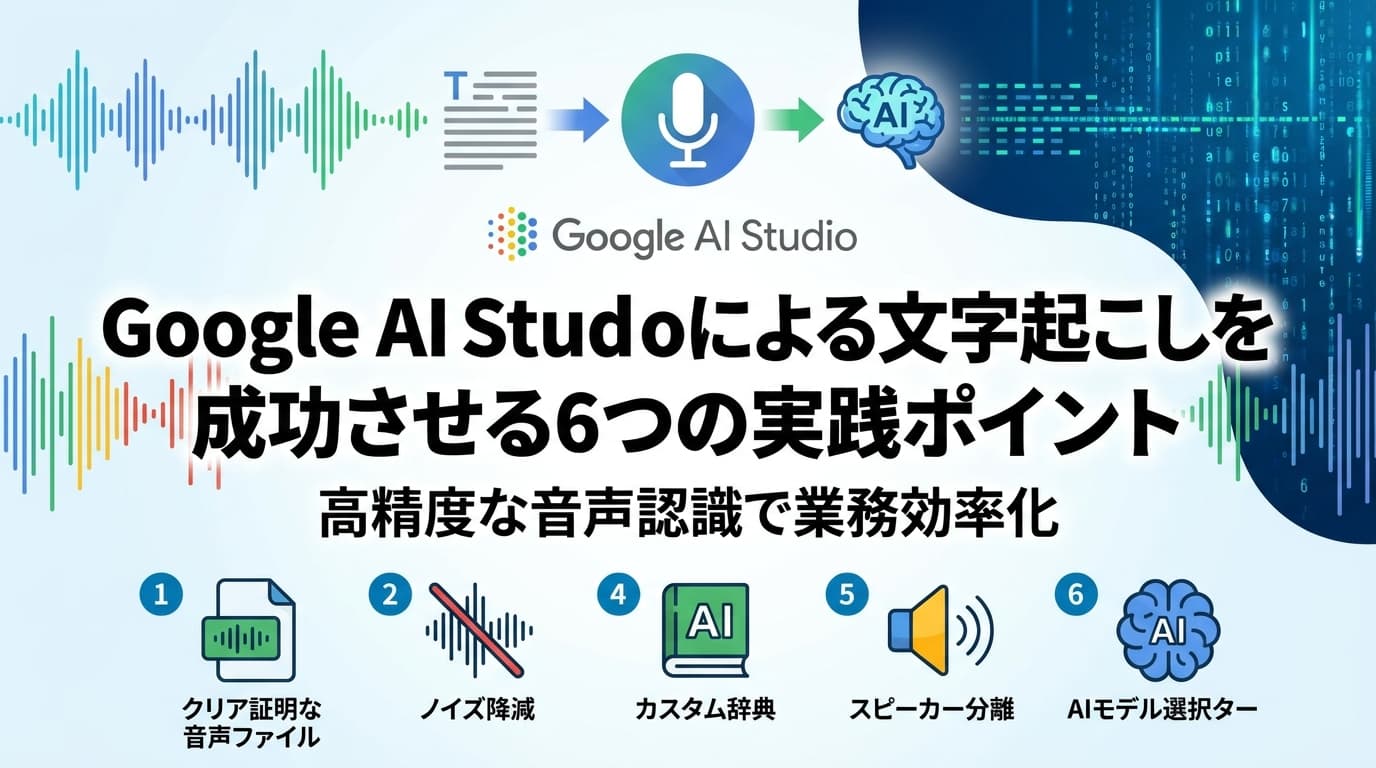
Google AI Studio 文字起こしの実践ガイド|Gemini 2.5 で無料9.5時間まで音声認識する6つのコツ【2026年版】
Google AI Studio と Gemini API を使った音声文字起こしを、2026年最新の Gemini 2.5 系仕様で実装するための6つの実践ポイントを開発者向けに解説。無料枠の9.5時間ルール・Files API・コスト最適化・Python サンプルまで網羅します。
「Google AI Studio で会議音声を文字起こししたいが、料金や精度、Gemini 2.5 系の最新仕様が分からない」という開発者・DX 担当者向けに、2026年5月時点で実務に使える6つの実践ポイントを解説します。結論として、Google AI Studio と Gemini 2.5 Flash を組み合わせれば、無料枠で最大 9.5時間 までの音声を一度に文字起こしでき、Python から Files API 経由で社内システムにも組み込めます。
本記事では、Google AI Studio による文字起こしを実務で成功させるための具体的なノウハウとして、以下の内容を扱います。
- Gemini 2.5 系(Pro / Flash / Flash-Lite)の特徴とモデル選定基準
- API 連携と Files API(20MB 超で必須)を使ったシステム設計
- 高精度化するプロンプトと録音時の運用ルール
- Python(
google-genaiSDK)による文字起こし実装サンプル - 2026年4月改定後の料金体系とコスト最適化
- 品質管理と機密データを扱う際のセキュリティ運用
Google AI Studio で文字起こしを行うための基本構造(Gemini 2.5 系)
Google AI Studio を活用した音声のテキスト化において、まず押さえるべきは Gemini 2.5 系モデルのマルチモーダル性能と無料枠の制約です。
Google AI Studio と Gemini 2.5 系モデルの基本構造
Google AI Studio は、開発者や DX 担当者が Gemini モデルをブラウザ上で検証・実行できるプラットフォームです。2026年5月時点で利用できる主要モデルは Gemini 2.5 Pro / Gemini 2.5 Flash / Gemini 2.5 Flash-Lite の3系統で、いずれもテキスト・画像・音声・動画を直接処理できる マルチモーダル機能 を備えています。そのため、外部の音声認識エンジンを挟むことなく、Google AI Studio から直接、高精度な文字起こしを実行できるのが大きな特徴です。

なお、2026年4月の改定で Google AI Studio の完全無料利用は Flash / Flash-Lite に限定 され、Gemini 2.5 Pro は基本的に従量課金(5 RPM の極小無料枠あり)に移行している点に注意が必要です(参考: Google AI for Developers — Pricing)。
導入を判断する際の具体化ポイント
