【2026年版】Difyワークフローの作り方|ノーコードでAI業務自動化を自作する3ステップ
Difyワークフローは、LLM・条件分岐・ナレッジ検索・Agentノードを組み合わせて業務を自動化するノーコード基盤です。本記事では問い合わせ分類を題材に、設計→ノード配置→エラー対策の3ステップで自作する手順と、チャットフローとの使い分けを2026年最新版で整理します。

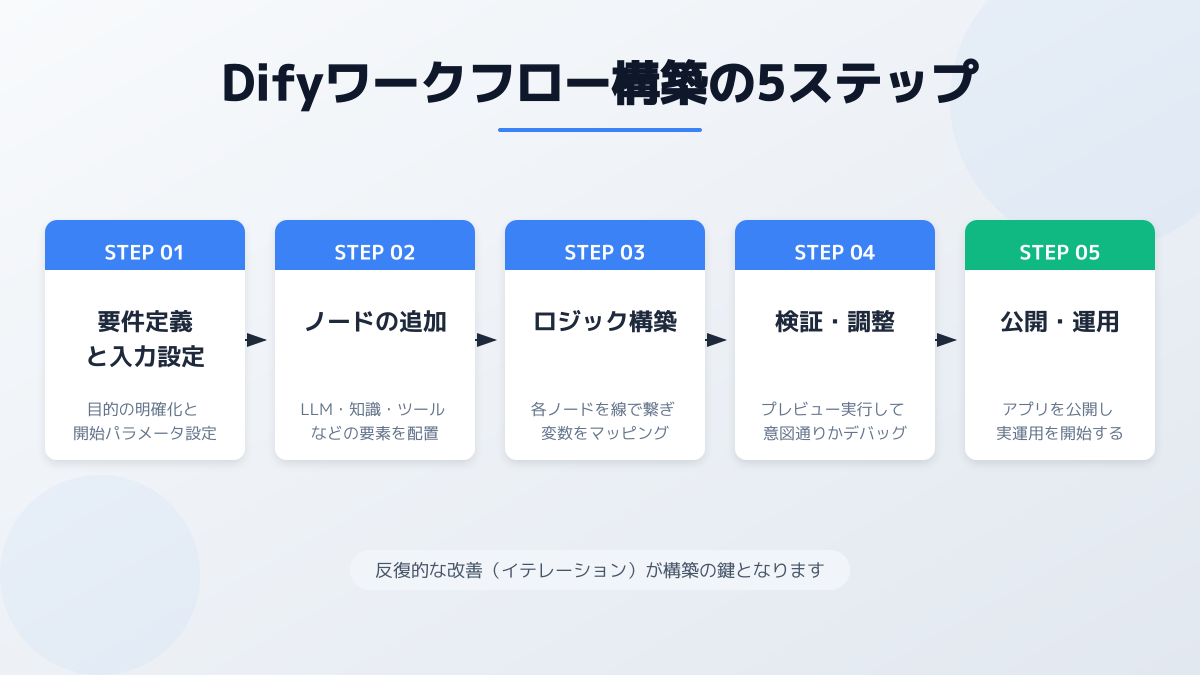
Difyワークフローの作り方は、自動化したい業務の細分化 → Difyキャンバス上でのノード配置 → エラー設計とテストの3ステップで進めます。LLMノード・条件分岐・ナレッジ検索・Agentノードといった部品を組み合わせるだけで、ノーコードでもAI業務自動化システムを自作できる構造です。
本記事では2026年時点の最新仕様(v1.0系のAgentノード/HTTPベースのMCP連携など)を踏まえ、カスタマーサポートの問い合わせ分類を題材に具体的な作り方を解説します。チャットフローとの違い、ランニングコストの考え方、現場運用のためのフェイルセーフ設計までをまとめて押さえられる構成です。
Difyワークフローとチャットフローの違いを最初に整理する
Difyのアプリには「ワークフロー」と「チャットフロー」の2種類があり、入口を間違えると後戻りが大きくなります。最初に違いを把握してから作り始めることが、自作の最短ルートです。
| 項目 | ワークフロー | チャットフロー |
|---|---|---|
| 起動方法 | 1回限りの実行(バッチ・Webhook・スケジュール) | ユーザーの会話メッセージごとに毎回起動 |
| 会話メモリ | なし(毎回まっさら) | あり(直前のやり取りをLLMに引き継ぎ可) |
| 出力 | 任意(最終ノードで終了) | 回答ノードが必須 |
| 向いている用途 | 定型業務の自動化、データ処理、レポート生成 | ヘルプデスク、FAQボット、対話型アシスタント |
問い合わせメールの自動分類や月次レポート生成のように 「入力→処理→出力で完結する業務」はワークフロー が適切で、社内ヘルプデスクのように 「ユーザーが対話しながら答えを掘り下げる業務」はチャットフロー を選びます。同じUI上でノードを組むため学習コストは共通ですが、会話メモリの有無が設計を大きく変えるため、最初の選択を間違えないようにします。
ステップ1:自動化する業務の細分化と事前設計
ワークフローシステム自作の根幹となる最初のステップは、自動化したい業務プロセスの細分化と全体設計です。Difyの操作に入る前に、紙やワークフロー図でフローを可視化しておくと、後工程のノード配置が一直線で進みます。
業務プロセスをAIとルールに切り分ける
社内システムを成功させるには、既存の業務フローを「ルールベースで処理できるタスク」と「AIによる高度な推論が必要なタスク」に明確に切り分ける必要があります。何でもAIに任せるのではなく、確実性とランニングコストのバランスを見極めることが重要です。
Difyのワークフローでは、LLMノードだけでなく、条件分岐(IF/ELSE)・コード・ナレッジ検索・HTTPリクエスト・Agentなど多彩なノードを組み合わせます。「メール内容の分類はLLMに任せ、クレームに該当する場合のみ担当者へ即時通知する」といった判断ポイントを、フローチャートとして書き出しておきます。可視化の手順に迷う場合は、ワークフロー図の書き方と無料テンプレートが参考になります。
