【2026年版】自然言語処理 Python ライブラリ7選|実務で成果を出すspaCy 3.8・Transformers v5活用法
自然言語処理 PythonをDX担当者・エンジニア向けに実務目線で整理。2026年に主流となったspaCy 3.8・Transformers v5・GiNZA・SudachiPy・sentence-transformersなど7ライブラリの使い分けと、LLM時代のRAG連携まで具体例付きで紹介します。
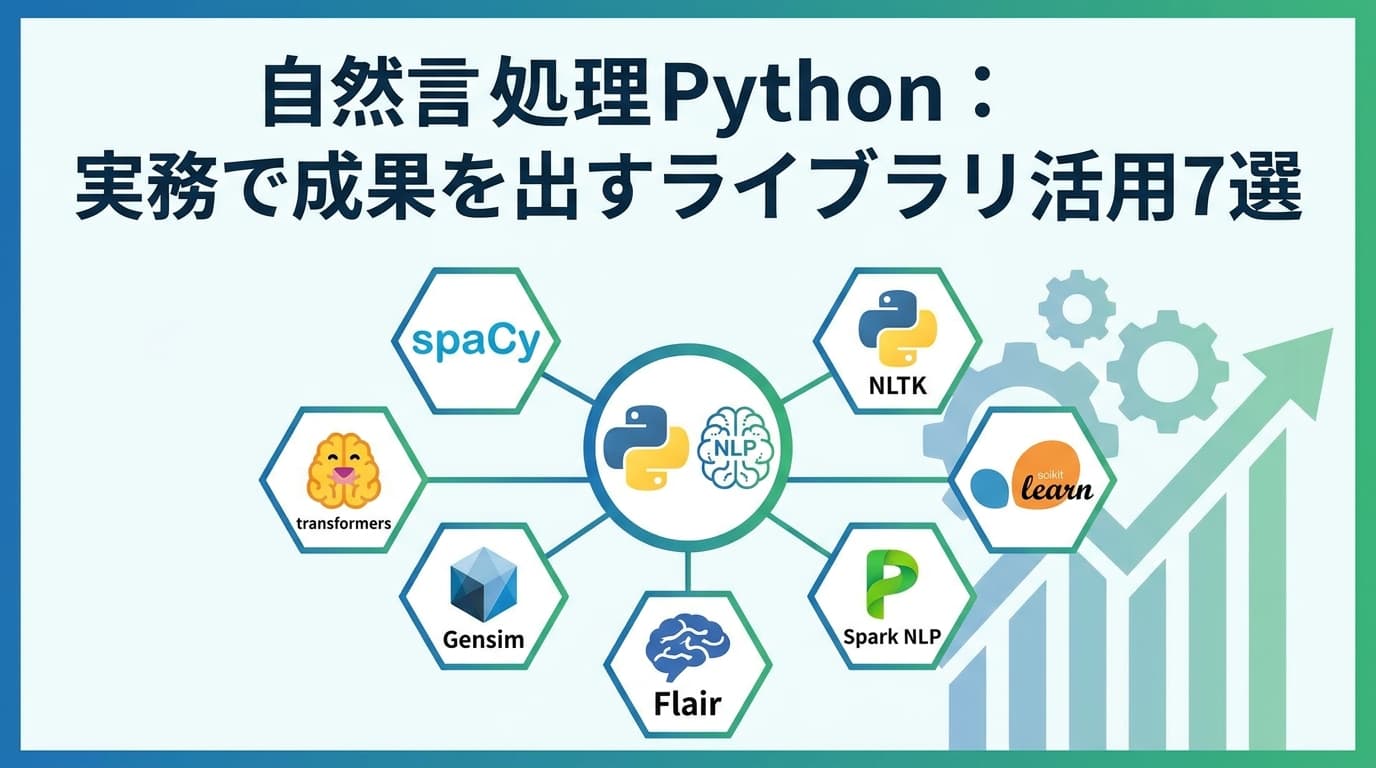
自然言語処理 Pythonを実務で活用するうえで結論から述べると、spaCy 3.8・Transformers v5・GiNZA・SudachiPy・Gensim・scikit-learn・sentence-transformers の7ライブラリを目的別に使い分けるのが2026年時点の最適解です。形態素解析・構文解析・分類・埋め込み(RAG)まで、Pythonならコード数十行で実装できます。
本記事では以下が分かります。
- 2026年に押さえるべき主要ライブラリ7選と最新バージョン
- 処理速度・日本語対応・LLM連携で見極める選定基準
- Janomeによる形態素解析のサンプルコード
- 実運用で頻発するデータドリフト・セキュリティへの対策
自然言語処理 Pythonを実務に落とすための基本判断
自然言語処理 Pythonのプロジェクトを立ち上げる最初のステップは、目的に応じた適切なライブラリの選定です。Pythonは豊富なエコシステムを備えており、テキストの前処理から大規模言語モデル(LLM)の活用まで、幅広いタスクを効率的に処理できます。
ライブラリを選ぶ際の判断ポイントは、処理の規模と求める精度の2軸です。日本語の形態素解析にはMeCabやJanomeが適していますが、高度な文脈理解が必要な場合はTransformers v5など、LLMを扱うライブラリの導入を検討します。
現場で自然言語処理システムを運用する際の注意点として、計算リソースの厳密な管理が挙げられます。大規模なテキストデータを扱う場合、メモリ消費量の増大がシステム障害を引き起こすリスクがあります。そのため、初期段階からバッチ処理の導入やクラウド環境の活用など、スケーラビリティを考慮した設計が不可欠です。
要点を整理すると、まずは解決したい業務課題を明確にし、要件に合った適切なライブラリを選定して、スモールスタートで検証を始めることがプロジェクト成功の鍵となります。
データの品質管理と丁寧な前処理
自然言語処理 Pythonを活用したプロジェクトにおいて、実務で成果を出すための重要なポイントを整理します。ビジネスの現場では、単にコードを動かすだけでなく、目的に応じた適切なアプローチを選択することが求められます。