自社の業務に Google AI Studio を組み込むべきか判断する際は、処理可能な音声長と文脈理解の深さが重要な指標となります。Gemini 2.5 Flash と 2.5 Pro はいずれも最大 1,000,000 トークン(約100万トークン) のコンテキストウィンドウを持ち、Gemini API のドキュメント上は 1リクエストあたり最大9.5時間の音声 を一度に読み込ませることが可能です。数時間に及ぶ長時間の会議音声やインタビュー録音も分割せずに処理でき、「指定した議事録のフォーマットに沿って要約する」「特定の発言者の意見を抽出する」といった高度な指示を同時に処理できる点が、専用文字起こしツールと比較した際の優位性です。
現場運用における注意点と要点の整理
一方で、現場で安全かつ正確に運用するためにはいくつか注意点があります。第一に、入力する音声データの品質です。どれほど優秀な LLM であっても、ノイズが多すぎる音声や極端に音量が小さいデータでは認識精度が低下します。会議の際は指向性マイクを使用するなど、物理的な録音環境の整備が不可欠です。
第二に、 プロンプトによる出力制御 です。音声を添付するだけでなく、「フィラー(えー、あの等)を削除する」「社内の専門用語は以下のリストを参照して変換する」といった具体的な指示を与えることで、テキスト化後の修正工数を大幅に削減できます。
業務効率化をさらに推進するためには、文字起こし後のデータをどう活用するかが鍵となります。マルチモーダル AI 全般の仕組みと活用事例を整理したい場合は、【2026年版】マルチモーダルAIとは?画像・音声・テキスト統合の仕組みとDX活用事例5選 も併せて確認し、自社に最適な AI 活用フローを構築してください。
API 連携を前提とした文字起こしシステムの設計

API 連携を前提としたシステム設計の基本
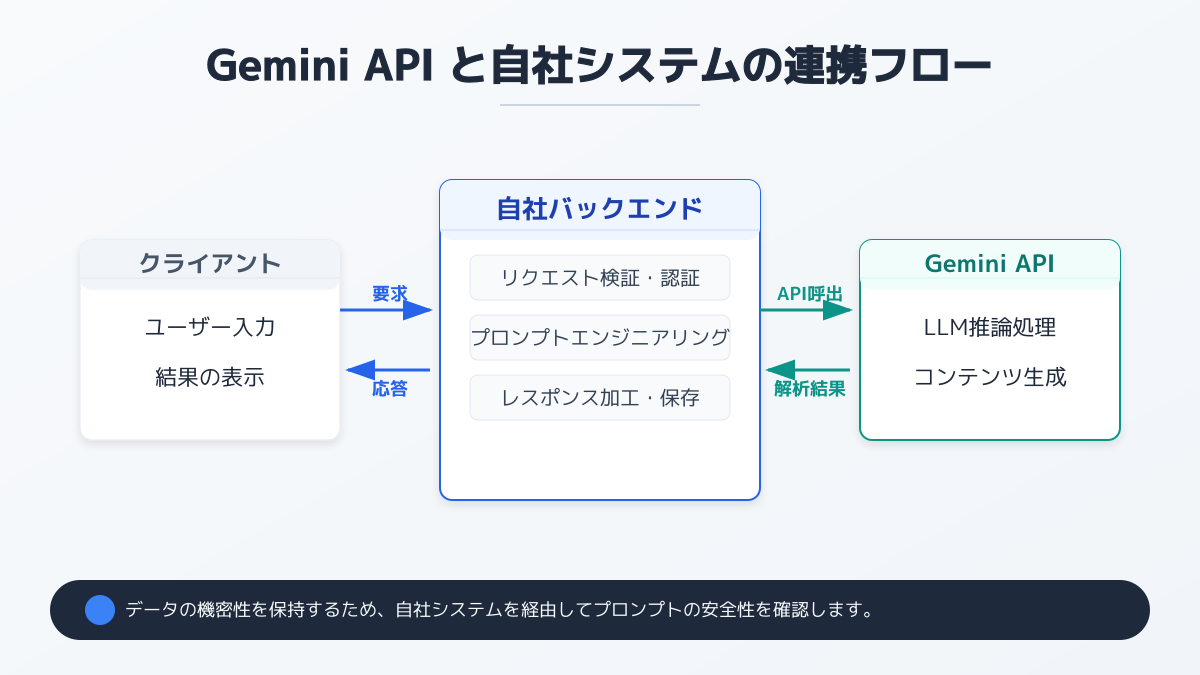
Google AI Studio の文字起こし機能を実務に導入する際は、Web 画面でのテストから一歩進め、社内システムとどのように連携させるかが重要なポイントとなります。Gemini API を活用すれば、議事録作成ツール、SFA(営業支援システム)、社内チャットツールとシームレスに接続し、業務フロー全体を自動化できます。
このアーキテクチャ設計では、音声データの受け渡し方法と、テキスト化されたデータの保存先を明確に定義することが基本事項です。たとえば、クラウドストレージに音声ファイルがアップロードされたことをトリガーにして、自動的に API を呼び出す仕組みを構築すれば、現場の担当者はファイル操作のみで文字起こし結果を得られます。
特に重要なのが Files API の使い分け です。Gemini API の仕様上、リクエスト全体(音声ファイル + プロンプト + システムインストラクション等)が 20MB を超える場合は Files API でのアップロードが必須 となり、それ以下なら inline_data として直接埋め込めます。1分の音声でも高ビットレートだと数 MB に達するため、業務利用では Files API を前提に設計しておくほうが安全です。Gemini API 自体の選定基準を整理したい場合は、【2026年版】企業向けAI APIおすすめ7選と料金比較|失敗しない選び方7つのポイント も参考になります。
現場運用における判断ポイントと注意点
システムを設計する際の具体的な判断ポイントは、 処理のリアルタイム性 と ファイルサイズ です。即時性が求められる Web 会議の字幕表示などには Live API のストリーミング処理を、数時間に及ぶ講演の録音データを一括でテキスト化する場合はバッチ処理を選択します。用途に合わせて最適な処理方式を見極めることが、コストとパフォーマンスの最適化につながります。
