【2026年版】機械学習モデルとは?種類一覧とPython実装で失敗しない5つの手順
機械学習モデルで失敗しないための選定から運用までの実践手順がわかります。AI導入を進めたものの、自社の課題に合わないアルゴリズムを選定して頓挫するケースが後を絶ちません。本記事では2026年現在も主流の機械学習モデルの種類一覧と、scikit-learnを用いたPythonでの交差検証サンプルコードなど、ビジネス現場での運用を成功させる5つの手順を具体的に解説します。

機械学習モデルとは、大量のデータからパターンを学習し、未知のデータに対して予測や分類を行うアルゴリズムの仕組みです。AI導入で失敗しないためには、解決したいビジネス課題に合ったモデルを種類一覧から正しく選定し、運用後も精度の評価サイクルを回すことが不可欠です。
AI導入を進めたものの、自社の課題に合わない手法を選んで頓挫するケースが後を絶ちません。本記事では、代表的な機械学習モデルの一覧や、2026年現在も実務で標準的に使われるPython(scikit-learn)を活用した評価手法のコード例など、現場運用で失敗しないための5つの手順を具体的に解説します。
1. 機械学習モデルの基本理解と導入判断
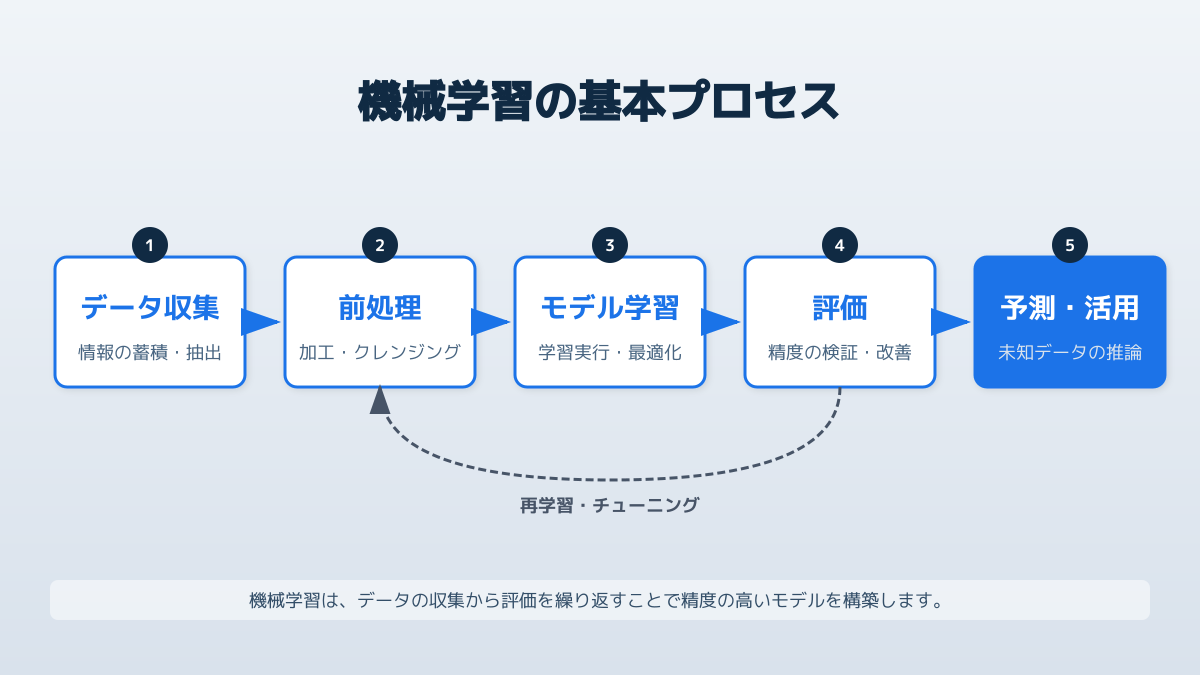
ビジネス現場でAIを活用するにあたり、まずは「機械学習モデルとは何か」という基本事項を正確に整理することが重要です。機械学習モデルとは、大量のデータからパターンや規則性を学習し、未知のデータに対して予測や分類を行うための数式やアルゴリズムの集合体を指します。単なる計算プログラムとは異なり、入力されるデータが増えるほど予測精度が向上する点が最大の特徴です。
自社の業務にモデルを導入すべきかの判断ポイントは、解決したい課題がデータによって定量的に評価可能かどうかです。たとえば、ある製造業の事例では、目視で行っていた不良品検知に画像認識モデルを導入した結果、月40時間かかっていた検品作業を5時間に短縮(87.5%削減)することに成功しています。このように、具体的な数値目標を設定できる業務から優先的に導入を検討します。
2. 代表的な機械学習モデルの一覧とアルゴリズムの選び方
機械学習モデルをビジネスに導入する際、2つ目の重要な手順となるのが「自社の課題に最適なアルゴリズムの選定」です。どれほど大量のデータを用意しても、解決したい課題とモデルの性質が一致していなければ、期待する予測精度は実現できません。
失敗しないためのアルゴリズム選定基準
モデル選びで失敗しないためには、以下の3つの基準でアプローチを絞り込みます。
- 目的変数の有無(教師あり/なし): 正解データ(過去の売上実績や退会履歴など)を用いて学習させるか、正解がない状態からデータの類似性をグループ化するか。
- 予測したいデータの形式(回帰/分類): 「明日の売上(連続する数値)」を予測する場合は回帰、「この顧客は退会するか(カテゴリ判別)」を予測する場合は分類を選択します。
