自然言語処理(NLP)とは?仕組み・機械学習との違い・LLM時代の活用事例7選【2026年版】
自然言語処理(NLP)とは、人間の言葉をコンピュータに理解させるAI技術です。仕組み・機械学習やLLMとの違い・メルカリ等のビジネス活用事例・JGLUEやLLM-jp-4等の2026年最新動向・導入3ステップを非エンジニア向けに解説します。

議事録作成、過去の提案書探し、顧客問い合わせの一次対応など、テキストを扱う定型業務は現場の生産性を大きく損ねる要因です。AIに人間の言葉を理解させる「自然言語処理(NLP)」を業務に組み込めば、こうした作業を自動化し、工数を大幅に削減できます。
本記事では、非エンジニア向けに自然言語処理の仕組みを基礎から整理し、機械学習・LLM・生成AIとの関係、メルカリやLINEヤフーなど国内企業のビジネス活用事例、JGLUE や LLM-jp-4 など 2026 年最新の日本語 NLP 動向、導入を成功させる3ステップ、Python による実装の入り口までをまとめて解説します。
自然言語処理(NLP)とは?1分でわかる定義と要点
自然言語処理(NLP / Natural Language Processing)とは、人間が日常的に使う日本語や英語などの「自然言語」を、コンピュータに理解・生成・処理させるためのAI技術領域の総称です。
要点を先に押さえると、次の4点で全体像が掴めます。
- 目的:テキストや音声で書かれた人間の言葉を、コンピュータが「意味のある情報」として扱えるようにする
- 主な処理:形態素解析・構文解析・意味解析・文脈解析の4段階で言葉を分解し、関係性を読み取る
- 主な応用:機械翻訳、要約、検索、チャットボット、感情分析、議事録自動化、社内ナレッジ検索
- 2026年時点の主役:Transformer アーキテクチャをベースとした大規模言語モデル(LLM)。テキスト分類・要約・翻訳など多くのタスクで実用レベルに到達
「自然言語処理」「NLP」「LLM」「生成AI」はしばしば混同されますが、関係は以下のとおりです。
- 自然言語処理(NLP):言葉をコンピュータに扱わせる「研究分野・技術領域」全体
- 機械学習:NLPの一部のタスクを解くために使われる「手法」の一つ
- LLM(大規模言語モデル):NLP を解くための「巨大なモデル」。Transformer ベース
- 生成AI:LLM などを使って文章・画像・音声を生成する「アプリケーション領域」
つまり、ChatGPT や Claude といったサービスは「生成AIの一例」であり、その内部で動いているのが「LLM」、その LLM が解こうとしている学問領域が「自然言語処理(NLP)」という入れ子構造です。