また、現場で運用する上で特に注意すべき点は、 セキュリティと API の制限 です。機密性の高い会議音声を扱う場合、データがどのように処理されるかプラットフォームのデータプライバシーポリシーを確認し、適切なアクセス制御を設ける必要があります。さらに、API には1分あたりのリクエスト回数や1回に送信できるファイルサイズの制限(クォータ)が存在します。エラー発生時の自動再試行処理(リトライ制御)や、長時間の音声をあらかじめ分割して送信する仕組みを組み込んでおくことが、システムを安定稼働させるための要点となります。
要点の整理と次のステップ
ここまでの要点を整理すると、Google AI Studio の文字起こしを業務で成功させるためには、要件に合わせたアーキテクチャ設計と、API 制限を考慮した堅牢なエラーハンドリングが不可欠です。これらをクリアすることで、単なるテキスト化にとどまらず、要約の自動生成やタスクの抽出までを一貫して行えるようになります。
文字起こしを実務に定着させるための運用ルール
Google AI Studio を活用した音声認識を実務に定着させるためには、ツールの導入だけでなく、現場の運用フローに合わせたルール設計が不可欠です。ここでは、実務に組み込むための基本事項や、現場での具体的な判断ポイントについて整理します。
具体的な使い方と高精度化するプロンプトのサンプル
Google AI Studio で文字起こしを行う際は、単に「文字起こしをして」と指示するのではなく、役割と出力形式を明確に指定することが重要です。音声ファイルをアップロードした後、以下のようなプロンプトを入力することで、後処理の手間を大幅に削減できます。
【議事録作成用のプロンプトサンプル】
あなたはプロの議事録作成アシスタントです。添付された音声データ(社内の定例会議)を読み込み、以下のフォーマットに従って文字起こしと要約を行ってください。
- 発言者ごとに段落を分けて、全文を書き起こしてください。その際、フィラー(えー、あの等)は削除してください。
- 会議の最後に、議論の要点と決定事項を3〜5項目の箇条書きでまとめてください。
- 次のアクションアイテム(誰が、いつまでに、何をするか)があれば、表形式で抽出してください。
このように指示することで、テキストの品質は大きく向上します。対応している音声ファイル形式(.wav・.mp3・.aac・.flac・.ogg 等)と1リクエストあたりの上限(9.5時間 / 20MB を超える場合は Files API)を事前に把握し、長時間の録音データは分割して処理する前処理手順をマニュアル化しておくことが推奨されます。
現場での判断ポイントと運用ルール
現場で Google AI Studio の文字起こしを活用する際、すべての音声データを一律に処理するのではなく、目的に応じた判断ポイントを設けることが業務効率化の鍵となります。
たとえば、社内ミーティングの議事録作成であれば、一言一句正確な書き起こしよりも、議論の流れと結論の要約が重視されます。一方、顧客との商談記録やユーザーインタビューの場合は、発言のニュアンスや詳細な文脈を逃さないよう、精緻な全文書き起こしが求められます。データの性質と最終的な用途に応じてプロンプトの指示内容を変える判断基準を社内で定めておく必要があります。