- 説明性の高さ: なぜその予測結果になったのか、ビジネス側に根拠を説明する必要がある場合は、ブラックボックスになりやすいディープラーニングよりも、決定木や線形回帰など解釈性が高いモデルを優先します。
代表的な機械学習モデルの一覧と活用例
以下は、実務でよく使われる機械学習モデルの一覧と、それぞれのビジネス活用事例をまとめた比較表です。
| モデルの種類 | 学習手法 | 代表的なアルゴリズム | ビジネスでの主な活用事例 |
|---|---|---|---|
| 回帰モデル | 教師あり学習 | 線形回帰、ランダムフォレスト回帰、XGBoost回帰 | 店舗の売上予測、需要予測に基づく余剰在庫の削減 |
| 分類モデル | 教師あり学習 | ロジスティック回帰、決定木、SVM、LightGBM | 顧客の離反予測、スパムメールの自動判定、不良品検知 |
| クラスタリング | 教師なし学習 | K-means法、階層的クラスタリング | 顧客セグメンテーションの細分化、クレジットカードの不正利用検知 |
| ニューラルネットワーク | 教師あり学習/自己教師あり学習 | 多層パーセプトロン、CNN、Transformer | 画像認識、自然言語処理、生成AIの基盤モデル |
| 強化学習 | 強化学習 | Q学習、深層強化学習(DQN) | 配送ルートの最適化、ダイナミックプライシング(価格の自動変動) |
このように、まずは解決したい業務課題を明確に定義し、出力したい結果から逆算することで、採用すべき機械学習モデルの方向性が自然と定まります。なお、構造化データの分類・回帰では2026年現在もXGBoostやLightGBMなど勾配ブースティング系のモデルが実務の第一選択肢であり、画像・テキスト領域ではPyTorchやTensorFlowで実装するニューラルネットワークが標準となっています。
3. Pythonを活用した機械学習モデルの評価手法

構築したモデルが実際のビジネス現場で役立つかどうかを左右するのが、厳密な精度検証の手順です。2026年現在の開発現場では、Pythonの豊富な機械学習ライブラリ(scikit-learn・XGBoost・LightGBM・PyTorch・TensorFlowなど)を活用し、評価と改善のサイクルを回します。
モデルの性能を正しく測るためには、解きたい課題の性質に合わせて適切な評価指標を選択する必要があります。回帰モデルの場合は予測値と実際の値のズレを測るRMSE(二乗平均平方根誤差)などを、分類モデルの場合は正解率(Accuracy)だけでなく、適合率(Precision)や再現率(Recall)を用います。
たとえば、発生確率が1%しかない不良品を検知するモデルの場合、すべてを「正常」と予測するだけで正解率は99%になりますが、これでは意味がありません。誤検知と見逃しのどちらのリスクがビジネスに大きな影響を与えるかを具体化し、適合率と再現率のバランスを調整することが重要です。
Pythonによるモデル評価のサンプルコード
