割・年収まで一気にわかります。

データ基盤とは|2026年版の直接回答
データ基盤とは、社内に散在するデータを収集・統合・蓄積・加工し、分析や AI 活用ができる状態に整えるシステム全体を指します。DWH(データウェアハウス)はその中核ですが、2026 年現在は「DWH/データレイク/Data Lakehouse/Data Mesh」の使い分けが論点で、特に Lakehouse + Apache Iceberg(オープンテーブルフォーマット) をコアに据える設計が主流です。
本記事を読むと次の 5 点がわかります。
- データ基盤の定義と DX 推進で不可欠な理由
- DWH/データレイク/Lakehouse/Data Mesh の違いと選び方(2026 年版)
- Snowflake/BigQuery/Databricks の比較と判断軸
- メルカリ・ZOZO・セブン-イレブン・日立大みか事業所の実在事例
- データ基盤構築の 7 つのポイントとデータ基盤エンジニアの役割・年収
なお、6 ステップの構築手順とツール選定の詳細は別記事「失敗しないデータ基盤構築の6ステップ|最適なアーキテクチャとツール選定」で取り上げています。本記事は「データ基盤とは」を起点とした全体像と事例カタログを担当します。
データ基盤とは?DX推進に不可欠な理由
データ基盤とは、企業内に点在する様々なシステム(SFA、CRM、販売管理、IoT センサーなど)からデータを収集・統合し、分析可能な状態に整えて蓄積するシステム全体です。
部門ごとに最適化された従来システムでは、データの連携ができず「データサイロ」が発生していました。データサイロを解消し、データドリブンな意思決定や AI の自律的なタスク処理を実現するための土台がデータ基盤です。
社内データを根拠に AI が回答する仕組み(RAG)の前提も、最終的にはデータ基盤の品質に依存します。RAG の判断軸については「LLMとRAGの違い徹底比較」も参考にしてください。
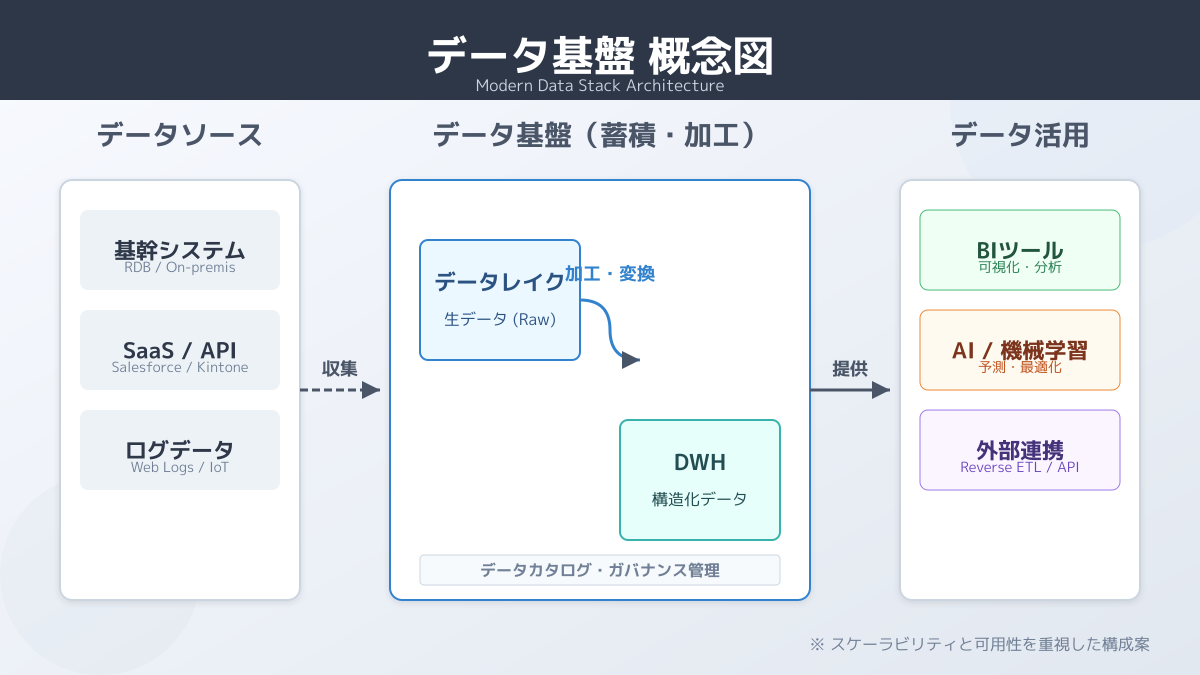
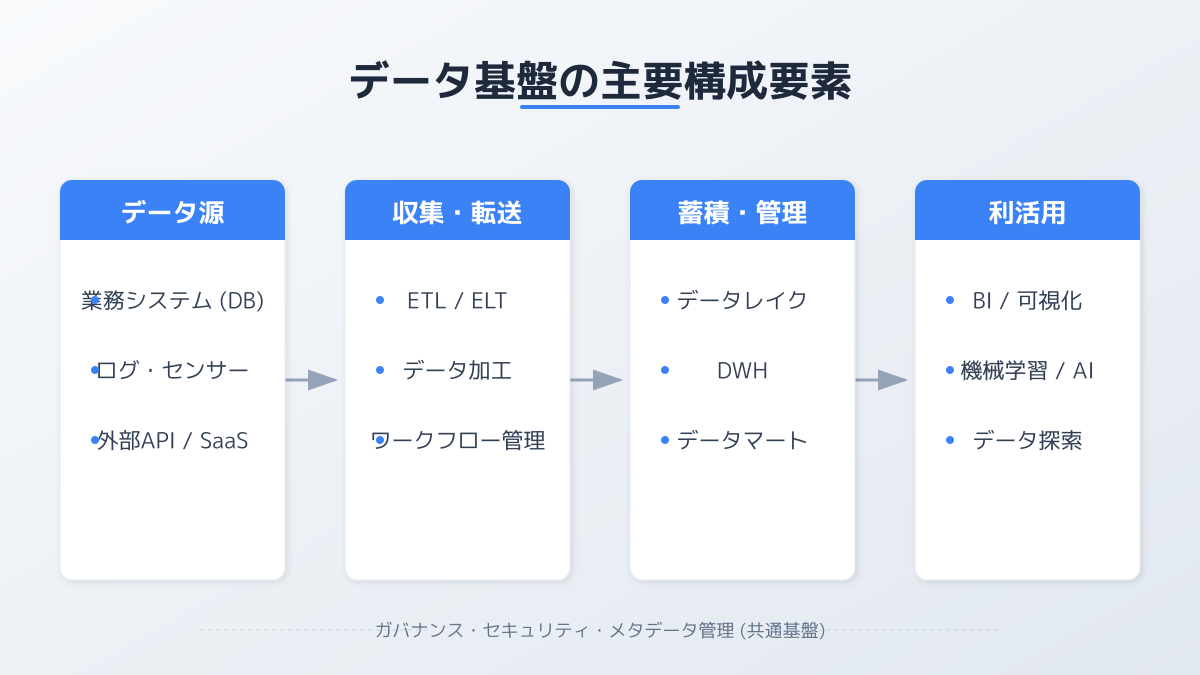
データ基盤 アーキテクチャの基本(4つの機能層)
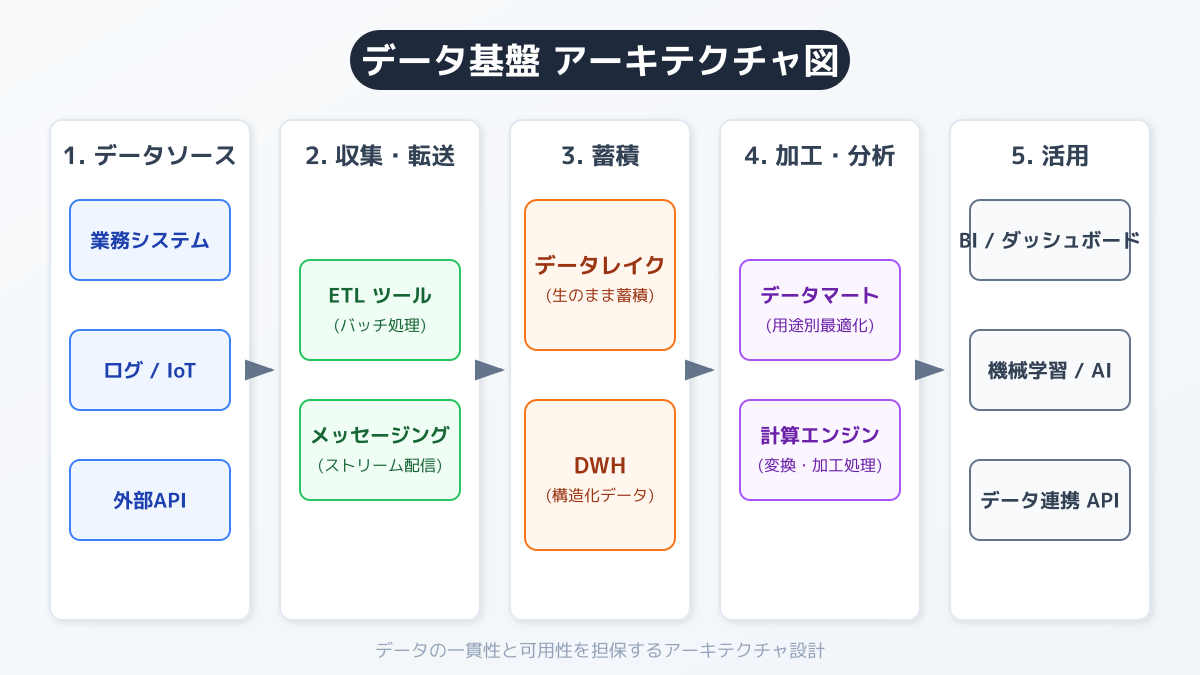
データ基盤 アーキテクチャは、データの流れに沿って主に 4 つの機能層で構成されます。
| 機能層 | 役割 | 代表ツール |
|---|---|---|
| データ収集 | 各システムからデータを抽出(ETL/ELT) | Fivetran、Airbyte、TROCCO®、Embulk |
| データ蓄積 | 生データの保管と分析用構造化 | データレイク、DWH、Lakehouse |
| データ加工 | クレンジング・変換・モデリング | dbt、Dataform、Apache Spark |
| データ活用 | 可視化・分析・AI 連携 | BI ツール、AI エージェント、ベクトルDB |
これらがクラウド上で連携することで、スケーラブルなデータ活用が可能になります。
