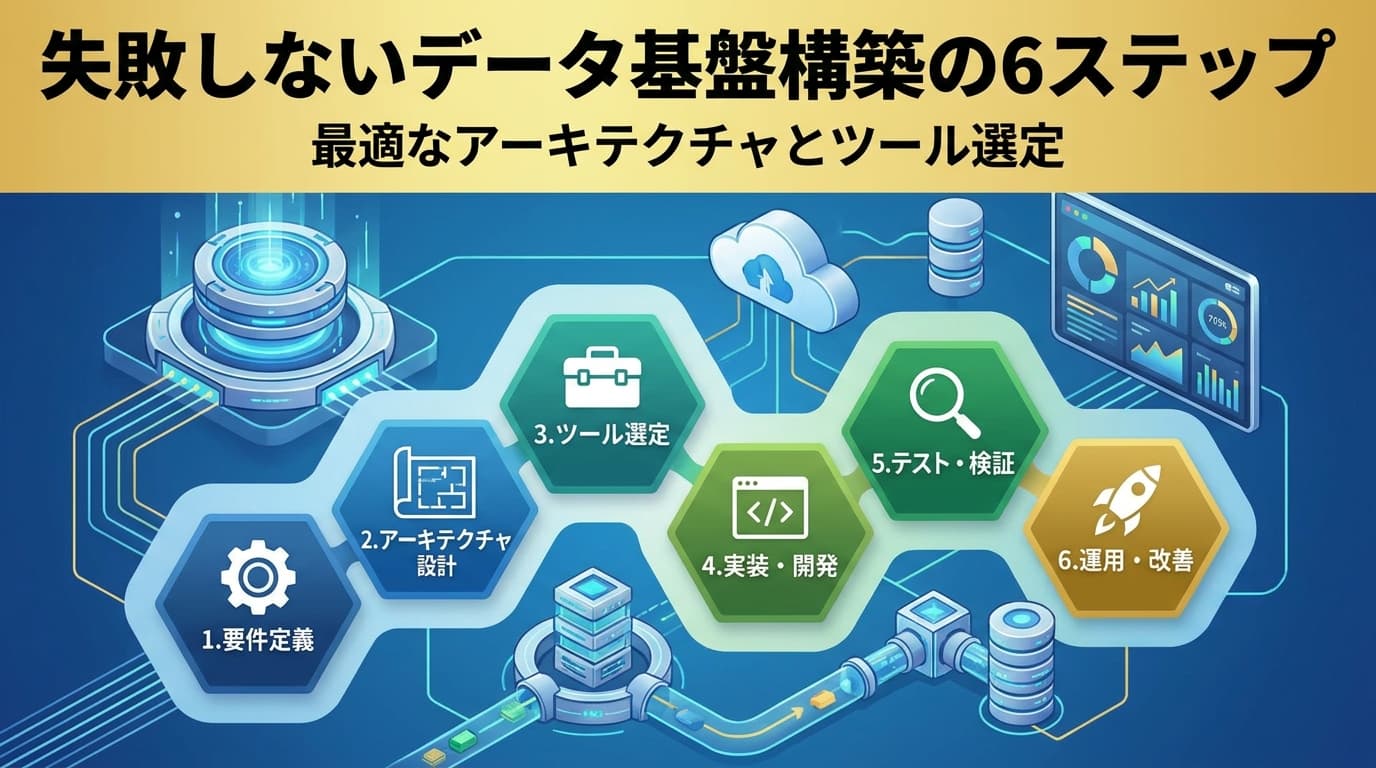
データ基盤構築の6ステップ|アーキテクチャ設計とDWH選定の進め方【2026年版】
データ基盤構築の進め方を「6ステップ」で具体化。要件定義・スモールスタート設計・アーキテクチャとDWH選定(Snowflake/BigQuery/Databricks/Redshift)・データ基盤エンジニア体制・ガバナンス・セキュリティを、2026年のモダンデータスタック動向に沿って実務担当者向けに解説します。
データ基盤構築で失敗しないための最大のポイントは、データの収集を目的化せず、現場のビジネス課題から逆算してアーキテクチャを設計することです。
データ活用が企業の競争力を左右する現代において、効果的なデータ基盤の構築は不可欠です。しかし、目的が曖昧なまま進めると、多大なコストをかけても期待する成果が得られないケースが後を絶ちません。本記事では、AI連携を見据えた目的設定から、現場で活用される運用設計、最適なツール選定、そして継続的なガバナンス維持まで、失敗しないデータ基盤構築の6ステップを具体的に解説します。この記事を読むことで、貴社に最適なデータ基盤を構築し、データドリブンな意思決定を実現するためのロードマップが得られます。
ステップ1:目的・要件定義とAI連携の検討

業務課題から逆算するデータの明確化
データ基盤構築において最初に押さえるべきポイントは、データを「何のために使うのか」という目的の明確化です。単に社内に散在するデータを一箇所に集約するだけでは、投資対効果を得ることはできません。特に近年は、蓄積したデータをAIエージェントやLLM(大規模言語モデル)と連携させ、業務の自動化や意思決定の高度化を図るケースが主流となっています。
そのため、最初のステップとして「どの業務課題を解決するために、どのようなデータが必要か」を逆算して定義することが重要です。たとえば、営業部門の提案活動を効率化したい場合、過去の商談履歴、顧客の属性データ、製品の仕様書などが必要になります。これらの要件を初期段階で洗い出すことが、プロジェクト成功の鍵を握ります。
拡張性と非構造化データの扱い
データ基盤を設計する際、将来的な拡張性とセキュリティのバランスが重要な判断ポイントとなります。自社のデータ量やリアルタイム性の要件に合わせて、データを適切に管理する必要があります。
