ローカル LLM とは?2026年版 構築手順・おすすめモデル・Mac対応まで完全ガイド
機密データを扱う企業向けに、LLM ローカル環境を構築しセキュアにAIを活用する手順を解説。2026年最新の日本語特化モデル(Qwen3 Swallow / Llama-3-ELYZA-JP)と推奨VRAM、Mac 対応、Ollama × Dify による3ステップ導入までを実務目線で網羅します。

機密データを扱う企業が情報漏洩リスクをゼロに抑えてAIを活用するには、自社のサーバーやPC内にLLM ローカル環境を構築し、外部通信を遮断するのが最も確実な手法です。SaaS型AIツールの利用が制限されている組織でも、この方法なら安全に導入できます。
本記事では、コストを抑えてLLM オープンソースモデルを導入し、セキュアなAI運用を始めるための具体的な3つのステップを、2026年最新のモデル動向と推奨スペックを踏まえて解説します。
ローカルLLM環境を構築する最大のメリットとコスト構造

企業が生成AIを業務に組み込む際、最も懸念されるのが機密データの取り扱いです。SaaS型のAIサービスは便利ですが、プロンプトに入力した情報が外部のクラウドへ送信されるため、従業員の不用意な利用が情報漏洩のリスクにつながります。
LLM(大規模言語モデル)と生成AIの違いを踏まえると、LLMは膨大なデータ処理を必要とするためクラウドで動かすのが一般的でした。しかし、生成AIのリスクとガバナンスの観点から、厳格なセキュリティ基準を持つ企業では社外へのデータ送信自体が禁止されているケースも少なくありません。
そこで、外部のサーバーにデータを一切送信しないLLM ローカル環境の構築が注目されています。
長期的なランニングコストの削減効果

クラウドAPIを利用する場合、利用回数や処理する文字数に比例して従量課金のコストが継続的に発生します。一般的な生成AIの導入費用としても、全社規模で活用が進むほどランニングコストは膨らみます。
一方でローカル構築の場合、GPUを搭載したサーバーやPCの初期投資はかかりますが、その後のデータ処理にかかる通信費やAPI利用料はゼロです。社内の大量のドキュメントを要約したり、常にAIを稼働させたりする用途であれば、半年から1年程度で初期投資を回収できるケースが多数あります。
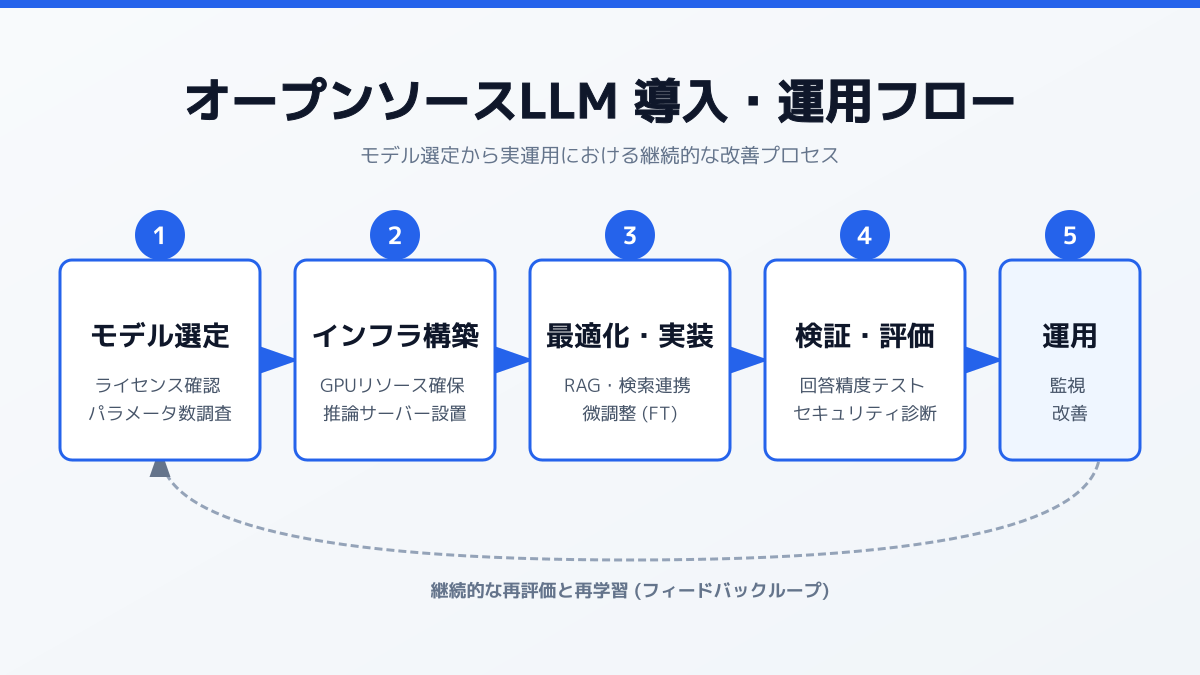
LLMオープンソースモデルの選び方|2026年最新版

ローカル環境で動かすには、無償で公開されているLLM オープンソースモデルを選定する必要があります。2026年は Qwen3 シリーズ や日本語特化の Qwen3 Swallow が業界を大きく塗り替えており、軽量化と性能向上が同時に進んでいます。用途に応じた使い分けが重要です。