現場で運用する際の最大の注意点は、データの品質管理と前処理です。どれほど優れたアルゴリズムを用いても、入力されるテキストデータにノイズが多ければ正確な出力は得られません。表記揺れの統一や不要な記号の削除といった地道な前処理が、最終的な精度を大きく左右します。
具体的なクレンジング項目は次の3点です。
- 全角・半角の統一(NFKC正規化)
- HTMLタグ・絵文字・URLの除去
- 同義語辞書による表記揺れ吸収(例:「問合せ」「お問い合わせ」を統一)
要約タスクや議事録自動生成と組み合わせるなら、Pythonと連携できるAIツールの比較も参考になります。社内文書を要約するワークフローの作り方は 【2026年版】文章要約AIおすすめ無料ツール5選!Python連携で業務効率化 で整理しています。
自然言語処理の要点は、適切な技術の選定と、丁寧なデータ前処理の両輪を回すことにあります。この基盤をしっかりと整えることが、実務でのAI活用を成功させる鍵となります。
処理速度と精度のバランスを見極める
ビジネスの現場で自然言語処理 AIを活用する際、3つ目の重要なポイントとなるのが、目的を見据えた適切なライブラリの選定と安定した運用環境の構築です。要件に対してオーバースペックな技術を採用すると、開発コストや維持費が膨らむ原因になります。
ライブラリ選定と環境構築の基準
Pythonには、spaCyやNLTK、Transformersなど、用途に応じた多様なライブラリが存在します。比較検討する際の判断ポイントは、処理速度と精度のバランスです。たとえばリアルタイムなチャットボット開発であれば応答速度に優れる軽量なモデルを、契約書の詳細な意味解析であれば処理に時間がかかっても高精度なモデルを採用するなど、実務の課題に合わせた見極めが求められます。
2026年時点で押さえておきたい主要バージョンは次の通りです。
- spaCy 3.8.14(2026年3月リリース):Python 3.14対応、
Language.memory_zone()で長時間サービスのメモリ肥大を抑制 - Transformers v5(2026年5月リリース):PyTorch一本化、Fast/Slowトークナイザの統合、Gemma 4・Mistral 4などの新モデル群を追加
- GiNZA v5.1:SudachiPyベース、
ja_ginza_electraでTransformerベースの高精度解析が可能
現場で運用する際のリスク管理
実際に自然言語処理 AIのシステムを現場で運用する際の注意点として、データの品質管理とセキュリティ対策が挙げられます。入力されるテキストデータに個人情報や機密情報が含まれる場合、適切な匿名化処理が不可欠です。また、言語モデルは時間の経過とともに新しい専門用語やトレンドに対応できなくなるため、定期的な再学習や辞書のアップデートを行う保守体制を整える必要があります。