サンプル例:問い合わせ対応の自動化設計
本記事では「カスタマーサポートの問い合わせ分類と回答案作成」をサンプルとして設計します。この業務を細分化すると、以下のようになります。
- 入力: 顧客からのメール本文を受け取る
- 推論(AI): 内容を「料金」「解約」「技術サポート」「その他」に分類する
- 分岐(ルール): 「解約」なら担当者へ通知、「技術サポート」なら過去のFAQを検索
- 生成(AI): 検索結果をもとに回答案を作成する
- 例外: いずれにも当てはまらない場合は人間オペレーターへエスカレーション
このようにタスクを細分化することで、どの箇所に何のノードを配置すべきかが明確になります。導入前に生成AI導入費用と費用対効果を確認し、自動化による工数削減効果とAPI利用料のバランスを試算しておくと、稟議も通りやすくなります。
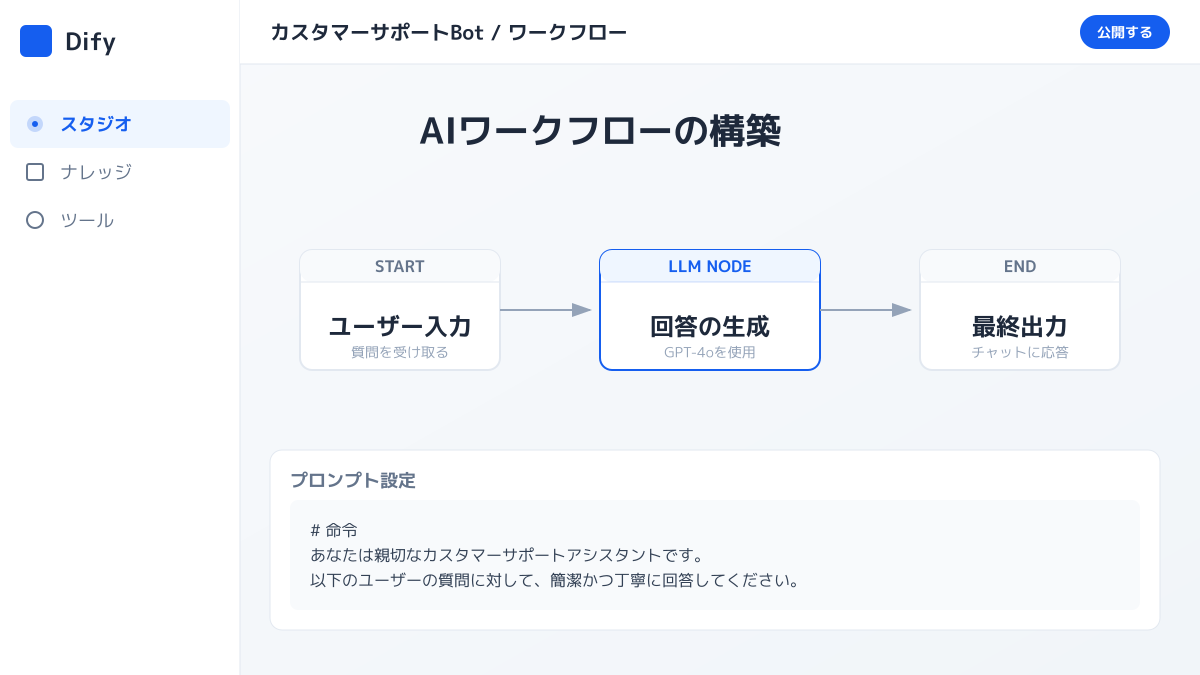
ステップ2:Difyでのノード配置とデータ連携(実践サンプル)
全体設計が完了したら、Difyのキャンバス上で実際に処理を組み立てていきます。ステップ1で設計したサンプル構成を基に、ノードの基本ルールと実装手順を解説します。
ノードの役割分担とプロンプト設計
Difyのワークフローは、開始ノードから終了ノードまでの間に役割の異なるブロックを視覚的に繋ぎ合わせて構築します。すべての処理を1つのLLMノードに詰め込むと、AIへの指示が複雑になりすぎて出力が不安定になります。情報の抽出や文章生成はLLMノード、特定キーワードによるルート変更は条件分岐ノード という役割分担が鉄則です。
Difyの公式ドキュメントでは、ノード接続のルールとして「ループ不可」「開始点と終点が必要」「同じノードから2つ以上のフローに同時分岐できない」が示されています。先に分岐パターンを設計しておけば、後から組み替える手戻りを防げます。
各LLMノードに設定するプロンプトの質もシステム精度を大きく左右します。AIに期待通りの役割を果たしてもらうためには、役割定義・入力データの形式・出力フォーマット(JSON指定など)を厳格に指示する必要があります。プロンプトの組み立てに不安がある場合は、プロンプトエンジニアリングの基礎を参考にしてください。
Agentノードで自律的なツール選択を任せる
2026年時点のDifyでは、ワークフロー内にAgentノードを配置できます。Agentノードは指定したツール群(Web検索、社内API、ナレッジ検索など)の中から、LLMがタスクに応じて呼び出す順番と引数を自律的に決定するブロックです。戦略は「ReAct」と「Function Calling」の2系統が用意されており、推論トレース・ツール出力・反復回数までログとして取得できます。
「分類は固定ルールで処理したいが、回答案の作成では複数ツールを使い分けたい」といったケースでは、ワークフローの後半だけAgentノードに委ねるハイブリッド構成が有効です。条件分岐で確実性を担保しつつ、創造的な部分だけAIの自律判断に任せることで、トークン消費とアウトプット品質のバランスを取れます。
外部データ連携(ナレッジベース・API・MCP)の活用

サンプルの「技術サポート」ルートのように、自社の過去のFAQを参照させる場合、LLM単体の知識では対応できません。ここで活躍するのが、ナレッジ検索(RAG)・HTTPリクエスト・MCP連携の3系統です。