| モデル名 | 推奨VRAM容量 | 特徴と得意領域 |
|---|---|---|
| Qwen3.5 (4B / 9B) | 4B: 6GB / 9B: 12GB | Alibaba が 2026 年 3 月に公開した最新世代。同パラメータ数で前世代の倍程度の性能と評価され、日本語の読みやすさも大幅改善。MacBook Pro でも快適に動作 |
| Qwen3 Swallow (8B / 32B) | 8B: 12GB / 32B: 24GB〜 | 東京科学大学(旧東工大)が Qwen3 を日本語強化した推論型モデル。同規模オープンモデルの中で日本語タスク最高クラス(2026 年 2 月時点) |
| Llama-3-ELYZA-JP (8B) | 12GB | ELYZA が日本語チューニングを施した実用モデル。社内チャットや要約に強い |
| Gemma 3 (4B / 12B) | 4B: 6GB / 12B: 16GB | Google が 2026 年に公開したマルチモーダル対応モデル。長文コンテキスト 128K 対応で社内文書 RAG に向く |
| GLM-4.7-Flash (30B/A3B MoE) | 24GB〜 | 清華大学発、2026 年 1 月公開。MoE 構成で実稼働 3B 相当の軽量さ。OpenAI / Claude API 互換でコード生成や RAG に好相性 |
これらのモデルは量子化技術によってサイズが圧縮されており、一般的なビジネス用途であれば中小企業のワークステーションでも十分に実運用が可能です。LLM と RAG の違いを踏まえた選定基準も合わせて確認しておくと、社内データ活用のゴールから逆算してモデルを絞り込めます。
Mac(Apple Silicon)でローカルLLMを動かす
「ローカルLLM mac」というクエリが示すとおり、ユニファイドメモリを搭載した Apple Silicon は GPU 専用機を用意せずローカルLLM を動かしたい個人・部門単位で人気が高い選択肢です。
- MacBook Air (M3 / M4, 16GB 以上): Qwen3.5 4B など 4〜8B クラスを軽快に動かせる
- MacBook Pro / Mac Studio (M3 Pro 以上, 32GB / 64GB): Qwen3.5 9B、Qwen3 Swallow 8B、Llama-3-ELYZA-JP 8B が常用域
- Mac Studio (M3 Ultra, 128GB〜): Qwen3 Swallow 32B クラスや GLM-4.7 など、社内サーバー代替の検証機として使える
