AIエージェントの本番運用ガイド|監査ログ・可観測性・ヒューマンインザループで安全に統制する【2026年版】
社内に導入したAIエージェントを本番で安全に動かし続けるために効くのは、「可観測性(何をしたか追える状態)・権限の統制・人による確認」をセットで設計することです。チャットでの利用と違い、エージェントは自分で判断してツールを呼び出し、実際の処理を実行します。だからこそ、実行内容を後から追跡でき、与える権限を絞り、重要な判断は人が承認する仕組みを最初から組み込む必要があります。
この記事では、PoC で「動いた」段階から本番運用へ進めるために設計すべき監視・統制を、4つの柱に整理して解説します。特定の製品マニュアルではなく、どのAIエージェント基盤にも共通する運用設計の考え方を中心にまとめています。
この記事でわかること
- なぜ「動いた」だけでは本番運用にならないのか
- 本番運用で設計する4つの柱(可観測性・権限統制・人の確認・コスト/品質監視)
- 監査ログと可観測性で「何をしたか」を追える状態の作り方
- 実行環境と権限を絞る具体的な方法(サンドボックス・短命の認証情報)
- 本番化までに確認するチェックリスト
なぜ「動いた」だけでは本番運用にならないのか
結論として、AIエージェントの本番運用は「デモで成功すること」ではなく「想定外が起きても被害を抑え、原因を追える状態を保つこと」が目標になります。エージェントは自律的にツールを呼び出すため、便利さと同じだけ「意図しない操作」「誤ったデータの更新」「想定外のコスト発生」といったリスクを伴うからです。
チャットでの利用なら、出力をそのつど人が見て判断できます。しかしエージェントは、複数の手順を自分で進め、外部システムへの書き込みやAPI呼び出しまで実行します。1回の実行で何が起きたかを後から再現できなければ、トラブル時に原因を特定できません。PoC が本番に届かない構造的な要因は、AI PoC死を回避する7つの原因でも整理しています。本番運用では、この「追跡できる状態」をあらかじめ用意しておくことが出発点になります。
本番運用で設計する4つの柱
AIエージェントを本番で運用するときに設計すべき要素は、大きく次の4つに整理できます。どれか1つではなく、4つをセットで組むことが安全な運用につながります。
| 柱 | 目的 | 主な手段 |
|---|---|---|
| 1. 可観測性・監査ログ | 何をしたかを追跡・再現できる | トレース取得、ツール呼び出しの記録、サービスアカウント別の監査ログ |
| 2. 権限と実行環境の統制 | できることを必要最小限に絞る | サンドボックス、最小権限、短命の認証情報、通信経路の制御 |
| 3. ヒューマンインザループ | 重要な判断を人が承認する | リスク段階別の承認、エスカレーション設計 |
| 4. コスト・品質の監視 | 使いすぎと品質劣化を早期に検知 | 利用量/コストの可視化、出力品質のモニタリング、ドリフト検知 |
以下、それぞれを具体的に見ていきます。