Difyのナレッジ機能を使えば、PDFや社内ドキュメントを取り込んで「知識検索ノード」としてワークフローに組み込めます。マルチモーダル取り込みにも対応しており、画像と本文を同時に検索対象にできるようになりました。社内マニュアルなど正確性が求められる情報を連携させることで、ハルシネーション(AIの誤答)を抑え込めます。具体的なデータ準備の進め方は、社内データ連携による生成AI活用を参照してください。
外部のSaaSや基幹システムを呼び出す場合は、HTTPリクエストノードでREST APIを直接叩くか、Marketplaceから対応プラグインを導入します。2026年に入ってからはHTTPベースのMCPサーバー(プロトコル 2025-03-26)に標準対応し、Difyを MCPクライアント にも MCPサーバー にもできるようになりました。社内に複数の生成AI基盤を持つ企業では、Dify側で組んだワークフローを他のAIエージェントから呼び出す構成が現実解です。
連携するデータは事前に機密レベルで分類し、権限設定を誤らないよう管理することが不可欠です。機密性の高いシステムでは、LLMローカル環境の構築手順を併用してオンプレミスにモデルを置く選択肢も検討します。
ステップ3:テスト実行・エラーハンドリングと現場への定着
ノードを繋いでシステムが完成したように見えても、すぐに実戦投入してはいけません。Difyワークフローの作り方の最終ステップは、エラーハンドリング(例外処理)の組み込みとテスト実行です。「想定外の入力が来たときに止まらない構造」になって初めて、業務システムとして使い物になります。
予期せぬ出力へのフェイルセーフ設計
LLMは確率的にテキストを生成するため、想定外のフォーマットで回答を出したり、知識検索で該当情報が見つからなかったりするケースが必ず発生します。後続ノードがデータを読み取れずシステム全体が停止するのを防ぐ仕組みが必要です。
サンプルの問い合わせ分類ノードで、AIが「料金」「解約」のどれにも当てはまらないと判断した場合の代替ルートを必ず作ります。「その他(人間の確認が必要)」という条件分岐を設け、Slackなどのチャットツールへ担当者宛にアラートを飛ばす フェイルセーフ が、実務で使えるシステムにする要点です。LLMノード単体でも、エラー処理タブで「失敗時に既定値を返す」「フォールバック先のノードに切り替える」といった挙動を設定できます。エラー対策の前段にあたるプロンプト設計の改善は、ハルシネーションの原因と対策も参考にしてください。
Human-in-the-Loopで承認フローを挟む
2026年のDifyでは、ワークフローの途中で人間の承認を待つHuman-in-the-Loopが利用できます。たとえば「LLMが下書きした顧客向け返信メールを、必ず管理者が確認してから送信する」「金額が一定額を超える稟議だけ手動承認に切り替える」といった、機密性・金額・コンプライアンスに関わる処理を半自動化したいときに有効です。完全自動化を目指すと運用上のリスクが高まる業務では、最初から承認チェックポイントを設計に組み込むのが安全です。
エラー時の代替ルートと継続的改善
ワークフローを社内に公開する前に、極端な入力値やイレギュラーなデータを用いてテスト実行を行います。Difyのデバッグ画面では各ノードの入出力JSONとトークン消費量をその場で確認できるため、コスト見積もりとプロンプト調整を同時に進められます。
現場で運用を開始した後も、エラーログを定期的に確認する体制を整えましょう。効果的なワークフロー構築は、一度作って終わりではありません。実際の運用データに基づいてプロンプトの微調整やノード構成の変更を行い、継続的にシステムを磨き上げることが、業務自動化を定着させる最大の秘訣です。広範な自動化ツールの選定で迷う場合は、失敗しない業務自動化ツールの選び方も役立ちます。