また、専門用語や社内略語が頻出する会議では、AI が誤認識を起こす可能性が高まります。「事前にプロンプト内で専門用語のリストを提示する」といった工夫を取り入れるかどうかも、重要な判断ポイントの1つです。
運用時の注意点と精度向上のコツ
実際の現場で運用する際の注意点として、最も気を配るべきはデータセキュリティとプライバシーの保護です。Google AI Studio で文字起こしを行う対象の音声データに、顧客の個人情報や未公開の機密情報が含まれる場合、社内のセキュリティガイドラインに厳密に準拠した取り扱いが必須となります。特に 無料枠(Free tier)で送信したデータは Google のモデル改善に利用される可能性がある ため、機密音声を扱う際は必ず有料の従量課金プラン(Paid tier)に切り替える運用を社内で徹底してください。
さらに、録音環境の品質も文字起こしの精度を左右する重要な要素です。マイクから遠い発言や、周囲の雑音が多い音声データは、どれほど高性能な LLM を用いても正確な認識が困難です。「会議中は発言者の近くにマイクを配置する」「複数人が同時に話さない」といった、録音時の物理的なルールづくりも並行して行う必要があります。
これらの要点を押さえ、システムの特性と人間の運用カバーを組み合わせることで、Google AI Studio を活用した文字起こし業務は、組織の生産性を飛躍的に高める強力な手段となります。
Gemini API を用いた文字起こし実装のサンプルコード
Google AI Studio で検証したプロンプトやモデルの設定は、Gemini API を経由することで自社システムに直接組み込むことが可能です。ここでは、API 連携を前提とした実践的な実装例として、Python を用いた文字起こしのサンプルコードを紹介します。
Python による音声の文字起こしサンプル(Gemini 2.5 Flash)
以下のコードは、Google GenAI SDK(google-genai)を使用して、音声ファイルを Gemini 2.5 Flash モデルに送信し、文字起こしを実行する基本的なサンプルです。テスト環境で精度が確認できた後、この API 連携ロジックを社内の議事録ツールやチャットツール(Slack / Microsoft Teams など)のバックエンドに組み込んで活用します。
import os
from google import genai
# API キーの設定(環境変数から取得)
client = genai.Client(api_key=os.environ.get("GEMINI_API_KEY"))
def transcribe_audio(file_path: str) -> str:
# 音声ファイルのアップロード(20MB 超の場合は Files API が必須)
print("音声ファイルをアップロード中...")
audio_file = client.files.upload(file=file_path)
# プロンプトの定義
prompt = """
添付された音声データの文字起こしを行ってください。
フィラー(えー、あのなど)を取り除き、自然な日本語に整えてください。
発言者が複数いる場合は、Speaker A / Speaker B のように区別してください。
"""
# Gemini 2.5 Flash モデルでコンテンツを生成
print("文字起こしを実行中...")