ここで特に考慮すべきは、非構造化データ(テキスト、PDF資料、音声ログなど)の扱いです。AIによる議事録作成や資料要約、社内情報の検索などを想定する場合、これらの非構造化データをいかに効率よく蓄積・処理できるかが問われます。AIエージェントが自律的に社内データを参照してタスクを実行する未来を見据え、APIの連携容易性やデータフォーマットの標準化を初期段階で検討することが不可欠です。AIが自律的に業務を遂行する仕組みや最新動向については、AIエージェントとは?生成AIとの決定的な違いと2026年最新の活用事例をわかりやすく解説 を参考にしてください。
ステップ1の要点
最初のフェーズで押さえるべき要点は以下の3点です。
- 目的からの逆算設計: AI活用や業務効率化など、最終的なアウトプットから逆算して必要なデータソースと要件を定義する
- 拡張性を備えたデータ管理: 構造化データだけでなく非構造化データも扱い、外部のAIツールと柔軟に連携できる環境を整備する
- 現場との合意形成: 何を解決するための基盤なのか、関係者間で目的を共有し、投資対効果を明確にする
ステップ2:現場要件に直結したスモールスタート設計
システム部門が主導して大規模な基盤を構築したものの、現場のビジネス部門で全く使われないという失敗は珍しくありません。このステップでは、現場で実際に活用されるデータ基盤を作るための基本事項と、小さく検証を始める設計のポイントを整理します。

データを集めることを目的化しない
データ基盤構築を進める際、最も陥りやすい罠は「とりあえず社内のデータをすべて集約する」というアプローチです。データを集めること自体が目的化すると、莫大なコストと時間がかかるだけでなく、最終的に誰が何の目的で使うのかが曖昧になります。
まずは、現場の担当者やマネジメント層が「どのような意思決定を行いたいのか」「そのためにどの指標(KPI)を可視化する必要があるのか」を具体化します。売上分析、在庫最適化、あるいはマーケティング施策のROI測定など、具体的なビジネス課題を起点にすることで、収集すべきデータの種類と鮮度が自ずと決まります。
小さな成功体験を積むアプローチ
要件が明確になったら、初期段階から完璧なシステムを目指すのではなく、特定の部署や単一のプロジェクトに絞って基盤の導入を行うスモールスタートを推奨します。
たとえば、「まずはマーケティング部門のWebログとMAツールのデータだけを連携させて可視化する」といった具合に範囲を限定します。小さな成功体験を積み重ね、現場からのフィードバックを得ながら段階的に全社展開していくアプローチが、リスクを最小限に抑える有効な手段です。