よくある質問(FAQ)
Q. Difyワークフロー作成にプログラミング知識は必要ですか?
基本的には不要です。Difyはノーコードプラットフォームであり、画面上でノードをドラッグ&ドロップして繋ぐだけで直感的にAIワークフローを構築できます。ただし、外部APIの連携や複雑なJSONデータのパースを行う際には、基礎的なデータ構造の理解があるとスムーズです。
Q. ワークフローとチャットフローはどう使い分ければよいですか?
1回完結の処理(バッチ処理・問い合わせ自動分類・レポート自動生成など)はワークフロー、ユーザーが会話を続けながら答えを引き出す形(社内FAQボット・対話型アシスタントなど)はチャットフローを選びます。会話メモリが必要かどうかが分かれ目です。両者は同じノード群を使うため、用途が混在する場合はチャットフロー側からワークフローを呼び出す構成も可能です。
Q. 構築したワークフローのランニングコストはどのくらいですか?
Difyのクラウド版にはSandbox(無料・月200メッセージクレジット)、Professional(月59ドル・月5,000クレジット)、Team(月159ドル・月10,000クレジット)が用意されています。これに加え、背後で呼び出すLLM(OpenAIやAnthropicなど)のAPI利用料が別途かかります。コストを抑えたい場合はOSS版をDocker Composeで自前ホスティングする選択肢もあり、利用制限なしでLLM API料金とサーバー費だけで運用可能です。
Q. AIの回答が不正確な場合はどうすればいいですか?
AIが事実と異なる回答(ハルシネーション)をする場合、LLMノードに任せる推論の範囲が広すぎる可能性があります。自社のPDFやドキュメントをナレッジとして登録し、ナレッジ検索ノード経由で情報を参照させる仕組みに変更することで、回答の正確性を大きく改善できます。さらにAgentノードに切り替えて検索→推論→検証のループを回すと、根拠の明示性も高められます。
Q. Agentノードと通常のLLMノードはどう違いますか?
通常のLLMノードは「決まったプロンプトに対する応答」を1回返すだけですが、Agentノードは指定したツール群(Web検索・社内API・ナレッジ検索など)を LLM自身が必要に応じて呼び出しながら タスクを進めます。複数ツールの使い分けや多段推論が必要なタスクではAgentノード、出力フォーマットを厳密に固定したいタスクではLLMノードという使い分けが基本です。
まとめ
Difyを活用したAIワークフローの構築は、事前設計・ノード配置・テスト実行の3ステップで完成します。
まずは自動化したい業務を細分化し、AIとルールベースの処理を切り分ける全体設計を行います。次に、Difyのキャンバス上でLLMノード・条件分岐ノード・ナレッジ検索ノード、必要に応じてAgentノードを適切に配置し、ナレッジベースやAPI・MCPによる外部連携を組み込みます。最後に、AI特有の出力ブレに備えたフェイルセーフを設計し、Human-in-the-Loopで承認チェックポイントを挟んだうえでテストと継続改善を繰り返します。
これらのポイントを押さえることで、非エンジニアでも実用性の高いAI業務自動化システムを自作し、自社の生産性を高めていけるはずです。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。