このように、自然言語処理 Pythonを実務に定着させるためには、初期のライブラリ選定だけでなく、運用開始後の継続的なメンテナンスを見据えた設計を行うことが重要です。要点をしっかりと押さえ、現場の課題解決に直結するシステム構築を目指しましょう。
自然言語処理 Pythonライブラリおすすめ7選とサンプルコード
実務で自然言語処理 Pythonの環境を構築する際、4つ目のポイントとして重要になるのが、目的に応じた適切なツールの選定と基礎スキルの定着です。テキスト解析を効率化する手段は多数存在しますが、プロジェクトの要件に合わせて使い分ける判断が求められます。

目的に応じたライブラリの選定基準
自然言語処理 Pythonライブラリの選定では、処理速度、日本語対応の有無、そして環境構築の容易さが主な判断ポイントとなります。用途に応じた代表的なツール7選は以下の通りです。
| ライブラリ名 | 主な用途 | 日本語対応 | 2026年の最新動向と活用シーン |
|---|---|---|---|
| MeCab | 形態素解析 | ◯ | C++実装で処理速度が非常に速く、大規模テキストデータの前処理に最適 |
| Janome | 形態素解析 | ◯ | Pythonのみで完結し pip install janome のみで導入可能。学習・PoC向き |
| SudachiPy | 形態素解析 | ◯ | A/B/C の3分割単位 + 同義語辞書で表記揺れに強く、業務文書に最適 |
| spaCy 3.8 | 構文解析・固有表現抽出 | ◯(GiNZAで対応) | 実運用向け設計でパイプライン処理が効率的。Python 3.14 対応済み |
| Gensim | トピックモデル・分散表現 | △(事前処理が必要) | Word2Vec・LDAで単語のベクトル化や文書類似度計算に活用 |
| scikit-learn | 機械学習・特徴量抽出 | △(事前処理が必要) | TF-IDFによる重要単語抽出やテキスト分類モデル構築の定番 |
| Transformers v5 | LLM・埋め込み・分類 | ◯ | BERT・Gemma 4・Mistral 4 などをロードでき、Hubに75万以上のチェックポイント |
加えて、LLM時代の埋め込み・検索タスクでは sentence-transformers(all-MiniLM-L6-v2 などをラップし、文ベクトルとコサイン類似度を数行で計算)と、ベクトル検索ライブラリの FAISS、オーケストレーションの LangChain を組み合わせる構成が2026年の事実上の標準です。社内ドキュメントを検索する仕組み(RAG)を本番運用したい場合は、【2026年版】セキュアRAG実装ガイド|AWS Bedrock・Azure AI Search・Vertex AIの3クラウド比較 も合わせて確認してください。
実用的なサンプルコード:Janomeを使った形態素解析