DWH/データレイク/Lakehouse/Data Mesh の違い(2026年版)
データ基盤の蓄積層をどう設計するかは、2026 年の議論で最も論点になっています。代表的な 4 方式の違いを整理します。
| 方式 | 主な役割 | 得意なデータ | 採用が向くケース |
|---|---|---|---|
| DWH(データウェアハウス) | 構造化データの分析 | 売上・在庫など整形済みデータ | BI レポート中心の用途 |
| データレイク | 生データの大量保管 | ログ、画像、音声など非構造化 | AI 学習用データの保管 |
| Data Lakehouse | DWH + レイクの統合 | 構造化+非構造化を一元管理 | BI・AI・ML を 1 基盤で動かしたい |
| Data Mesh | 組織横断の分散管理 | 各ドメインがデータを「製品」として運用 | 大企業で部門ごとの自律性が必要 |
DWH/データレイク/Lakehouse は「どう保管・処理するか」という技術アーキテクチャですが、Data Mesh は「どう組織を設計するか」という社会技術アーキテクチャである点が決定的に異なります(参考:KDnuggets: Data Lake vs Data Warehouse vs Lakehouse vs Data Mesh)。
近年は「Lakehouse をコア基盤に据え、組織が大きくなったら Data Mesh の原則を重ねる」併用パターンが主流です。日本国内でも MUFG が Databricks Lakehouse を全社 AI 分析基盤として採用し、データサイエンティストの生産性向上を報告しています。
Apache Iceberg が変える 2026 年のデータ基盤
2025〜2026 年の最大の変化は、Apache Iceberg を中心とするオープンテーブルフォーマットの普及です。Iceberg はもともと Netflix が開発し Apache Software Foundation に寄贈された規格で、Parquet/ORC/Avro などの上に ACID トランザクション、スキーマ進化、Time Travel といった DWH 機能をデータレイクへ持ち込みます(参考:Snowflake: How Apache Iceberg Is Changing the Face of Data Lakes)。
主要プラットフォームの Iceberg 対応も急速に進んでいます。
- Snowflake: Iceberg テーブルをネイティブサポート、Open Catalog で外部書き込みも可能(公式ドキュメント)
- BigQuery: BigLake tables for Apache Iceberg として、Cloud Storage 上の Iceberg を BigQuery のマネージドテーブルと同等に扱える(Google Cloud 公式)
- Databricks: Apache Iceberg v3 の Public Preview を提供、Delta Lake と Iceberg の相互運用を強化(Databricks Blog)