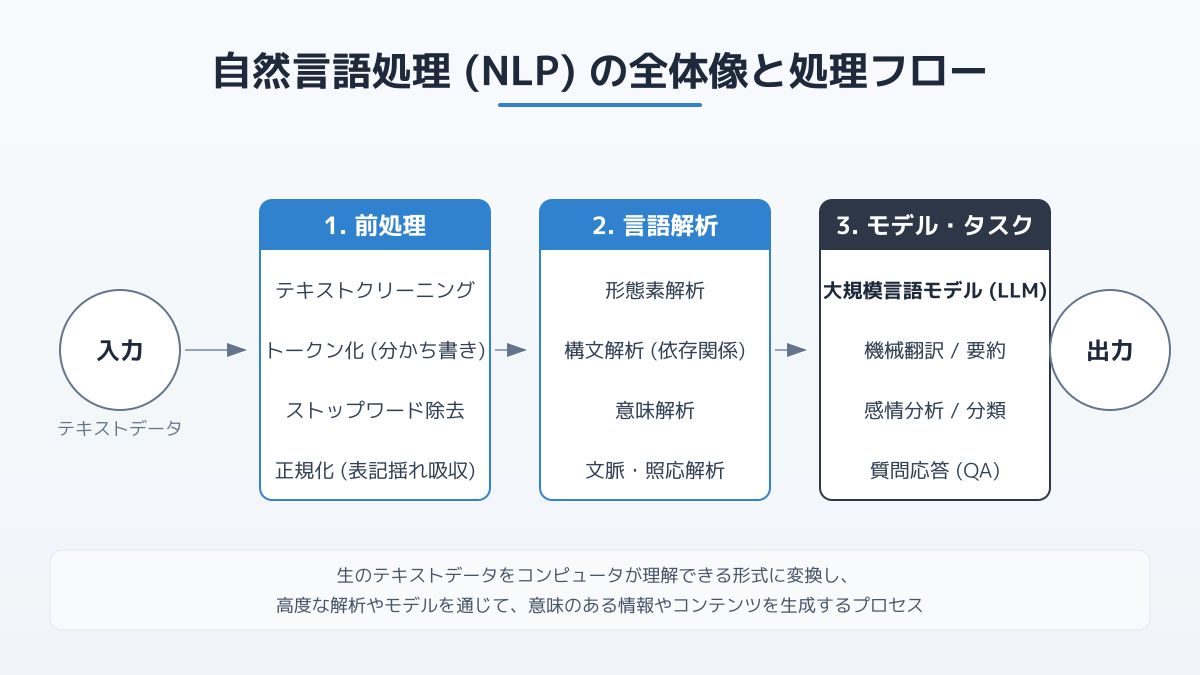
自然言語処理の仕組み|4つの解析プロセスと Transformer
自然言語処理は、文章をいきなり「意味」として理解しているわけではありません。基礎的な処理パイプラインは、次の4段階で構成されます。
形態素解析|文を単語に分解する
形態素解析とは、文章を意味を持つ最小単位(形態素)に分解し、それぞれの品詞(名詞・動詞・助詞など)を判定する処理です。日本語は単語の区切りがないため、英語より一段難しい工程になります。代表的な日本語の形態素解析器には MeCab・Sudachi・GiNZA などがあります。
構文解析|単語のつながりを構造化する
構文解析は、形態素解析の結果をもとに「どの単語が、どの単語にかかっているか」という文法的な構造を木構造として捉える処理です。係り受け解析とも呼ばれ、主語・述語・修飾関係を明確にすることで、後段の意味理解の土台になります。
意味解析|単語の意味と関係を取り出す
意味解析では、単語の語義(多義性の解消)や、文中での役割(誰が、何を、誰に、いつ)を判定します。「銀行に行く」の「銀行」が金融機関なのか川岸なのかを文脈から決めるような処理が、ここに含まれます。
文脈解析|文をまたいだ流れと意図を読み取る
文脈解析は、複数の文や対話全体を見渡し、指示語の対象・話者の意図・話題の遷移などを把握する処理です。2026 年現在、この文脈解析の精度を大幅に押し上げているのが、後述の Transformer アーキテクチャ と LLM です。
Transformer とは|2017 年以降の NLP のブレークスルー
2017 年に Google が発表した Transformer は、「Self-Attention(自己注意機構)」によって、文中の離れた単語同士の関係を効率的に学習できる構造を持ちます。これにより、長い文章や対話の文脈理解が飛躍的に向上し、現在主流の LLM(GPT 系・Claude 系・Gemini 系・国産 LLM)はいずれも Transformer をベースに構築されています。
Self-Attention の本質は、「ある単語の意味を決めるとき、文中のどの単語にどれだけ注意を払うかを動的に重み付けする」点にあります。これにより、従来の RNN/LSTM では難しかった「数十〜数百単語先との関連付け」が現実的なコストで可能になりました。
自然言語処理と機械学習の違い・関係を整理する
「自然言語処理 ai」「自然言語処理 基礎」で調べる方が必ず混乱するのが、機械学習との関係です。要点は1つで、「NLP は問題領域、機械学習はそれを解くための手段」 という関係です。