柱1:可観測性と監査ログ
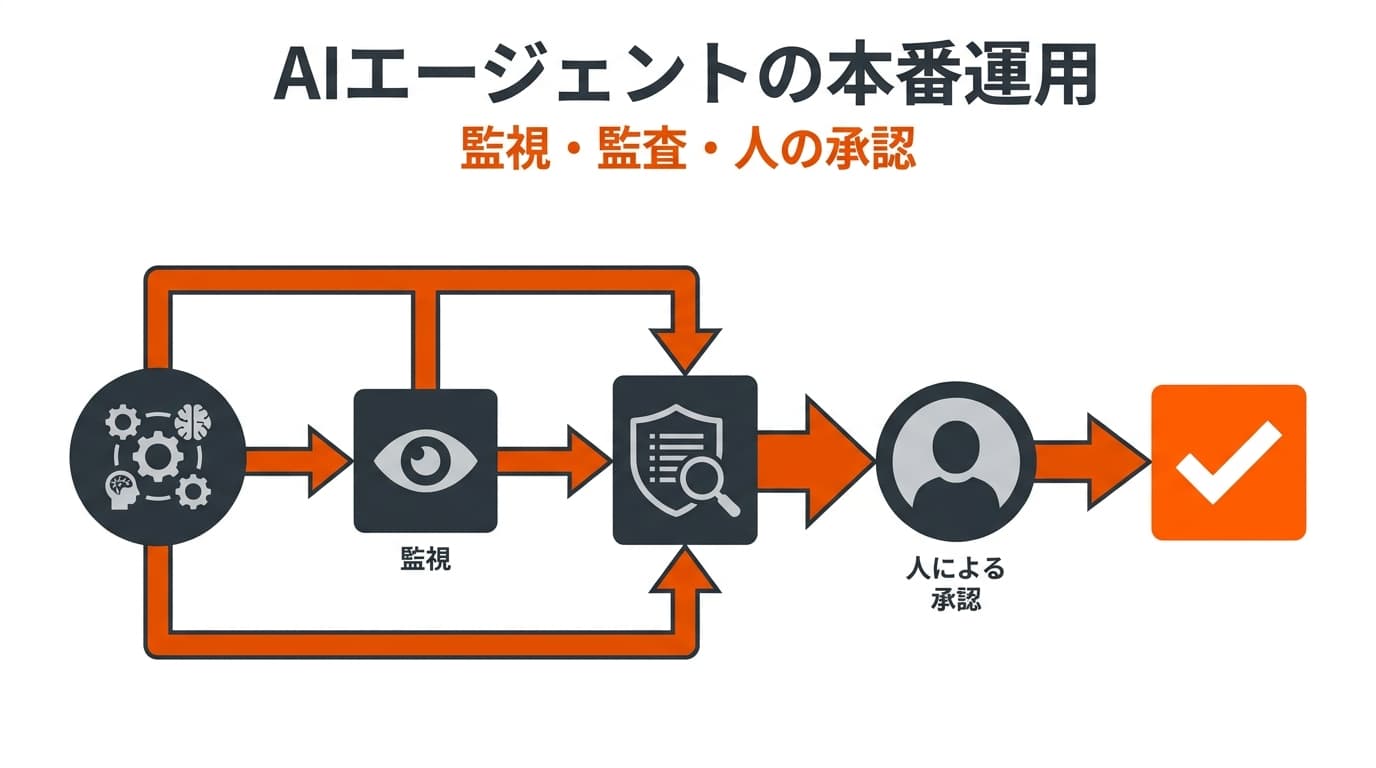
最優先で用意したいのが、エージェントの動きを後から追える可観測性(オブザーバビリティ)です。具体的には、推論の各ステップとツール呼び出しを1件ずつトレースとして記録し、誰が・いつ・どのツールを・どの引数で実行したかを残します。
近年は OpenTelemetry を軸に、エージェントのトレースを既存の監視基盤へ取り込む構成が標準になりつつあります。加えて、ワークロードごとに「サービスアカウント」を割り当てると、共有のAPIキーではなく実行主体ごとに監査ログを残せます。たとえば Claude のプラットフォームでは、各ワークロードに固有のID・ロール・監査証跡を持たせるサービスアカウントが用意され、すべてのやり取りがその単位で監査ログに記録されます。これにより、問題が起きたときに「どの処理が・何をしたか」をたどれるようになります。可観測性は後付けではなく、運用開始前に組み込む前提で設計してください。
柱2:権限と実行環境を絞る
次に、エージェントに与える権限と実行環境を必要最小限に絞ります。考え方は「何でもできる便利な助手」ではなく「決められた範囲だけを任せる担当者」に近づけることです。
実行環境については、ツールを動かすサンドボックスを自社の管理下に置く構成が広がっています。たとえば Claude Managed Agents では、オーケストレーションは提供側に残しつつ、ツールを実行するサンドボックスを自社インフラや Cloudflare・Daytona・Modal・Vercel などの管理プロバイダー上で動かし、計算資源・実行イメージ・ネットワークポリシーを自社で制御できます(2026年5月時点で公開ベータ)。機密ファイルやリポジトリを自社の境界内にとどめたまま動かせるのが利点です。社内システムへ安全につなぐ仕組みはMCP(Model Context Protocol)とは、外部に公開せず社内ネットワークへ接続する考え方はMCPトンネルで社内システムへ安全接続でも解説しています。
認証では、固定のAPIキーを配り続けるのではなく、リクエスト時に発行される短命で権限を絞った認証情報を使う方式が安全です。Claude のプラットフォームでは、静的なAPIキーを Workload Identity Federation(WIF)で置き換え、AWS の IAM ロールや GCP・Kubernetes のサービスアカウントなど、ワークロードが既に持つIDで認証できます(一般提供)。鍵を作る・回す・漏らすという運用そのものをなくせるため、権限統制の起点として有効です。
柱3:ヒューマンインザループの設計
権限を絞っても、影響の大きい操作は人が承認する設計を残します。すべてを止めると自動化の利点が失われ、すべてを任せると事故時の被害が大きくなるため、「リスクの段階に応じて人の関与度を変える」のが現実的です。