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[audio_file, prompt],
)
return response.text
if __name__ == "__main__":
audio_path = "sample_meeting.mp3"
result = transcribe_audio(audio_path)
print("\n【文字起こし結果】\n")
print(result)
精度を優先する場合は model="gemini-2.5-pro" に切り替えるだけでモデルを差し替えできます。逆に大量バッチでコストを抑えたい場合は gemini-2.5-flash-lite も有効な選択肢です。
現場で運用する際のエラーハンドリングと注意点
実際の現場でこのコードを運用する際は、システムを安定稼働させるための追加実装が必要になります。
第一に、 エラーハンドリングの実装 です。API にはリクエスト数の上限(レート制限)が設けられているため、制限に達した場合や一時的なネットワークエラーが発生した際に、システム側で自動的に再試行(リトライ)を行うロジックを組み込むことが不可欠です。指数バックオフを用いた tenacity などのライブラリ併用が定番です。
第二に、機密データの取り扱いです。経営会議や未公開のプロジェクトに関する音声データを送信する前に、有料の Paid tier で API キーを発行し、シークレット管理サービス(Google Secret Manager・AWS Secrets Manager など)で API キーを厳格に管理してください。
最後に、処理方式の選択です。長時間の会議音声を取り扱う場合は、API のタイムアウトや9.5時間上限を考慮し、音声を適切な長さに分割して送信する「バッチ処理」の仕組みを検討してください。自社の業務要件に合わせて最適なアーキテクチャを選択することが重要です。
Gemini API の料金体系とコスト最適化(2026年5月時点)
Google AI Studio の文字起こしを実務で導入する際、継続的な運用を支える重要な要素がコスト管理です。ここでは、ポイント5として「料金体系の理解とコスト最適化」の観点から、2026年5月時点の最新仕様を整理します。
Gemini API の料金体系と基本事項
Google AI Studio 経由で Gemini API を利用する場合、主に「無料枠(Free tier)」と「従量課金(Paid tier / Pay-as-you-go)」の2つの選択肢があります。検証段階や小規模な利用であれば無料枠で十分ですが、商用利用や大規模な処理を行う場合は Paid tier への移行が必要です。
文字起こしタスクにおける料金体系とコスト最適化の比較は以下のとおりです(料金は2026年5月時点・1Mトークンあたり)。
| プラン・モデル | テキスト入力 | 音声入力 | テキスト出力 | 適用シーン |
|---|---|---|---|---|
| 無料枠(Free tier・Flash 系のみ) | 無料 | 無料 | 無料 | 検証・プロトタイプ。音声・動画は合計9.5時間まで/プロンプトが学習に利用される可能性あり |
| Gemini 2.5 Flash-Lite | $0.10 | $0.30 | $0.40 | 大量バッチで最安。短い会議音声を高頻度に処理したいケース |
| Gemini 2.5 Flash | $0.30 | $1.00 | $2.50 | 標準モデル。日常的な議事録作成や商談ログのテキスト化に最適 |
| Gemini 2.5 Pro | $1.25 | $1.25〜 | $10.00 | 専門用語が多い会議、長尺・複雑な文脈の要約まで一気通貫で行う場合 |
出典: Gemini Developer API Pricing(2026年5月時点)
コスト最適化の判断ポイントと現場での運用注意点
現場で文字起こしを運用する際は、目的に応じて適切なモデルとプランを選択することがコスト最適化の鍵となります。まず処理速度と低コストを両立する Gemini 2.5 Flash を標準として検証し、精度に課題がある場合のみ Gemini 2.5 Pro へ切り替えるアプローチが有効です。短時間・大量処理であれば Gemini 2.5 Flash-Lite も有力な選択肢になります。
また、現場運用における注意点として、無料枠の制限事項を正しく理解する必要があります。前述のとおり2026年4月以降、Google AI Studio の 完全無料利用は Flash / Flash-Lite に限定 され、Gemini 2.5 Pro は基本的に従量課金です。さらに無料枠では、入力した音声データやプロンプトが Google の製品改善のために利用される仕様となっています。顧客との商談音声や経営会議の録音など機密性の高いデータを扱う場合は、必ず Paid tier を設定し、データプライバシーを確保しなければなりません。