| 観点 | 自然言語処理(NLP) | 機械学習(ML) |
|---|---|---|
| 何か | 言葉を扱う「分野」 | データからパターンを学ぶ「手法」 |
| 範囲 | 翻訳・要約・対話・検索など | 画像・音声・推薦など NLP 以外も含む |
| 関係 | ML を含む様々な技術で実装される | NLP のタスクを解く中核技術の一つ |
| 例 | 議事録の要約をしたい | 大量の議事録から要約モデルを学習 |
歴史的には、NLP はルールベース(人手で文法規則を書く)から始まり、統計的機械学習を経て、現在は 深層学習(ディープラーニング)ベースの LLM が中心です。とくに 2017 年の Transformer 登場以降は、機械学習=NLP の主役、というほど比重が大きくなっています。
機械学習や生成AIとの違いをさらに深掘りしたい場合は、 マルチモーダルAIとは?画像・音声・テキスト統合の仕組みとDX活用事例5選 と AIエージェントとは?生成AIとの決定的な違いと2026年最新の活用事例をわかりやすく解説 を併読すると、AI 全体の地図が一気にクリアになります。
2026年の自然言語処理|LLM・国産モデル・日本語ベンチマーク最新動向
2026 年は、日本語 NLP がいよいよ実務で「使えるレベル」に到達した転換点です。非エンジニアの意思決定者として押さえておきたいのは、次の3点です。
LLM がほぼ全ての NLP タスクの最高精度を更新
テキスト分類・感情分析・要約・翻訳・QA など、従来は個別モデルで解いていたタスクの大半で、汎用 LLM が SOTA(最高精度)に近い水準を出すようになりました。1モデル + プロンプトで多くのタスクを賄える「汎用化」が進み、PoC のコストが大幅に下がっています。
国産日本語 LLM の本格台頭|LLM-jp-4 の登場
2026 年 4 月、国立情報学研究所(NII)の大規模言語モデル研究開発センターから、約 12 兆トークンの良質なコーパスで学習した国産 LLM 「LLM-jp-4 8B」「LLM-jp-4 32B-A3B」 がオープンソースライセンスで公開されました。日本語 MT-Bench など一部ベンチマークで GPT-4o や Qwen3-8B を上回る性能を達成しており、機密データを国内に閉じたまま LLM を運用したい企業にとって現実的な選択肢になりつつあります。
日本語 NLP ベンチマーク|JGLUE と JCommonsenseQA