ユニファイドメモリは VRAM とシステム RAM が共有されるため、容量設計のコツは「搭載メモリ ≥ モデルサイズ × 1.5」です。Windows / Linux 機と異なり GPU カード追加で拡張できないため、購入時に上位メモリを選ぶ判断が後の運用効率を大きく左右します。
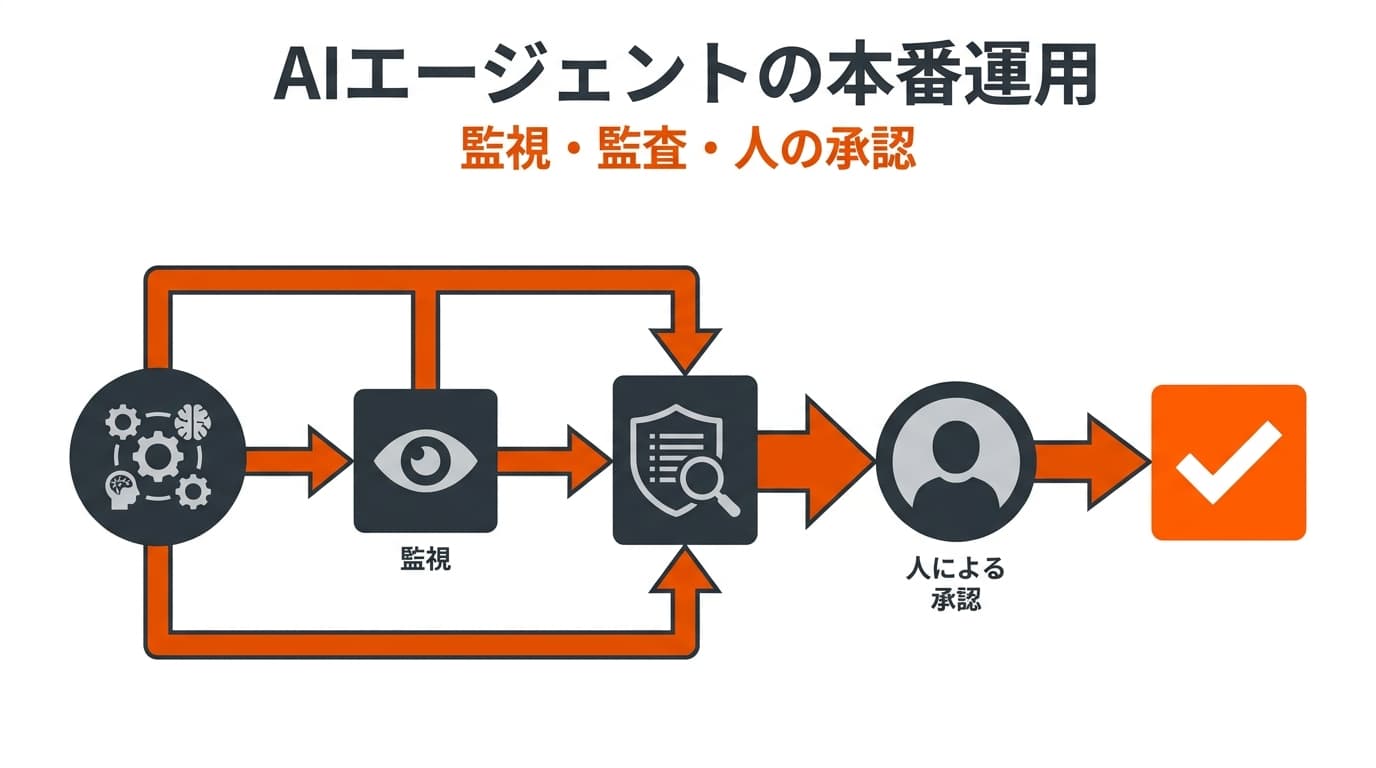
LLMローカル環境の構築手順|機密データを守る3つのステップ
それでは、実際に安全なAI環境を社内に構築するための具体的な3つのステップを解説します。
ステップ1:必要なPCスペックと環境準備
快適な推論スピードを確保するためには、グラフィックボード(GPU)の性能が最も重要です。2026 年時点で業界が推奨する目安は以下のとおりです。
- OS: Windows 11 / Ubuntu 22.04 以降 / macOS (Apple Silicon 推奨)
- メモリ (RAM): 32GB 以上(社内 RAG 用途は 64GB を推奨)
- GPU VRAM: 16GB 以上(RTX 4070 Ti SUPER / RTX 4080 / RTX 5080 クラス)。8GB は 4B モデル限定の最小構成
- ストレージ: 1TB 以上の高速 SSD(モデルデータと量子化版の保管用)
VRAM 必要量の簡易計算式は「パラメータ数(B)の半分が GB 単位の必要 VRAM 目安(Q4 量子化時)」です。例えば 14B モデルなら約 7GB の VRAM が必要になります。MacとDockerを用いた高度な環境構築手順を実施する場合は、M3 Pro 以降のチップを搭載した MacBook Pro や Mac Studio が有力な選択肢となります。
ステップ2:Ollamaを用いたオープンソースLLMの導入
環境構築の技術的ハードルを大きく下げるのが「Ollama」というツールです。コマンド一つでモデルのダウンロードから実行までを管理できます。
- Ollama の公式サイトから OS に合ったインストーラーをダウンロードし、インストールします。
- ターミナル(または PowerShell)を開き、以下のコマンドを実行します。
# 2026 年最新の Qwen3.5 9B を取得して対話開始
ollama run qwen3:8b
# 日本語特化モデルを使う場合(Llama-3-ELYZA-JP 8B)
ollama run elyza/llama-3-elyza-jp-8b
数 GB のモデルデータがダウンロードされた後、ターミナル上で直接 AI と対話できるようになります。この時点で、外部ネットワークへのデータ送信は一切行われていません。
ステップ3:Dify連携でセキュアなAI環境を構築