データレイクハウス市場は 2024 年の 113.7 億ドルから 2031 年に 428.9 億ドルへ拡大(CAGR 18.5%) と予測され、組織の 85% が AI モデル開発に Lakehouse を活用していると報告されています。Iceberg を採用しておけば、将来 Snowflake・BigQuery・Databricks のどれにも乗り換え可能なベンダー非依存の基盤を構築できます。
データ基盤の主要プラットフォーム比較|Snowflake/BigQuery/Databricks
「データ基盤をクラウドで作る」と決めた時点で、現実の選択肢は Snowflake/BigQuery/Databricks の 3 強です。それぞれの得意領域を整理します。
| プラットフォーム | 強み | 主な向き | 注意点 |
|---|---|---|---|
| Snowflake | BI/SQL 分析の使いやすさ、運用負荷の少なさ、Snowpark で Python/Java 対応 | DWH 中心、データ共有(Data Sharing) | クレジット課金で同時実行制御が必要 |
| Google BigQuery | Google エコシステム連携、フルマネージド、ML(BQML)と Gemini 連携 | Google Cloud を主軸とする企業、広告/Web ログ分析 | スキャン量課金とスロット課金の使い分け設計が必要 |
| Databricks | AI/ML、ストリーミング、非構造化データに強い、Lakehouse のリファレンス実装 | データサイエンスや MLOps が主軸、マルチクラウド | SQL のみのチームには学習コストがやや高い |
3 つは Iceberg を介して相互運用が進んでおり、「最初は 1 つに寄せて、後で Iceberg 経由で連携する」のが現実的な選択戦略です。コスト・運用要件・将来の AI/ML 計画から判断してください。
なお、選定後の具体的な構築フローは「失敗しないデータ基盤構築の6ステップ」で詳述しています。
データ基盤構築を成功させる7つのポイント
データ基盤を構築し、現場で確実に運用していくための 7 つの重要ポイントを解説します。
1. データ収集と統合の最適化
データ基盤を構築する上で最初に直面する課題は、社内に散在するデータをどう集約するかです。SFA や CRM、人事システムなど、異なる形式のデータを一つの場所に統合することがデータ活用の第一歩となります。
各部門がどのようなデータを保有しており、それをどの程度の頻度で収集・更新すべきかを定義してください。初期段階でデータサイロを解消できなければ、後続の分析において正確な結果は得られません。統合された良質なデータは AI の精度も飛躍的に向上させます。最新の AI 活用イメージについては「AIエージェントとは?生成AIとの決定的な違いと2026年最新の活用事例」を参照してください。
2. データ品質の確保とクレンジング