日本語 LLM の性能を比較する際、業界標準として広く参照されているのが JGLUE(Japanese General Language Understanding Evaluation) です。早稲田大学とヤフーが共同で構築した日本語 NLU ベンチマークで、テキスト分類・文ペア分類・QA など複数のタスクで構成されます。特に JCommonsenseQA は CommonsenseQA の日本語版で、常識推論能力を 5 択問題で評価します。「日本語に強い」と謳う LLM を比較するときは、自社用途に近いサブタスクのスコアを必ず確認しましょう。
学術コミュニティ|自然言語処理学会と NLP2026
国内の研究動向は、言語処理学会(自然言語処理学会) の年次大会で集約されます。2026 年 3 月に開催された NLP2026(第32回年次大会) では、LLM 以降の研究テーマ(RAG、日本語事前学習、評価設計、安全性)の発表が増加しており、産業界の実装にも 1〜2 年で反映される流れが続いています。
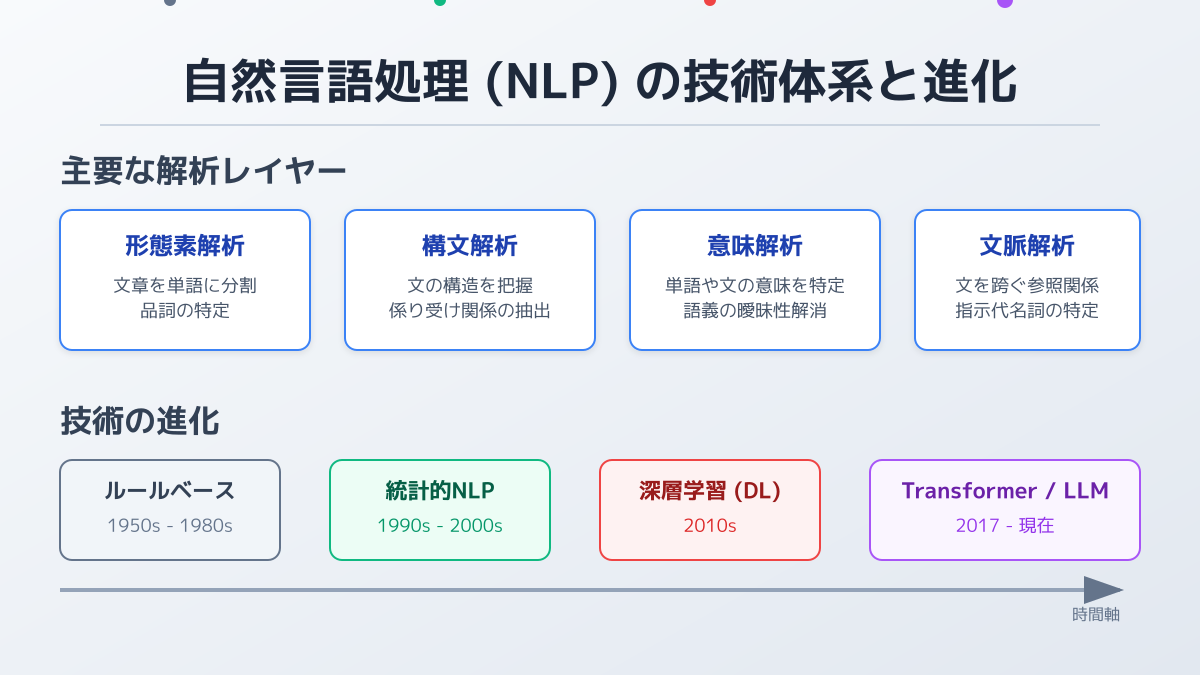
自然言語処理のビジネス活用事例7選|国内企業の実例から学ぶ
ここからは、自然言語処理がどのように業務に組み込まれているかを、なるべく具体的な企業事例とともに整理します。
事例1:議事録の自動文字起こし・要約
会議音声をテキスト化し、決定事項・タスク・宿題を自動抽出する用途は、NLP が最も得意とする領域です。Microsoft Teams・Zoom・Google Meet 等の標準機能化が進み、毎回 2 時間かかっていた議事録作成を 15 分に短縮するなど、定量的な工数削減が現場で起きています。
事例2:カスタマーサポートの一次対応自動化
問い合わせ内容を理解して回答生成するチャットボットは、24 時間体制の一次対応と、有人対応への適切なエスカレーションを両立できます。詳しい導入事例は カスタマーサポートAI導入事例7選|LINEヤフー・楽天・Klarna に学ぶ応答時間半減の実装手順 で、LINE ヤフーが Salesforce Agentforce で月間 30 万件規模の問い合わせ対応を目指す事例などを詳しく整理しています。
事例3:メルカリのカテゴリ分類と AI アシスト
メルカリは、30 億点を超える出品商品の大規模カテゴリ分類に LLM を活用し、ChatGPT-3.5 turbo と kNN(k 近傍法)を組み合わせた 2 段階アプローチを採用しました。さらに、出品商品の改善提案を行う 「メルカリ AI アシスト」 をアプリ上で提供しており、CtoC マーケットプレイスにおける NLP の代表的な実装事例として知られています。