データの信頼性を保つ自動化
基盤の構築と並行して、運用時のデータ品質を維持する仕組みも設計します。入力元のシステム仕様が変更されたり、欠損値が混入したりすると、基盤上のデータの信頼性は一気に低下します。これを防ぐため、データの抽出・変換・書き出し(ETL)のプロセスにおいて、自動的なデータクレンジングとエラー検知の仕組みを組み込む必要があります。
さらに、分析結果をまとめる際、 【2026年版】Gensparkでスライド作成を自動化!AIで資料作成の工数を半減させる7つの秘訣 などのAIツールを活用することで、レポーティングや資料作成の工数を大幅に削減し、本来のデータ分析業務に集中する環境を整えることができます。
ステップ3:データ基盤アーキテクチャの設計とツール選定
データ基盤構築において、要件定義に続く重要な要素が「アーキテクチャ設計とツール選定」です。どれほど精緻な要件を定義しても、システム構成が不適切であればパフォーマンス低下やコスト超過を招きます。
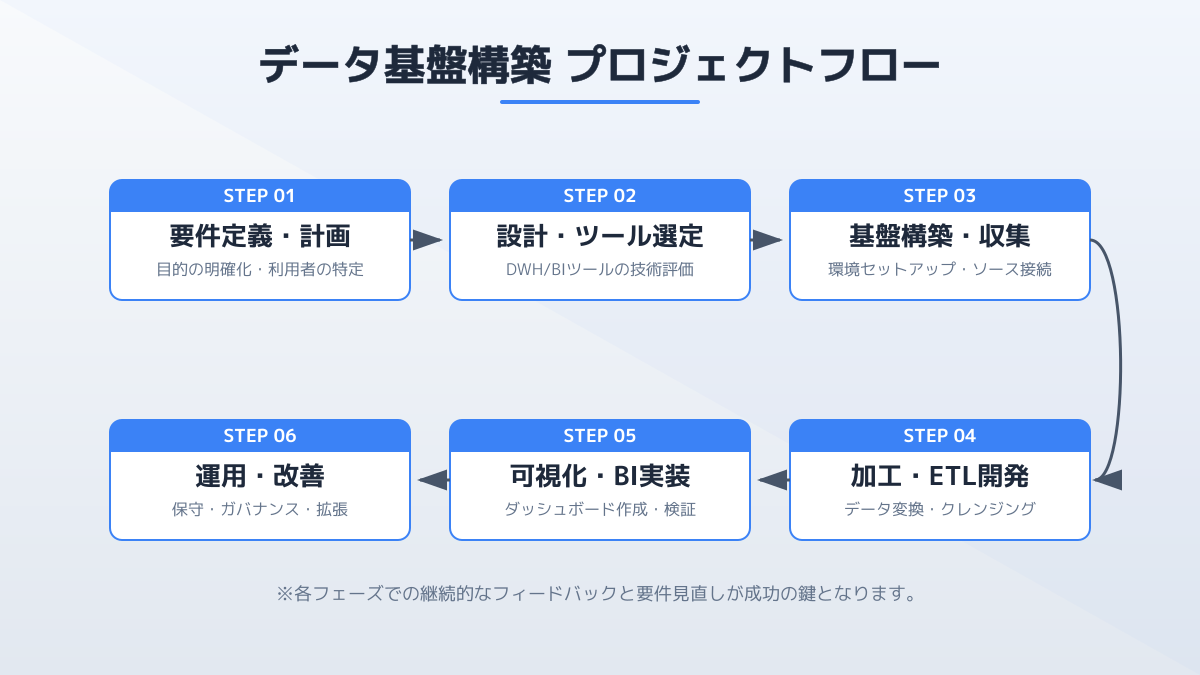
アーキテクチャのサンプル構成
近年のデータ基盤アーキテクチャは、クラウドサービスを組み合わせた「モダンデータスタック」が主流です。以下に代表的なサンプル構成を示します。
- データソース: 基幹システム、SaaS(Salesforceなど)、Webログ
- データ抽出・ロード(EL): FivetranやAirbyte、国内ではTROCCO(株式会社primeNumber)などのELTツールを利用し、データを加工せずにDWHへ転送
- データウェアハウス(DWH) / データレイク: BigQueryやSnowflake、Databricks(レイクハウス型)に生データを蓄積
- データ変換(T): dbtなどのツールを用いて、DWH内で分析用のデータマートへ変換
- 可視化・AI連携(BI / AI): TableauやLookerでの可視化、または社内LLMとのRAG(検索拡張生成)連携
この「ELT(抽出・ロード・変換)」アプローチにより、データの取り込みと加工を分離でき、拡張性の高いアーキテクチャが実現します。
2026年のモダンデータスタック動向:Fivetran×dbt統合と再編