どれほど大量のデータを集めても、欠損や誤りが含まれていれば分析結果の信頼性は損なわれます。入力規則が統一されていない顧客データなどがそのままシステムに流れ込むと、いわゆる「Garbage In, Garbage Out」の状態に陥ります。
自動化の範囲と手動補正のルールを決め、データが統合環境に入る前の段階で異常値を検知・除外する仕組みを組み込むことが必須です。整備されたデータから得たインサイトを報告する際は「Gensparkでスライド作成を自動化!AIで資料作成を半減させる7つの秘訣」を活用し、レポーティング業務自体も効率化することをおすすめします。
3. ビジネス要件に合わせたアーキテクチャ設計
アーキテクチャを具体化する際の判断ポイントは、処理のリアルタイム性とデータ量のスケーラビリティです。
製造業の IoT データのように即時性が求められる場合は、ストリーミング処理を前提とします。月次の売上集計が主目的であれば、夜間にまとめて実行するバッチ処理で十分です。自社の要件に対してオーバースペックな技術を選定すると無駄なコストが発生するため、費用対効果を慎重に見極めます。
4. モダンデータスタックによる拡張性の確保
将来のデータ増加やビジネス変化に耐えうる拡張性の確保も重要です。近年は、クラウドネイティブなマネージドサービスを組み合わせた「モダンデータスタック」が主流となっています。
ストレージとコンピューティングを分離する設計(Lakehouse の基本特性)により、データ量の増加に対して柔軟な対応が可能です。Fivetran で取り込み、Snowflake/BigQuery に蓄積し、dbt で変換、Looker/Tableau で可視化、というのが典型構成です。従量課金制のサービスが多いため、不要なデータの保持や非効率なクエリの実行を防ぐコスト管理のガバナンスが求められます。
5. 構築フローの設計と運用体制の確立

基盤構築にあたっては、最初から全社規模の巨大なシステムを目指すのではなく、特定の部門に絞ったスモールスタートが推奨されます。「どの業務課題を解決するためにデータ分析が必要か」から逆算して設計してください。
運用においてはデータの陳腐化を防ぐため、データの意味や所在をまとめた「データカタログ」を整備し、現場部門のデータ探索にかかる時間を削減します。
6. セキュリティとデータガバナンスの徹底

機密性の高い営業データなどを取り扱う場合、法令遵守の観点から厳格な管理が求められます。すべてのデータを一律に保護するのではなく、公開可能なデータと機密データを切り分け、適切なセキュリティレベルを設定します。
役職や担当業務に応じたアクセス権限(ロールベースアクセス制御)を実装し、現場の利便性を損なわずに情報漏洩リスクを最小限に抑えることが重要です。
7. 継続的な運用監視とパフォーマンス最適化
システムは一度構築して終わりではなく、データ量や利用ユーザーの増加に合わせて常に状態をアップデートする必要があります。
システム部門とビジネス部門が連携し、利用状況のモニタリング結果を共有してください。使われていないダッシュボードや不要なデータパイプラインを定期的に棚卸しすることで、運用負荷の肥大化を防ぎます。