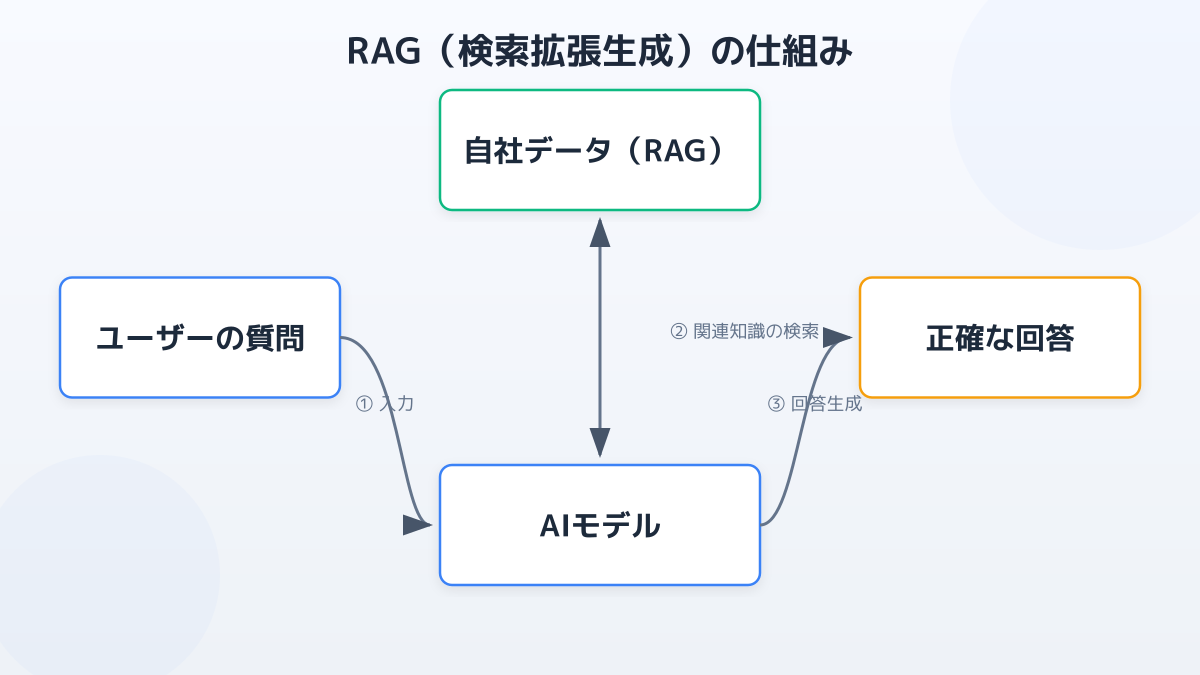
事例4:社内ナレッジ検索(社内 RAG)
膨大な社内規定・過去提案書・FAQ から必要な情報を「キーワード一致」ではなく「意味」で検索する用途です。RAG(Retrieval-Augmented Generation)と組み合わせ、出典付きで回答させることで、ハルシネーションを抑えながらナレッジ検索を実現できます。実装の選択肢は セキュアRAG実装ガイド|AWS Bedrock・Azure AI Search・Vertex AIの3クラウド比較 でクラウド別に比較しています。
事例5:感情分析・VoC(顧客の声)解析
レビュー・SNS・問い合わせログを自動分類し、ネガティブ反応の早期検知や、商品改善の優先順位付けに使われます。LLM 登場前は専用モデルが必要でしたが、現在は汎用 LLM にプロンプトを与えるだけで、十分な精度が出るケースが増えています。
事例6:機械翻訳と多言語ローカライズ
DeepL・Google 翻訳・各 LLM の翻訳機能は、専門文書を除く一般文書で「実用レベル」に到達しています。社内ドキュメント・カスタマーサポート対応・越境 EC など、英中韓のローカライズ工数を 1/3〜1/5 に圧縮した事例も珍しくありません。
事例7:文書要約と長文インプットの効率化
長尺の議事録・調査資料・契約書ドラフトを要約する用途は、ホワイトカラー全業務に効きます。Python と組み合わせて社内ツール化する具体的な手順は、 文章要約AIおすすめ無料ツール5選!Python連携で業務効率化 を参照してください。
自然言語処理 Python での実装|エンジニア向けの入り口
ここまでで NLP の全体像を掴んだら、次は実装の選択肢です。Python は NLP のデファクト言語で、形態素解析から LLM 連携まで、ほぼすべての処理を Python エコシステムで完結できます。
ライブラリの全体像(2026 年時点)
- 形態素解析:MeCab、Sudachi、SudachiPy、GiNZA
- 汎用 NLP:spaCy 3.8(Transformer 統合・多言語対応)
- 深層学習・LLM:Hugging Face Transformers v5、sentence-transformers
- RAG・ベクトル検索:LangChain、LlamaIndex、各種ベクトル DB
- 学術系:scikit-learn(古典的 ML)、PyTorch / JAX(モデル開発)