手元のデータに対する「過学習(オーバーフィッティング)」を防ぐため、Pythonでは交差検証(クロスバリデーション)を簡単に実装できます。以下は、scikit-learnを用いて分類モデル(ランダムフォレスト)の精度を検証する実務的なサンプルコードです。
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
# 1. サンプルデータの読み込み(例として乳がんデータセットを使用)
data = load_breast_cancer()
X = data.data # 特徴量(入力データ)
y = data.target # 目的変数(正解ラベル)
# 2. 機械学習モデルの定義(ランダムフォレスト分類器)
model = RandomForestClassifier(n_estimators=100, random_state=42)
# 3. 交差検証(クロスバリデーション)の実行
# データを5分割し、未知のデータに対する汎化性能を客観的に評価
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
# 4. 評価結果の出力
print("各分割データの正解率:", scores)
print("平均正解率:", scores.mean())
このように、Pythonを活用すればわずか数行のコードで堅牢な評価基盤を構築できます。未知のデータに対する「汎化性能」を客観的に評価する仕組みを整えることが、実運用での失敗を防ぐ最大の防御策となります。
4. 継続的なモニタリングとデータドリフト対策
最適なモデルを選定し初期の構築が完了したあとも、現場で継続的に成果を出すためには運用体制の構築が不可欠です。
市場環境や顧客の行動変化により、学習時のデータと運用時のデータ傾向が乖離する「データドリフト」が発生します。時間の経過とともに予測精度は必ず低下するため、定期的な精度のモニタリングとモデルの再学習プロセスをあらかじめ設計しておく必要があります。ある小売業では、季節変動によるデータドリフトを監視し、毎月自動で再学習を行うパイプラインを構築したことで、需要予測の誤差率を年間を通じて5%以内に維持しています。
また、予測結果を既存のシステムに自動連携させるなど、ユーザーの作業負担を増やさない業務フローの設計が必須です。近年では、こうした予測モデルの運用やデータ処理を、AIエージェントに自律的に実行させるアプローチも注目されています。最新のAIツールを活用して社内の業務自動化を推進したい場合は、Claude Sonnet 4.5で業務自動化!Claude in Chrome等AIエージェントツール実践手順 も合わせて参考にしてください。
5. セキュリティ対策とガバナンスの確立
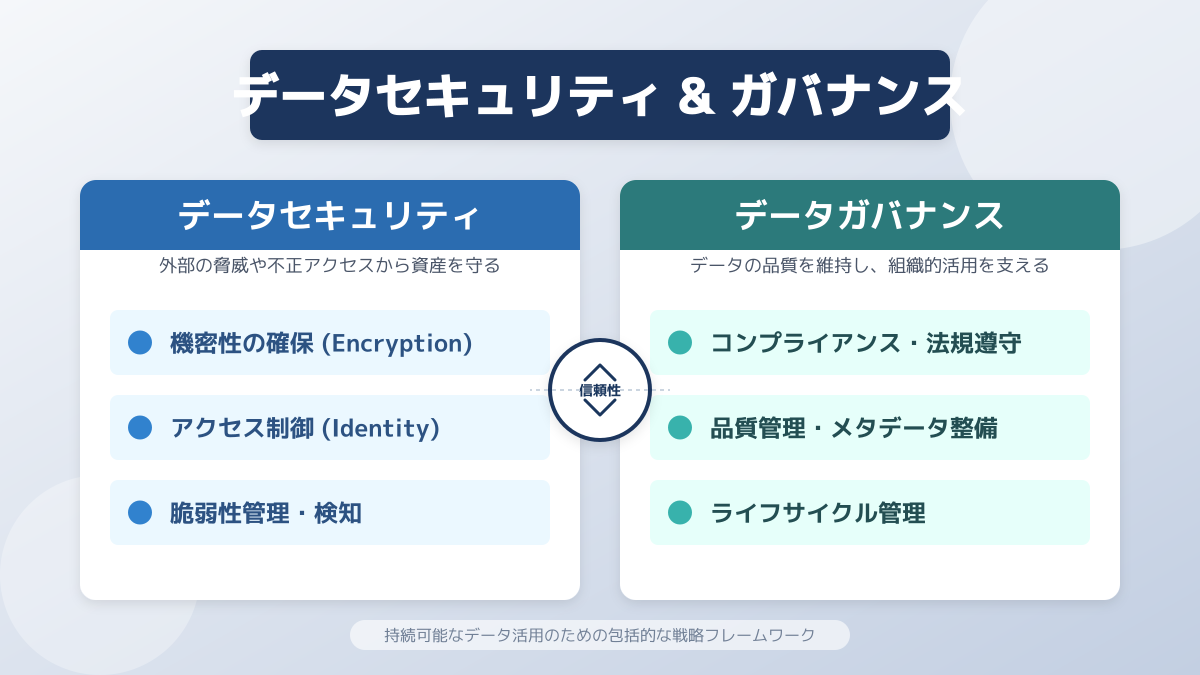
ビジネス現場でAIを活用する際、構築したモデルを安全に運用するためのセキュリティとガバナンスの確立が最後のポイントとなります。どれほど精度の高いモデルであっても、情報漏洩や不正利用のリスクを管理できなければ、企業全体の信頼を損なう結果に直面します。