ツール選定の前提として押さえておきたいのが、モダンデータスタック領域で進む再編です。2025年10月、ELTツールの代表格であるFivetranと、データ変換のデファクトスタンダードであるdbt Labsが合併を発表し、規制当局の承認を経て統合へ向かっています(クロージング前は両プロダクトとも独立稼働を継続)。これにより、抽出・ロードと変換の機能が単一ベンダー配下で連携を深める方向にあります。
また、AirbyteもReverse ETL(Data Activation)をv2.0でGAし、Fivetranが2025年5月に買収したCensusと同様の「逆方向ETL」を含む統合プラットフォーム化が進んでいます。「ベスト・オブ・ブリードを点で組み合わせるモダンデータスタック」から、「単一ベンダーで主要機能を統合するプラットフォーム」へとトレンドが移行しつつある点は、ツール選定時に必ず把握しておくべき変化点です。
代表的なDWHツールの比較と選定基準
ツールを選定する際の判断基準は、大きく「拡張性」「運用負荷」「コスト構造」の3つです。特にデータ基盤の中心となるDWHの選定は、プロジェクトの成否を分けます。代表的なクラウドDWH/レイクハウスの比較は以下の通りです。
| DWH/レイクハウスツール | 特徴と最適なユースケース | コスト構造 |
|---|---|---|
| Google BigQuery | フルマネージド・サーバーレスでクラスタ管理が不要。BigQuery MLとの親和性が高く、Google Cloud中心の環境に最適。 | スキャンしたデータ量に基づく従量課金(オンデマンド)と、定額のCapacity課金を選択可能。 |
| Snowflake | クラウドプロバイダー(AWS, Azure, GCP)に依存しないマルチクラウド対応。コンピュート(仮想ウェアハウス)とストレージが完全分離。データ共有・マーケットプレイスが強み。 | コンピュートの稼働秒数に応じたクレジット課金。処理を止めればコストを抑制できる。 |
| Amazon Redshift | AWSエコシステム(S3, Glue, Lake Formation, Kinesis, IAM)との連携が強力。RA3ノードに加えServerlessオプションあり。 | プロビジョンド(インスタンス稼働時間)またはServerless(RPU使用量)から選択。 |
| Databricks | データレイクとDWHを統合する「レイクハウス」型。Apache Sparkベースで大規模ETL・MLワークロードに強い。Unity Catalogでガバナンス統合。 | DBU(Databricks Unit)ベースの稼働時間課金。AWS/Azure/GCPいずれでも稼働可能。 |