具体的なライブラリ選定と実務サンプルコード、Transformers v5 や sentence-transformers の使い分け、LLM 時代の RAG 連携パイプラインまで踏み込んだ実装ガイドは、姉妹記事 【2026年版】自然言語処理 Python ライブラリ7選|実務で成果を出すspaCy 3.8・Transformers v5活用法 で詳しく解説しています。エンジニア観点でハンズオンしたい方はそちらを必ず参照してください。
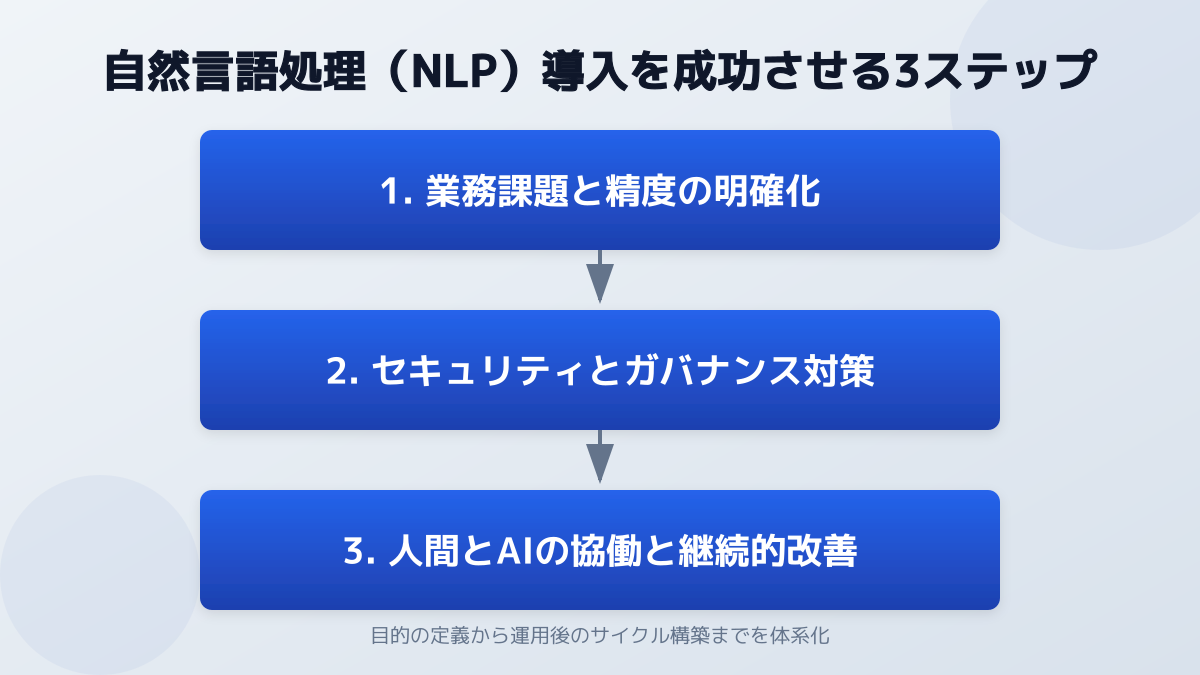
自然言語処理の導入を成功させる3ステップ
最後に、実際に NLP を業務へ組み込むためのフレームワークを整理します。技術より「業務設計」が成否を分けます。
ステップ1:業務課題と精度の明確化
導入対象の業務は、「タスクの定型度」×「データの品質と量」 で評価します。出力ゴールが明確(要約する/分類する/抽出する)で、入力データがある程度きれいなものから着手するのが鉄則です。最初から全業務を NLP に任せず、「議事録作成のうち、要約だけ」のように切り出すと立ち上がりが速くなります。
ステップ2:セキュリティとガバナンスの徹底
顧客情報・社外秘文書を扱う場合は、入力データが LLM の再学習に使われない契約形態・API 設定を選ぶこと、プロンプトインジェクション対策を講じることが不可欠です。具体的な対策は プロンプトインジェクション対策とは?OWASP LLM01に学ぶ法人向け生成AIセキュリティ6つの要点 で、OWASP LLM Top 10 と IPA 10 大脅威 2026 に沿って整理しています。
国内データ閉域での運用が必須要件の場合は、前述の LLM-jp-4 などの国産モデルをオンプレ/VPC で動かす選択肢も視野に入れます。
ステップ3:人間と AI の協働(HITL)と継続的改善
LLM は依然としてハルシネーション(事実誤認)を起こします。Human-in-the-Loop(HITL) で人間の最終確認を挟むワークフローを基本形にしつつ、業務データを RAG で参照させて回答の根拠を明示する設計が現実解です。RAG とファインチューニングの使い分けは ファインチューニングとは?RAGとの違い・企業向け導入5ステップ で詳しく比較しています。
導入後は、誤分類・誤要約のログをフィードバックしてプロンプトや RAG コーパスをチューニングする運用体制まで含めて設計しましょう。 Claude Sonnet 4.5で業務自動化!Claude in Chrome等AIエージェントツール実践手順 のように、エージェント型ツールで HITL ワークフローを組む発想も有効です。
よくある質問(FAQ)
自然言語処理と生成AI、LLMの違いは何ですか?