企業の機密データや顧客情報を扱う場合、データが外部のサーバーに意図せず送信されないよう、データの暗号化やアクセス権限の厳格な制御が必要です。また、悪意のある入力によってモデルに予期せぬ動作を引き起こさせるプロンプトインジェクション攻撃など、新たな脅威に対する継続的な対策も欠かせません。
法人利用におけるセキュリティリスクを回避し、安全なシステムを構築するための具体的な手順については、【2026年版】AIアシスタントとは?法人利用の危険性と安全なAIエージェント開発の3ステップも併せて参考にしてください。監査ログの取得やガイドラインの定期的な見直しを運用フローに組み込むことで、はじめて機械学習モデルの真のビジネス価値を引き出すことができます。
よくある質問
機械学習モデルとは何ですか?
大量のデータからパターンや規則性を学習し、未知のデータに対して予測や分類を行うためのアルゴリズムの集合体です。データが増えるほど、予測精度が向上する性質を持ちます。
機械学習モデルにはどんな種類がありますか?
代表的な種類は「回帰モデル」「分類モデル」「クラスタリング」「ニューラルネットワーク」「強化学習」の5つです。構造化データの予測ではXGBoostやLightGBM、画像・テキストではPyTorchやTensorFlowで実装するニューラルネットワークが2026年現在も実務の主流です。
機械学習モデルの開発にはPythonが必須ですか?
必須ではありませんが、実務ではPythonが最も広く使われています。scikit-learnやXGBoost、LightGBM、PyTorch、TensorFlowなど、機械学習に特化した強力なライブラリが豊富に揃っており、開発工数を大幅に削減できるためです。
機械学習とディープラーニングの違いは何ですか?
機械学習はAIの要素技術の一つであり、ディープラーニングはその機械学習の手法の一つです。ディープラーニングは人間の脳の神経回路を模したニューラルネットワークを用い、画像認識や自然言語処理などの複雑なタスクで高い精度を発揮します。
まとめ
本記事では、ビジネス現場で機械学習モデルの導入を成功させるための5つの重要ポイントを解説しました。モデルの基本理解から始まり、課題に合わせたアルゴリズムの選定、Pythonを用いた厳密な精度検証、データドリフトを見据えた継続的なモニタリング、そしてセキュリティとガバナンスの確立まで、各フェーズでの具体的なアプローチを整理しました。
これらのポイントを体系的に押さえることで、単なる技術導入に終わらず、AIが真に業務効率化と生産性向上に貢献する強力なツールとして機能します。AIプロジェクトの成功には、技術的な側面だけでなく、具体的な数値目標を伴うビジネス要件との整合性、そして継続的な運用体制の構築が不可欠です。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。