エンジニアのみが操作するのか、あるいは営業やマーケティングの担当者など非エンジニアも日常的にSQLを叩くのかによって、選ぶべきツールのユーザーインターフェースや運用負荷は異なります。BIダッシュボードや分析中心ならSnowflake/BigQuery、機械学習・大規模データエンジニアリング中心ならDatabricks、AWS環境への密結合が前提ならRedshiftが第一候補となります。自社のITリテラシーと既存インフラに合わせた環境を見極めることが重要です。
リアルタイム性とコストのバランス
アーキテクチャを決定する上でのもう一つの判断ポイントは、リアルタイム性の要件です。 すべてのデータを数秒単位でリアルタイム処理しようとすると、ストリーミング基盤の構築が必要となり、開発・運用コストが跳ね上がります。現場の業務において「日次でのバッチ処理で十分なデータ」と「リアルタイム性が必須なデータ(例:金融取引の異常検知など)」を厳密に仕分け、コストと要件のバランスを取ることが求められます。
ステップ4:データ基盤エンジニアの確保と体制構築

データ基盤エンジニアの役割
優れたアーキテクチャや最新のツールを導入しただけでは、データは継続的なビジネス価値を生み出しません。ここで中核となるのが、データ基盤エンジニアの存在です。
データ基盤エンジニアは、データの収集、加工、蓄積、そして活用部門への提供に至るデータパイプライン全体を設計・保守する役割を担います。単にシステムを構築するだけでなく、データの品質を担保し、データサイエンティストやビジネス部門のユーザーが分析しやすい状態を維持することが求められます。構築の初期段階から運用フェーズを見据え、自社のビジネス要件に合わせた専門人材を確保することが不可欠です。
内製化と外部委託の判断
体制を構築する際、最も重要な判断ポイントは「内製化」と「外部委託(アウトソーシング)」のバランスです。
すべての開発・運用を自社リソースで行う内製化は、ビジネス環境の変化や社内の細かな要望に対して迅速に対応できるメリットがあります。一方で、クラウドインフラや分散処理技術に精通した高度なデータ基盤エンジニアを社内で育成・採用するには、多大な時間とコストがかかります。