データ基盤を活用した成功事例(実在企業4社)
データ基盤の構築によって、実際にどのような成果が得られるのか。公開情報のある実在企業の事例を 4 つ紹介します。
事例1:セブン-イレブン・ジャパン|AI発注で店舗の発注時間を約40%削減
セブン-イレブン・ジャパンは、各店舗の POS・在庫・販促データを Google Cloud の BigQuery に統合した全社データ基盤を構築。蓄積されたデータをもとに、天候・曜日特性・販売実績から需要予測を行う AI 発注システムを 2023 年から全店舗(約 21,000 店)に展開しました。
公式発表によれば、店舗における発注業務時間が約 40% 削減され、店舗従業員 1 人あたり 1 日約 35 分の業務時間が短縮されています。販売機会ロスと食品廃棄の同時削減を実現し、サステナビリティ指標の改善にもつながっています(出典:セブン-イレブン サステナビリティレポート /Google Cloud 導入事例)。
事例2:日立製作所 大みか事業所|IoT基盤で生産リードタイムを50%短縮
日立製作所の大みか事業所では、生産ラインの IoT センサー・RFID タグ・作業者の動線データを統合するデータ基盤「Lumada」を構築しました。「RFID 生産監視システム」「作業改善支援システム」「モジュラー設計システム」「工場シミュレーター」の 4 システムを連携させ、進捗のリアルタイム把握と工程改善のフィードバックループを確立しています。
結果、代表製品である情報制御システムの生産リードタイムを 180 日から 90 日へと 50% 短縮(設計 20%、調達 20%、製造 10% の内訳で削減)したと公式に発表しています。世界経済フォーラムの「Global Lighthouse Network(先進工場)」にも選出されました(出典:日立製作所ニュースリリース /MONOist 取材記事)。
事例3:メルカリ|BigQuery で 1,500 データセット・月間 800 名が利用する全社データ民主化
メルカリは、Google Cloud の BigQuery + TROCCO® をコアとするデータ基盤を運用し、社内のデータ民主化を進めています。公開資料によれば、運用規模は データセット 1,500 超、1 日あたりジョブ 30 万件超、月間アクティブユーザー 800 名超 に達します(出典:メルカリエンジニアリングブログ /primeNumber イベントレポート)。
特徴的なのは、データガバナンスとセルフサービス分析の両立です。Google Cloud 領域外の新規データ連携ごとに発生していたフルスクラッチ開発から脱却し、決済データと紐づけた営業活動分析を実現しています(参考:primeNumber: メルカリのデータ民主化とガバナンス向上)。
事例4:ZOZO|BigQuery + dbt Core で 3 種類のデータマートを使い分け