具体的には、エージェントの権限を「観察のみ」「助言まで」「実行できるが承認が必要」「一定範囲は自律実行」のように段階分けし、金額・対外送信・データ削除などの高リスク操作には人の承認を挟みます。この段階設計の考え方はAIエージェントのガバナンスは4段階で設計するで詳しく扱っています。運用が安定し、エージェントの精度が確認できた領域から、人の関与を少しずつ減らしていくのが安全な進め方です。
柱4:コスト・品質のモニタリングとドリフト検知
最後に、コストと出力品質を継続的に監視します。エージェントは1回の実行で多数のツール呼び出しやトークン消費を伴うため、想定外のコストが膨らみやすいからです。利用量・コストをトークン単位・実行単位で可視化し、上限や閾値を設けておきます。
品質面では、導入直後の出力品質の分布を基準として記録し、統計的な閾値を超える変化(ドリフト)を検知できるようにします。モデルの更新や入力データの変化で、いつの間にか精度が落ちることがあるためです。コストの見える化と権限統制をセットで運用に組み込む全体像は、Claudeを全社に定着させる運用ガイドも参考になります。
本番化までのチェックリスト
PoC から本番へ進む前に、最低限そろえておきたい項目を整理します。
- すべての実行とツール呼び出しがトレース・監査ログとして記録されるか
- 共有APIキーではなく、ワークロード別のIDで監査できるか
- 実行環境(サンドボックス)と通信経路を自社で制御できるか
- 認証情報は短命・最小権限になっているか
- 高リスク操作に人の承認が挟まる設計になっているか
- コストと品質を継続的に監視し、異常を検知できるか
これらは導入のハードルではなく、「自律的に動くものを安心して任せ続けるための前提」です。最初から監視と統制を組み込むほど、対象業務を広げやすくなります。
まとめ
AIエージェントの本番運用で重要なのは、「動くこと」ではなく「何をしたかを追え、できることを絞り、重要な判断は人が承認する」状態を保つことです。可観測性・監査ログ、権限と実行環境の統制、ヒューマンインザループ、コスト・品質の監視という4つの柱をセットで設計すれば、自律実行の利点を活かしながらリスクを抑えられます。
まずは小さな業務でこの4つを一通り組み、追跡と統制の型を作ってから、対象範囲を段階的に広げていくのが現実的な進め方です。
出典
- Anthropic「New in Claude Managed Agents: self-hosted sandboxes and MCP tunnels」2026年5月(claude.com/blog/claude-managed-agents-updates)
- Anthropic「Workload Identity Federation (WIF) is now generally available on the Claude Platform」(claude.com/blog/workload-identity-federation)

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。