外部委託を活用する場合は、初期の構築スピードを劇的に上げられる反面、社内にノウハウが蓄積されにくいという明確な課題が生じます。そのため、コアとなるアーキテクチャ設計やデータガバナンスの策定は社内のリードエンジニアが担い、定常的な運用保守や特定技術の実装フェーズは外部パートナーに委託するなど、ハイブリッドな体制を選択することが現実的です。
属人化を防ぐ運用設計
データ基盤を現場で運用する際は、特定のエンジニアへの依存(属人化)を防ぐ仕組みづくりが不可欠です。
データソースの仕様変更やパイプラインの改修履歴をデータカタログなどを活用して常に最新の状態に保つことで、誰でもシステムの状況を把握できるようになります。ドキュメントの継続的な更新と標準化を徹底することが、持続可能な運用の基盤となります。
ステップ5:データガバナンスと改善ルールの策定
データ基盤は、システムを完成させて本番環境にリリースした時点がゴールではありません。構築後の継続的な活用と価値創出を支える「ガバナンスの維持」こそが、運用を定着させる最重要項目です。
全社的なガバナンスルールの統一
データ基盤を形骸化させず、組織全体でデータを活用し続けるためには、強固なガバナンス体制が不可欠です。各部門が独自のルールでデータを加工・保存し始めると、全社で統一された指標が失われ、意思決定に悪影響を及ぼします(データのサイロ化)。
これを防ぐためには、「誰が・どのデータに・どのような権限でアクセスできるか」というルールを明確に定義し、データの定義や命名規則を標準化する必要があります。システム的な権限管理だけでなく、指標の計算ロジックを全社で統一し、認識のズレを防ぐことが、信頼性の高いデータ基盤を維持するための土台となります。
データスチュワードとカタログの整備
現場で運用する際、最も陥りやすい失敗は「データの意味や出所が分からず、誰も使わなくなる」という事態です。これを防ぐための注意点として、以下のルール策定が効果的です。
- データスチュワードの配置: 各データドメインに対して、データの品質と定義に責任を持つ管理者(データスチュワード)を配置します。
- データカタログの導入: データの出所、更新頻度、カラムの意味を辞書化し、現場のユーザーが自律的にデータを検索・理解できる環境を整えます。
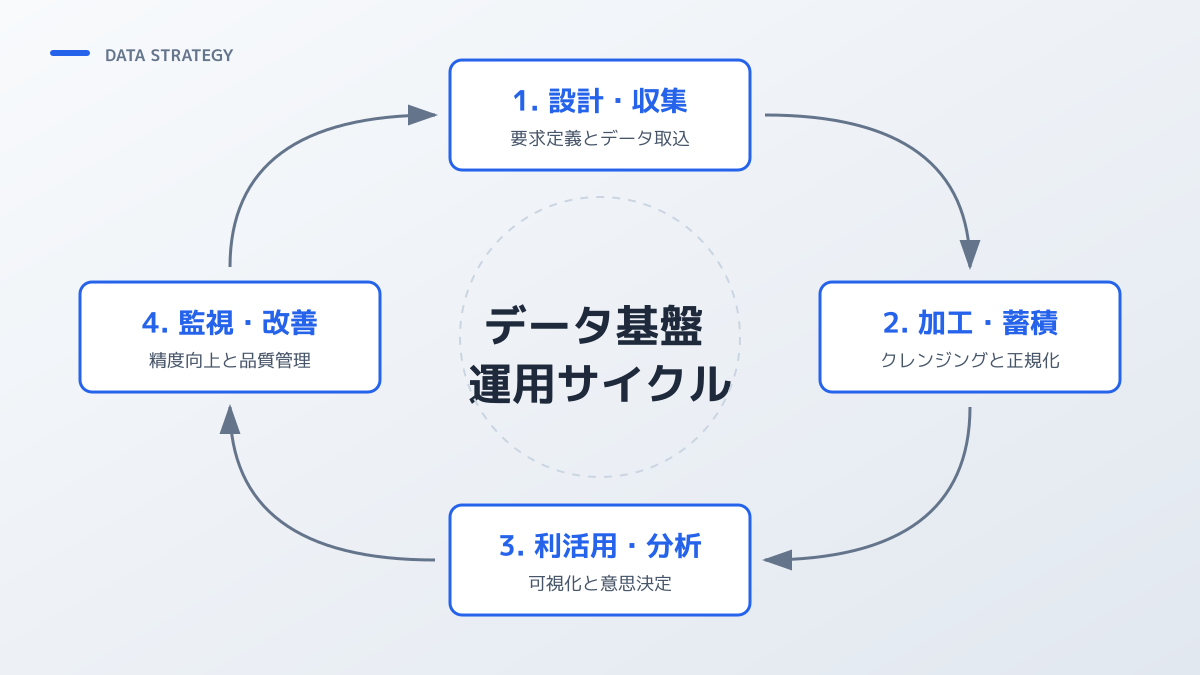
継続的な改善サイクルの確立
ビジネス環境の変化に伴い、必要とされるデータソースや分析要件は常に変化します。現場からのフィードバックを定期的に収集し、利用頻度の低いデータパイプラインを停止してクラウドコストを最適化したり、逆に需要の高い外部データを新たに取り込んだりする柔軟な対応が必要です。