API キーの管理も重要です。誤って API キーが外部に漏洩すると、予期せぬ高額請求が発生するリスクがあります。Google Cloud のコンソール側で利用上限(クォータ)のアラート設定を事前に行い、利用状況を定期的にモニタリングする体制を整えてください。Gemini ブランドの有料プラン全体像を整理したい場合は、【2026年版】Gemini有料プランの違いを徹底比較!Google AI Plus/Pro/Ultraと法人向けの選び方 も参考になります。
文字起こしの品質管理と安全な運用体制の構築
Google AI Studio を活用した音声認識システムを実務に定着させるための第6のポイントとして、出力品質の継続的な管理と、現場での安全な運用体制の構築について解説します。
品質評価と運用ルールの基本事項
Google AI Studio で文字起こしを実行した際、録音環境のノイズや発言者の滑舌、業界特有の専門用語の有無によって、テキストの認識精度は常に変動します。AI の出力を完全な完成品として扱うのではなく、人間による最終確認(ヒューマン・イン・ザ・ループ)を前提とした業務フローを設計することが基本事項となります。議事録の作成や商談記録の要約など、情報の正確性が問われる業務においては、どの段階で誰がファクトチェックを行うのか、あらかじめ責任の所在を明確にしておく必要があります。
現場導入における判断ポイント
実際の現場へ導入する際の重要な判断ポイントは、対象となる音声データの機密レベルと、業務上許容できるエラー率のバランスを見極めることです。たとえば、社内の定例ミーティングであれば、多少の誤認識は許容して即時性を優先する運用が適しています。一方で、外部公開用のインタビュー記事や、コンプライアンスに関わる顧客対応記録では、プロンプトに自社固有の用語集を組み込んで精度を底上げするとともに、事後の厳密な校正プロセスが不可欠です。用途に応じて求める品質の基準を柔軟に切り替えることが、システムの費用対効果を最大化する鍵となります。
安全な運用のための注意点と要点の整理
現場で運用する際の最大の注意点は、情報セキュリティおよびデータプライバシーの確実な保護です。Google AI Studio で文字起こしを行う対象の音声データに、顧客の個人情報や未公開の機密情報が含まれる場合、社内のセキュリティガイドラインに厳密に準拠した取り扱いが必須となります。必要に応じて、事前に機密部分をマスキングする運用ルールを設けるか、API のデータ利用規約を確認し、入力データがモデルの学習に利用されないよう Paid tier への切り替えやオプトアウト設定を行ってください。
これらの要点として、 用途に応じた品質基準の明確化 と セキュリティポリシーの徹底 の2つを押さえることが重要です。システムの性能向上だけに頼るのではなく、人間と AI が安全かつ効率的に協働できる運用ルールを現場レベルで整備することで、組織全体の生産性を継続的に高められます。
まとめ|Google AI Studio 文字起こしを成功させる6つの実践ポイント
本記事では、Google AI Studio と Gemini API(2026年5月時点の Gemini 2.5 系)を活用した高精度な音声の文字起こしを実務に導入するための、6つの実践ポイントを解説しました。
- 基本構造の理解: Gemini 2.5 系のマルチモーダル性能と1Mトークン・9.5時間の音声上限を活かす設計を行う
- API 連携とシステム設計: 20MB 超では Files API を必須とし、社内システムと接続するアーキテクチャを描く
- 運用ルールと使い方: 役割と出力形式を明示したプロンプト+録音時の物理ルールで認識精度を底上げする
- 実装のサンプルコード:
google-genaiSDK で Gemini 2.5 Flash を呼び出し、リトライ・キー管理を組み合わせる - コスト管理と最適化: 2026年4月の改定を踏まえ、Flash 系 Paid tier をベースに Pro へ段階的にエスカレーションする
- 品質評価とセキュリティ: ヒューマン・イン・ザ・ループと Paid tier 切替えで信頼性を担保する
これらの実践ポイントを押さえることで、Google AI Studio を活用した文字起こしは、組織の生産性を飛躍的に高める強力なツールとなります。本記事のノウハウや具体的な使い方を参考に、自社の AI 活用を推進してください。Google AI Studio の文字起こしを運用に落とし込む際は、本文で整理した判断基準を順に確認しながら進めることをおすすめします。

その作業、AIで自動化できます!
ClaudeやAIエージェントを活用し、複雑な会計ソフトの入力・図面や画像を用いた書類の整理・プロジェクト管理まで、あらゆる業務をAIエージェントが遂行。社内で運用できる状態までご支援します。