ZOZO は、オンプレ/クラウドのデータを BigQuery に連携し、全社共通データ基盤として運用しています。さらに dbt Core を導入し、用途に応じて アドホック分析向けワイドテーブル/特定システム向け安定データセット/長期利用可能な共通データ基盤 の 3 種類のデータマートを使い分けています(出典:ZOZO TECH BLOG /ZOZOTOWN を支える BigQuery(Speaker Deck))。
研究開発で TRY & ERROR のサイクルが速く、事前に SORTKEY や DISTKEY を決められない事情があったため、インデックスがなくても力技で高速計算できる BigQuery を中心に据えた点が示唆的です。
データ活用によるさらなる事例については「データ活用とは?社内DXを成功に導く6つのポイントとワークマン・コマツ等の企業事例」も併せてご確認ください。
データ基盤エンジニアとは|役割・スキル・年収相場(2026年版)
データ基盤を担うのは「データ基盤エンジニア(データエンジニア)」と呼ばれる職種です。データを「収集・蓄積・加工・分析」する一連の工程をスムーズに行えるよう設計・構築・運用する役割を担います。
データ基盤エンジニアの主な役割
- データパイプライン設計・開発: ETL/ELT 設計、Airflow/dbt/Fivetran 等での実装
- DWH/Lakehouse 設計: BigQuery/Snowflake/Databricks のスキーマ設計とコスト最適化
- データ品質管理: dbt test、Great Expectations、Monte Carlo 等での監視
- データガバナンス: アクセス制御、データカタログ、Lineage 管理
- AI/ML 連携: ベクトル DB、特徴量ストア、MLOps パイプラインの構築
必要スキルセット(2026年版)
| カテゴリ | スキル |
|---|---|
| 必須 | SQL、Python、Git、データモデリング、クラウド基礎(AWS/GCP/Azure) |
| DWH/Lakehouse | BigQuery、Snowflake、Databricks のいずれか深い経験 |
| 変換・パイプライン | dbt、Airflow、Fivetran/Airbyte/TROCCO® |
| コンテナ/IaC | Docker、Kubernetes、Terraform |
| 2026年の追加要件 | ベクトル DB、Apache Iceberg、LLM 連携パイプライン、RAG 構築知識 |
年収相場(日本市場)
公開求人情報や転職エージェント各社のレポートから、おおよその年収レンジは以下のとおりです。
- 経験 3 年未満(ジュニア): 450 万〜 650 万円
- 中堅(3〜7 年): 650 万〜 1,000 万円
- シニア/リード: 1,000 万〜 1,300 万円超
特に BigQuery/Snowflake/Databricks の設計経験+ MLOps/ベクトル DB 知識 を併せ持つエンジニアは市場価値が高く、データ基盤エンジニアの求人は前年比 30% 以上の増加が続いていると報告されています(参考:Levtech フリーランス: データエンジニア解説)。
よくある質問(FAQ)
Q1. データ基盤とDWHは何が違うのですか?