自然言語処理(NLP)は「人間の言葉を扱う研究分野・技術領域」、LLM は「NLP を解くために構築された巨大な機械学習モデル」、生成 AI は「LLM などを使って文章・画像・音声を生成するアプリケーション領域」です。包含関係としては、生成 AI ⊂ LLM 応用 ⊂ NLP の応用、と捉えると整理しやすくなります。
自然言語処理を導入するのにプログラミング知識は必要ですか?
必須ではありません。非エンジニアでも操作できるノーコード/SaaS が多数提供されており、議事録要約・チャットボット・社内検索などはコードを書かずに導入可能です。重要なのは、プログラミング以上に「どの業務をどこまで AI に任せるか」という業務設計の視点です。本格的に内製したい場合は Python が事実上の標準言語になります。
ハルシネーション(AI の嘘)を防ぐにはどうすればよいですか?
完全には防げませんが、リスクは大幅に低減できます。基本は次の3点です。①最終アウトプットには必ず人間のファクトチェックを挟む(HITL)、②RAG で自社の正確なデータを参照させ、出典を明示させる、③プロンプトに「不明な場合は『わかりません』と答える」など明示的な指示を入れる。重要業務ではこの3つを組み合わせて運用します。
自然言語処理を学ぶには何から始めれば良いですか?
ビジネス側の方は、本記事のような全体像 → 自社業務でのユースケース整理 → ノーコードツールでの PoC、の順がおすすめです。技術者の方は、Python での形態素解析(MeCab / GiNZA)→ Hugging Face Transformers → LLM API(OpenAI / Anthropic / Gemini)の順で、 自然言語処理 Python ライブラリ7選 を実装ガイドとして使ってください。学術的な最前線を追うなら、言語処理学会(NLP20XX)の年次大会論文集が日本語で読める最良の情報源です。
国産 LLM と海外 LLM、どちらを選べば良いですか?
汎用的な業務効率化用途では、まだ海外大手(OpenAI / Anthropic / Google)の汎用 LLM のほうが多くのタスクで安定します。ただし、機密データを国内に閉じたい・日本語特化のドメイン適応が必要、といった要件がある場合は、LLM-jp-4 などの国産モデルをオンプレ/VPC で動かす構成が現実的になってきました。JGLUE / 日本語 MT-Bench の自社用途に近いサブタスクのスコアで比較するのが選定の基本です。
まとめ|自然言語処理は「業務設計」で勝負が決まる
本記事では、自然言語処理(NLP)の定義から仕組み、機械学習・LLM・生成 AI との関係、2026 年の最新動向(LLM-jp-4・JGLUE・自然言語処理学会)、メルカリ等の国内ビジネス活用事例、Python による実装の入り口、そして導入を成功させる3ステップまでを一気通貫で解説しました。
技術が成熟した 2026 年の今、勝負を分けるのはモデルそのものではなく、「どの業務に、どの精度で、どの範囲を任せるか」という業務設計 と、RAG + HITL を組み合わせたガバナンス設計 です。本記事と関連記事を参照しながら、自社にとっての「最初の一手」を具体化していきましょう。エンジニア観点で実装を進める方は 自然言語処理 Python ライブラリ7選 に進んでください。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。