システムとしての堅牢性と、ビジネス要求に対する俊敏性を両立させる改善サイクルを築くことが、投資対効果を最大化するための要点となります。
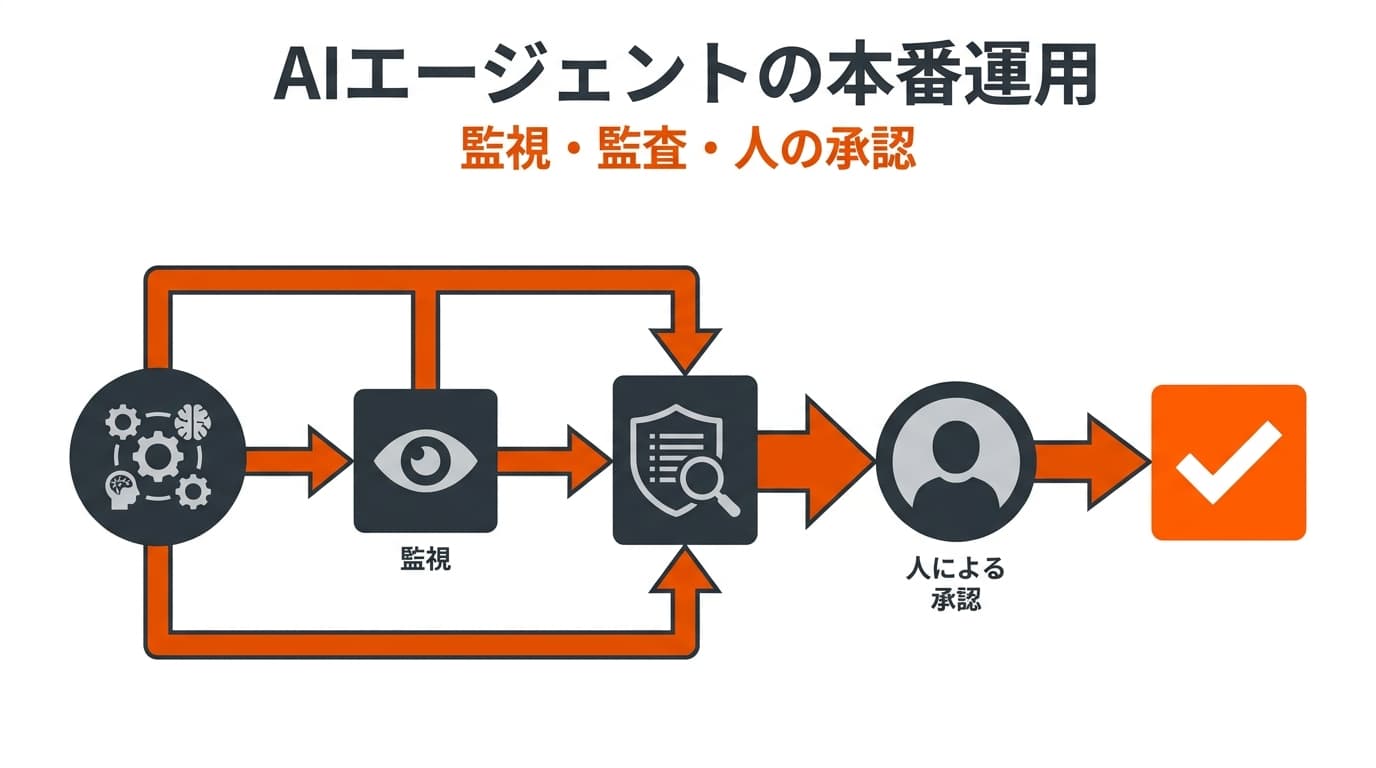
ステップ6:セキュリティ強化と品質管理の自動化
データ基盤構築における最後のステップは、強固なセキュリティの確立と品質モニタリングの自動化です。安全でクリーンなデータ環境を維持することで、初めてAIや分析ツールが正確に機能します。
最小特権の原則とアクセス制御
データを安全に活用するためには、各データの責任者(データオーナー)を明確にした上で、業務上必要なデータにのみアクセスを許可する最小特権の原則をシステムに組み込みます。
特に、個人情報や機密データへのアクセスは厳密に制御し、操作ログを監査可能な状態に保つ必要があります。一方で、セキュリティを重視するあまり利便性を損なうと、現場が非公式なツールを利用するシャドーITを誘発するリスクがあります。安全かつ使いやすいデータアクセス環境をバランスよく維持することが重要です。
データ品質管理の自動化
データ基盤の信頼性は、蓄積されるデータの品質に直結します。手作業でのデータチェックには限界があるため、品質管理のプロセスを自動化することが不可欠です。
具体的には、データの欠損値や異常値、フォーマットの不整合を自動的に検知する仕組みをデータパイプラインに組み込みます。また、データ連携の遅延や処理エラーが発生した際に、即座に管理者にアラートを通知するモニタリング体制を構築します。これにより、問題の早期発見と迅速な対応が可能になり、常にクリーンなデータをビジネス部門に提供し続けることができます。
障害時のインシデントレスポンス
万が一、データ連携の障害やセキュリティインシデントが発生した場合に備え、復旧手順(インシデントレスポンス)を事前に標準化しておくことも重要です。システム停止によるビジネスへの影響を最小限に抑えるため、継続的な監視体制と迅速な復旧プロセスを整備することが、強固なデータ基盤を支える最後の砦となります。
データ基盤構築に関するよくある質問
データ基盤の構築にはどれくらいの期間と費用がかかりますか?
構築する規模や連携するシステムの数によって大きく異なりますが、スモールスタートであれば3〜6ヶ月、数百万円程度から検証を開始できます。全社規模のデータ基盤アーキテクチャを完成させるには、数年単位の計画と数千万円規模の投資が必要になるケースが一般的です。