データ基盤はシステム全体の総称、DWH はそのうち「分析用に構造化したデータを蓄積する層」の名称です。データ基盤は「収集→蓄積→加工→活用」までを含む広い概念で、DWH(BigQuery、Snowflake 等)はその中の「蓄積」フェーズに位置する一要素です。データレイクや Lakehouse も同じ蓄積層の選択肢にあたります。
Q2. データ基盤構築にはどれくらいの期間とコストがかかりますか?
スモールスタート(1 部門・特定業務に絞ったスコープ)であれば 3〜6 ヶ月で立ち上げ可能です。月額コストは数十万円〜数百万円規模が一般的で、データ量・利用人数・クエリ頻度で変動します。全社規模の Lakehouse 構築は 1〜2 年がかりで、初年度の投資総額が数千万〜数億円になるケースもあります。具体的な手順は「失敗しないデータ基盤構築の6ステップ」で詳述しています。
Q3. Lakehouse と DWH のどちらを選ぶべきですか?
「AI/ML を本格的に動かしたい」「非構造化データも分析したい」のであれば Lakehouse、「BI レポートと SQL 分析のみ」であれば DWH が現実解です。ただし 2026 年は Snowflake/BigQuery/Databricks が Apache Iceberg をネイティブサポートしており、最初は DWH 中心で立ち上げて、後から Lakehouse 機能を足す経路も現実的になっています。
Q4. Apache Iceberg は今すぐ採用すべきですか?
新規構築であれば積極的に検討する価値があります。Snowflake/BigQuery/Databricks の 3 強がすべて Iceberg を正式サポートし、特定ベンダーへのロックインを避けられるためです。既存基盤からの移行は段階的に進め、まずは新しいデータドメインから Iceberg で書き始めるのが定石です。
Q5. データ基盤エンジニアとデータサイエンティストの違いは?
データ基盤エンジニアは「データを使える状態にする」役、データサイエンティストは「データから示唆を導く」役です。エンジニアはパイプライン構築・DWH 設計・データ品質管理が中心で、サイエンティストは統計分析・機械学習モデル開発が中心です。組織が大きくなると ML エンジニア・アナリティクスエンジニアといった中間職種も登場します。
Q6. 中小企業でもデータ基盤は構築すべきですか?
規模に関係なく「業務課題が明確」であれば構築価値があります。BigQuery/Snowflake はクラウド従量課金で初期投資が小さく、月数万円から始められます。重要なのは規模ではなく「何の意思決定を高速化したいか」の明確化です。スモールスタートで成果を出し、段階的に拡張する戦略が中小企業には特に有効です。
まとめ
データ基盤の構築は、企業の DX 推進において長期的な競争優位性を確立するための不可欠な投資です。本記事で解説した「DWH/データレイク/Lakehouse/Data Mesh の使い分け」「Snowflake/BigQuery/Databricks の選定」「Apache Iceberg を中心とするオープン化トレンド」「データ品質と拡張性」を押さえることで、失敗のリスクを最小限に抑えられます。
セブン-イレブン(発注 40% 削減)・日立大みか事業所(リードタイム 50% 短縮)・メルカリ(BigQuery 1,500 データセット)・ZOZO(dbt Core × 3 種マート)のように、明確なビジネス課題から逆算してスモールスタートで実証し、Lakehouse などの拡張性の高い基盤に育てていくアプローチが、2026 年に成果を出すデータ基盤の王道です。
まずは自社のビジネス課題を明確にし、目的から逆算したスモールスタートでデータ活用の一歩を踏み出してください。具体的な構築ステップは「失敗しないデータ基盤構築の6ステップ」で詳述しています。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。