ターミナルでの操作だけでは業務に組み込みにくいため、GUI を備えた Web プラットフォームと連携させます。オープンソースの「Dify」をローカルの Docker 上で立ち上げ、先ほどの Ollama をバックエンドの LLM として登録します。
Dify を利用すると、社内のマニュアルや過去の提案書を AI に読み込ませる RAG(検索拡張生成)環境をノーコードで簡単に構築できます。機密データを参照する AI チャットボットを社内ネットワーク限定で公開すれば、情報漏洩リスクを完全に抑えながら業務効率化を実現できます。
よくある質問
ローカルLLMとは何ですか?
自社の PC やサーバー内で完結して動かす大規模言語モデルのことです。プロンプトや社内文書が外部クラウドへ送信されないため、機密情報を扱う業務でも安全に AI を活用できます。
ローカルLLM環境の構築は難しいですか?
Ollama や LM Studio といったツールの登場により、以前のような複雑な Python 環境の構築は不要になりました。基礎的なコマンドライン操作ができれば、数十分で最初のチャット環境を立ち上げることが可能です。
クラウドAPIと比較したときのデメリットは何ですか?
ChatGPT(GPT-4o)や Claude Opus 4.6 / 4.7 などの最新クラウドモデルと比較すると、軽量化されたオープンソースモデルは長文の文脈理解や複雑な論理的推論で劣る場面があります。高度なプログラミング支援より、定型文の要約や社内 FAQ の応答など、タスクを絞った利用に向いています。
ローカルLLMで日本語を使うならどのモデルがおすすめですか?
2026 年時点では Qwen3 Swallow 8B / 32B、Llama-3-ELYZA-JP 8B、Qwen3.5 9B が日本語タスクで実績を出しています。社内文書要約や問い合わせ応答が中心であれば、まず Llama-3-ELYZA-JP 8B か Qwen3 Swallow 8B から始めると導入しやすいです。
まとめ
LLM ローカル環境の構築は、企業の機密データを守りながら AI を業務活用するための強力なアプローチです。Ollama や Dify といったツールに加え、Qwen3 Swallow や Llama-3-ELYZA-JP といった 2026 年最新の日本語強化モデルを活用すれば、高度なエンジニアリングスキルがなくても安全なオープンソース AI プラットフォームを自社内に立ち上げられます。
自社のセキュリティ要件と業務課題を照らし合わせ、外部に絶対に出せないデータを扱う領域から、ローカル LLM の導入を検討してみてはいかがでしょうか。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。