エンジニアがいない企業でもデータ基盤を構築できますか?
可能です。初期段階では外部のベンダーやコンサルタントに構築を委託し、同時に社内のIT担当者を育成するハイブリッドな進め方が推奨されます。また、フルマネージドなクラウドツールを選定することで、運用に必要な専門知識のハードルを下げることもできます。
データ基盤とAIの連携はどのタイミングで検討すべきですか?
要件定義(ステップ1)の段階で必ず検討しておくべきです。後からAI連携を追加しようとすると、非構造化データの扱いやAPI連携の仕様が合わず、アーキテクチャを根本から見直す手戻りが発生するリスクが高まります。AIエージェントの活用については【2026年版】プロンプトとは?意味から学ぶプロンプトエンジニアリング入門|AIエージェントの作り方とLLM活用事例や【週5時間の工数削減】ビジネスを自動化する身近なAI活用事例|AIエージェント導入ガイドも参考にしてください。
Fivetranとdbtが合併すると、現在のモダンデータスタック構成への影響はありますか?
2025年10月にFivetranとdbt Labsの合併が発表されましたが、規制当局の承認を待つ間、両プロダクトは独立稼働を継続します。短期的には既存のFivetran+dbt構成への影響は限定的ですが、中長期的には両者の連携機能が深化し、単一プラットフォーム化が進む可能性が高い点を踏まえてアーキテクチャを設計することを推奨します。
まとめ
データ基盤構築は、単なるシステム導入ではなく、企業のデータ活用文化を根付かせるための戦略的な取り組みです。本記事では、失敗しないデータ基盤構築のための6つのステップを解説しました。
- 目的・要件定義とAI連携の検討
- 現場要件に直結したスモールスタート設計
- データ基盤アーキテクチャの設計とツール選定
- データ基盤エンジニアの確保と体制構築
- データガバナンスと改善ルールの策定
- セキュリティ強化と品質管理の自動化
これらのステップを確実に押さえ、現場のフィードバックを取り入れながら段階的に拡張を進めることで、データ基盤は持続的なビジネス価値を生み出す強力な資産となります。データドリブンな意思決定を組織に定着させ、競争優位性を高めていきましょう。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。