実際に自然言語処理 Pythonを始める場合、環境構築が簡単なJanomeによる形態素解析がおすすめです。以下のサンプルコードは、テキストを単語に分割し、品詞を取得する基本的な流れを示しています。
from janome.tokenizer import Tokenizer
# トークナイザーの初期化
t = Tokenizer()
text = "Pythonで自然言語処理を実装します。"
# 形態素解析の実行
for token in t.tokenize(text):
print(f"単語: {token.surface} \t 品詞: {token.part_of_speech}")
現場運用の注意点とスキルの定着
これらのツールを社内運用に組み込む際の注意点として、バージョン管理や依存関係の複雑化が挙げられます。特にTransformers v5のようなメジャーアップデートでは旧APIが整理されるため、本番環境での定期的な動作検証を徹底する必要があります。
また、現場で要点を押さえて自走できるスキルを身につけるためには、理論の理解だけでなく手を動かす実践が不可欠です。基礎事項を整理した後は、「自然言語処理 100本ノック」のような実践的な課題集を活用することをおすすめします。データの前処理からモデル構築までのフローを反復練習することで、実務に直結するノウハウを効率的に定着させることができます。
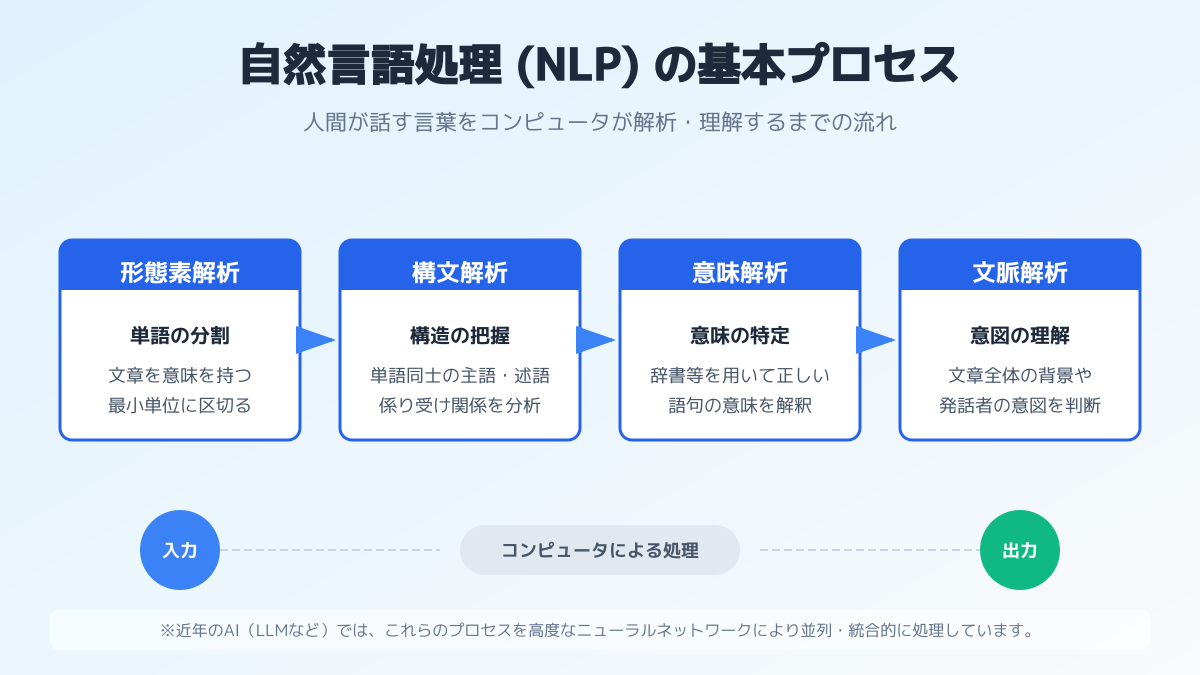
日本語特有のテキスト処理とライブラリ選定

自然言語処理 Pythonの実務で重要なポイントとなるのが、日本語特有のテキスト処理とライブラリの選定です。英語などの言語とは異なり、日本語には単語と単語の間にスペースを置く分かち書きの習慣がありません。そのため、まずは文章を意味のある最小単位に分割する「形態素解析」を行う必要があります。
日本語の自然言語処理 Pythonを導入する際の判断ポイントは、プロジェクトの目的に合った形態素解析ライブラリを適切に選ぶことです。
- MeCab:大規模データの処理速度を重視するケース
- Janome:環境構築の手間を省き手軽に始めたい、教育・検証フェーズ
- SudachiPy:表記揺れを吸収して高度な分析を行うビジネス文書
現場で運用する際の注意点として、辞書の継続的なメンテナンスが挙げられます。ビジネス現場の社内文書や特定の業界で使われる専門用語、あるいはSNS上の新語などは、標準の辞書には登録されていません。そのため、ユーザー辞書を定期的に更新し、解析精度を保つ運用フローをあらかじめ設計しておく必要があります。SudachiPyであれば sudachi.json の userDict に追加辞書バイナリのパスを書き、sudachipy ubuild でビルドすれば本番環境にデプロイできます。
初期段階で対象データの特性を正確に把握し、最適なツール選定と辞書管理の体制を整えることが、精度の高いシステムを構築する鍵となります。導入して終わりではなく、継続的なチューニングを前提とした設計を心がけてください。
LLM時代の自然言語処理 AI:RAG・埋め込み・マルチモーダル
2026年の自然言語処理 AIでは、従来の形態素解析・分類だけでなく、LLMと組み合わせた検索・要約・マルチモーダル処理が実務の主戦場です。
判断軸はシンプルで、「テキストを構造化して可視化したい」なら従来NLPライブラリ、「自然な対話・要約・社内ドキュメント検索」ならLLM + 埋め込み + ベクトル検索 に役割を分けます。
- sentence-transformers:文章ベクトルを生成し、Pythonコード10行程度で意味検索を実装可能
- LangChain / LlamaIndex:LLMとベクトルストアをつなぐオーケストレーション
- FAISS / pgvector / Azure AI Search:ベクトルの保管と類似度検索
- Transformers v5:埋め込みモデルや分類モデルのファインチューニング
テキスト + 画像 + 音声をまとめて扱う流れも加速しています。マルチモーダルAIの基礎は 【2026年版】マルチモーダルAIとは?画像・音声・テキスト統合の仕組みとDX活用事例5選 でモデル別の特徴と業界事例を整理しています。
要点は、自然言語処理 Pythonを単独で完結させず、LLM・ベクトルDB・マルチモーダルモデルと組み合わせて「業務課題の答え」を出す構成にすることです。
導入プロセスの全体設計と運用保守
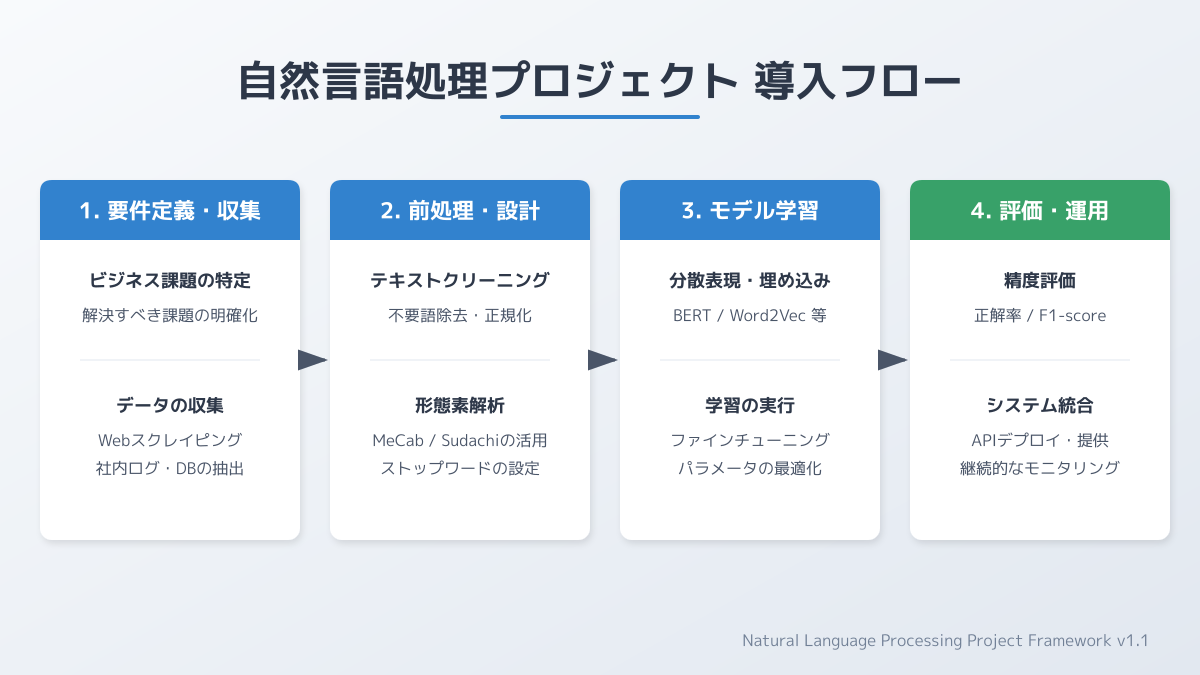
ビジネス現場で自然言語処理 Pythonを活用したプロジェクトを成功させるには、技術的な実装だけでなく、導入プロセスの全体設計が重要です。ここでは、実務への適用に向けた基本事項と運用時の注意点を整理します。
導入時の判断ポイントと基本事項
自然言語処理の導入を進めるにあたり、最も重要な判断ポイントは解決すべき業務課題の明確化です。例えば、社内問い合わせ対応の自動化や顧客アンケートの感情分析など、目的によって必要なアプローチは異なります。Transformers v5やspaCy 3.8など強力なライブラリが揃っていますが、要件に対して過剰なモデルを採用すると、計算コストや推論時間が増大します。費用対効果と必要な精度のバランスを見極めることが不可欠です。
現場運用における注意点
モデルを本番環境で運用する際は、入力データの品質管理が大きな課題となります。業務特有の表記揺れや専門用語の混在は、出力精度を著しく低下させます。そのため、前処理パイプラインを整備し、継続的なデータクレンジングの仕組みを構築する必要があります。
また、一度構築したシステムを放置せず、定期的に推論結果を評価して再学習を行う運用フローの確立も求められます。Pythonの豊富なエコシステムと監視ツールを組み合わせることで、精度の劣化を早期に検知できます。目的の定義から運用保守までを一貫して設計することが、プロジェクトを定着させる鍵となります。
運用時の注意点とデータドリフト対策
自然言語処理 Pythonを実装し、社内システムへ組み込んだ後は、継続的な運用と監視のフェーズに入ります。開発環境で高い精度を出したモデルであっても、実際のビジネス現場で長期間運用すると、入力されるテキストの傾向が変化し、徐々に精度が低下するデータドリフトが発生します。
実運用における重要な判断ポイントは、精度の低下を検知した際に「モデルの再学習を行うか」「プロンプトやルールの調整で対応するか」を見極めることです。顧客からの問い合わせ内容のトレンド変化や、社内用語のアップデートなど、ビジネス環境の変化に合わせて柔軟にシステムを適応させる必要があります。
また、現場で運用する際の最大の注意点は、セキュリティとデータガバナンスの徹底です。顧客の個人情報や企業の機密情報を含むテキストを扱う場合、Pythonの正規表現や専用ライブラリを用いて、事前に機密情報をマスキングする処理をパイプラインに組み込むことが不可欠です。外部のAPIやLLMと連携させる際は、データ送信の範囲を最小限に留める設計が求められます。
自然言語処理 AIのプロジェクトを成功させる要点は、高度なアルゴリズムの導入だけではありません。運用時のデータ変化を監視し、安全かつ継続的に改善を回す仕組みづくりを初期段階から設計しておくことが重要です。
まとめ
本記事では、自然言語処理 Pythonでビジネス現場の成果を出すためのライブラリ7選と実践ノウハウを2026年最新版で解説しました。プロジェクト成功の鍵は、まず解決すべき業務課題を明確にし、その目的に合った適切なライブラリを選定することにあります。MeCab・Janome・SudachiPy・spaCy 3.8・Gensim・scikit-learn・Transformers v5の特性を、処理速度・日本語対応・LLM連携の3軸で見極めることが重要です。
さらに、データの前処理、特に日本語の形態素解析は分析精度を大きく左右する基本事項です。LLM時代にはsentence-transformersやLangChainを組み合わせたRAG構成も標準化しており、システム導入後の継続的な運用・監視、データドリフトへの対応、セキュリティとデータガバナンスの徹底が、長期的な成功には不可欠です。これらの要点を押さえ、実践的なスキルを習得することで、自然言語処理 Pythonは強力なビジネスツールとなります。
自然言語処理 Pythonを運用に落とし込むときは、本文で整理した判断基準を順に確認してください。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。